













談談你對Kafka副本Leader選舉原理的理解?
一位7年工作經驗的小伙伴,面試被問到這樣一道題,說:”談談你對Kafka副本Leader選舉原理的理解“。當時,他想,這Kafka用的不就是Zookeeper 的選舉嗎?難道Kafka又自己搞了一套。沒錯,這回Kafka自己造了一個輪子。
那么今天,我給大家來聊一聊我對Kafka副本Leader選舉原理的理解。
1、選舉原理
確實Kafka早期的版本就是直接用Zookeeper來完成選舉的。利用了Zookeeper的Watch機制;節點不允許重復寫入以及臨時節點這些特性。這樣實現比較簡單,省事。但是也會存在一定的弊端。比如分區和副本數量過多,所有的副本都直接參與選舉的話,一旦某個出現節點的增減,就會造成大量的Watch事件被觸發,ZooKeeper的就會負載過重,不堪重負。
新版本的Kafka中換了一種實現方式。不是所有的Repalica都參與Leader選舉,而是由其中的一個Broker統一來指揮,這個Broker的角色就叫做Controller控制器。
Kafka要先從所有Broker中選出唯一的一個Controller。
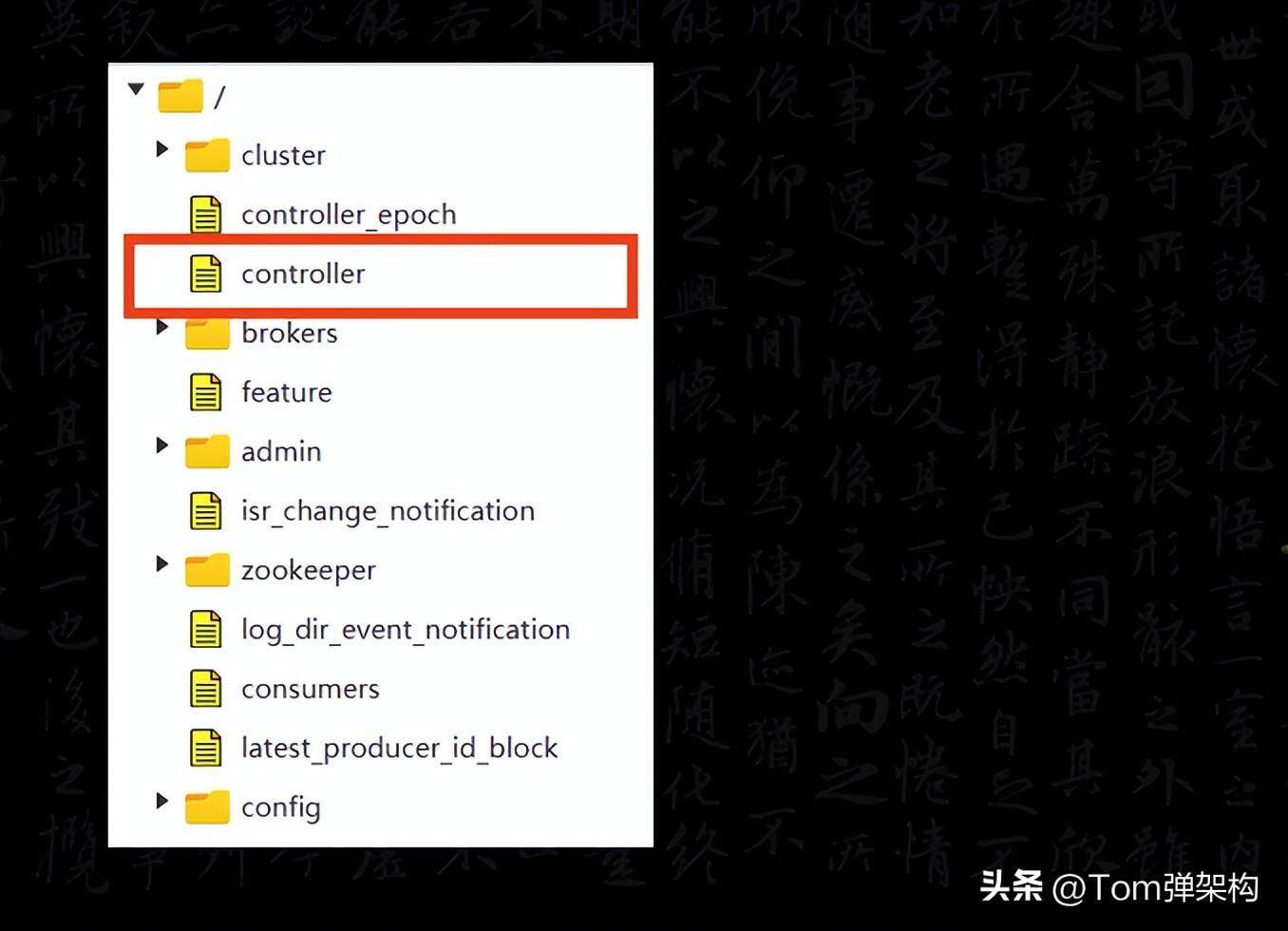
所有的Broker會嘗試在Zookeeper中創建臨時節點/controller,誰先創建成功,誰就是Controller。那如果Controller掛掉或者網絡出現問題,ZooKeeper上的臨時節點就會消失。其他的Broker通過Watch監聽到Controller下線的消息后,繼續按照先到先得的原則競選Controller。這個Controller就相當于選舉委員會的主席。
當一個節點成為Controller之后,他就會承擔以下職責:
監聽Broker變化、監聽Topic變化、監聽Partition變化、獲取和管理Broker、Topic、Partition的信息、管理Partiontion的主從信息。
2、選舉規則
Controller確定以后,就可以開始做分區選主的事情。接下來就是找候選人。顯然,每個Replica都想推薦自己,但不是所有的Replica都有競選資格。只有在ISR(In-Sync Replicas)保持心跳同步的副本才有資格參與競選。就好比是皇帝每天著急皇子們開早會,只有每天來打卡的皇子才能加入ISR。那些請假的、遲到的沒有資格參與選舉。
接下來,就是Leader選舉,就相當于要在眾多皇子中選出太子。在分布式選舉中,有非常多的選舉協議比如ZAB、Raft等等,他們的思想歸納起來都是:先到先得,少數服從多數。但是Kafka沒有用這些方法,而是用了一種自己實現的算法。
提到Kafka官方的解釋是,它的選舉算法和微軟的PacificA算法最相近。大致意思就是,默認是讓ISR中第一個Replica變成Leader。比如ISR是1、5、9,優先讓1成為Leader。這個跟中國古代皇帝傳位是一樣的,優先傳給皇長子。
假設,我們創建一個4個分區2個副本的Topic,它的Leader分布是這樣的,如圖所示:
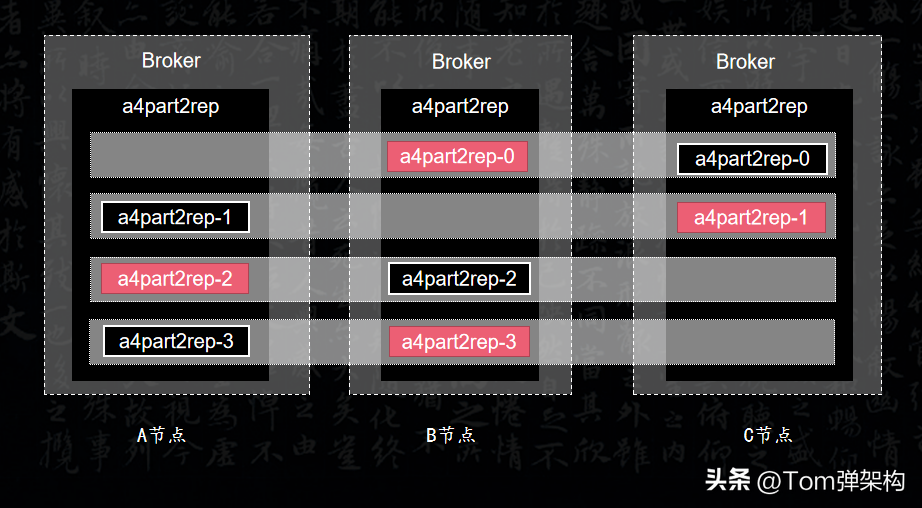
第1個分區的副本Leader,落在B節點上。第2個分區的副本Leader落在C節點上,第3個分區的副本Leader落在A節點上,第4個分區的副本Leader落在B節點上。如果有更多副本,就以此類推。我們發現Leader的選舉的規則相當于蛇形走位。
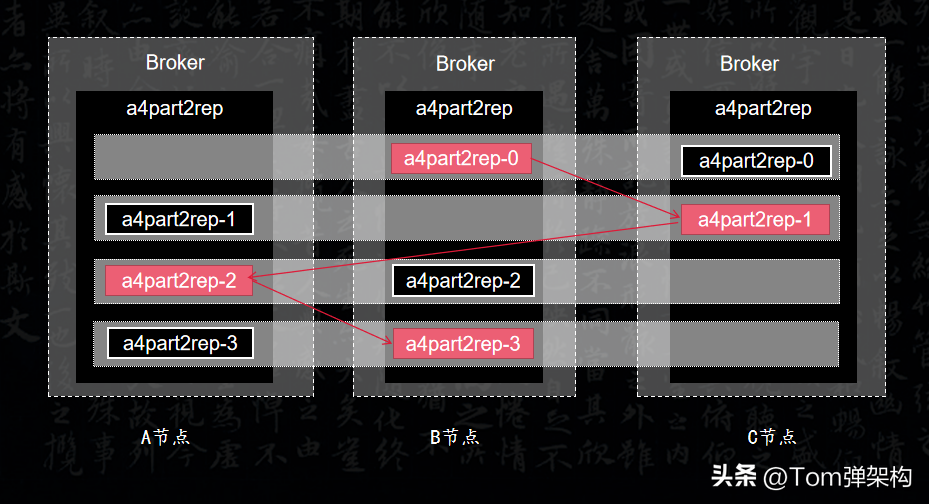
這樣設計的好處是可以提高數據副本的容災能力。將Leader和副本完全錯開,從而不至于一掛全掛。
以上就是我對Kafka副本Leader選舉原理的理解!






























