百億級數據分庫分表后怎么分頁查詢?
隨著數據的日益增多,在架構上不得不分庫分表,提高系統的讀寫速度,但是這種架構帶來的問題也是很多,這篇文章就來講一講跨庫/表分頁查詢的解決方案。
架構背景
筆者曾經做過大型的電商系統中的訂單服務,在企業初期時業務量很少,單庫單表基本扛得住,但是隨著時間推移,數據量越來越多,訂單服務在讀寫的性能上逐漸變差,架構組也嘗試過各種優化方案,比如前面介紹過的:、各種方案。雖說提升一些性能,但是在每日百萬數據增長的情況下,也是杯水車薪。
最終經過架構組的討論,選擇了分庫分表;至于如何拆分,分片鍵如何選擇等等細節不是本文重點,不再贅述。
在分庫分表之前先來拆解一下業務需求:。
- C端用戶需要查詢自己所有的訂單。
- 后臺管理員、客服需要查詢訂單信息(根據訂單號、用戶信息.....查詢)。
- B端商家需要查詢自己店鋪的訂單信息。
針對以上三個需求,判斷下優先級,當然首先需要滿足C端用戶的業務場景,因此最終選用了uid作為了shardingKey。
當然選擇uid作為shardingKey僅僅滿足了C端用戶的業務場景,對于后臺和C端用戶的業務場景如何做呢?很簡單,只需要將數據異構一份存放在ES或者HBase中就可以實現,比較簡單,不再贅述。
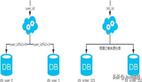
假設將訂單表根據hash(uid%2+1)拆分成了兩張表,如下圖:

假設現在需要根據訂單的時間進行排序分頁查詢(這里不討論shardingKey路由,直接全表掃描),在單表中的SQL如下:
select * from t_order order by time asc limit 5,5;
這條SQL非常容易理解,就是翻頁查詢第2頁數據,每頁查詢5條數據,其中offest=5
假設現在t_order_1和t_order_2中的數據如下:

以上20條數據從小到大的排序如下:

t_order_1中對應的排序如下:

t_order_2中對應的排序如下:

那么單表結構下最終結果只需要查詢一次,結果如下:

分表的架構下如何分頁查詢呢?下面介紹幾種方案:
1. 全局查詢法
在數據拆分之后,如果還是上述的語句,在兩個表中直接執行,變成如下兩條SQL:
select * from t_order_1 order by time asc limit 5,5;
select * from t_order_2 order by time asc limit 5,5;
將獲取的數據然后在內存中再次進行排序,那么最終的結果如下:

可以看到上述的結果肯定是不對的。
所以正確的SQL改寫成如下:
select * from t_order_1 order by time asc limit 0,10;
select * from t_order_2 order by time asc limit 0,10;
也就是說,要在每個表中將前兩頁的數據全部查詢出來,然后在內存中再次重新排序,最后從中取出第二頁的數據,這就是全局查詢法
該方案的缺點非常明顯:
隨著頁碼的增加,每個節點返回的數據會增多,性能非常低。
服務層需要進行二次排序,增加了服務層的計算量,如果數據過大,對內存和CPU的要求也非常高。
不過這種方案也有很多的優化方法,比如Sharding-JDBC中就對此種方案做出了優化,采用的是,有興趣的可以自行去了解一下。
2. 禁止跳頁查詢法
數據量很大時,可以禁止跳頁查詢,只提供下一頁的查詢方法,比如APP或者小程序中的下拉刷新,這是一種業務折中的方案,但是卻能極大的降低業務復雜度。
比如第一頁的排序數據如下:

那么查詢第二頁的時候可以將上一頁的最大值作為查詢條件,此時的兩個表中的SQL改寫如下:
select * from t_order_1 where time>1664088392 order by time asc limit 5;
select * from t_order_2 time>1664088392 order by time asc limit 5;
然后同樣是需要在內存中再次進行重新排序,最后取出前5條數據
但是這樣的好處就是不用返回前兩頁的全部數據了,只需要返回一頁數據,在頁數很大的情況下也是一樣,在性能上的提升非常大
此種方案的缺點也是非常明顯:不能跳頁查詢,只能一頁一頁的查詢,比如說從第一頁直接跳到第五頁,因為無法獲取到第四頁的最大值,所以這種跳頁查詢肯定是不行的。
3. 二次查詢法
以上兩種方案或多或少的都有一些缺點,下面介紹一下二次查詢法,這種方案既能滿足性能要求,也能滿足業務的要求,不過相對前面兩種方案理解起來比較困難。
還是上面的SQL:
select * from t_order order by time asc limit 5,5;
(1)SQL改寫
第一步需要對上述的SQL進行改寫:
select * from t_order order by time asc limit 2,5;
注意:原先的SQL的offset=5,稱之為全局offset,這里由于是拆分成了兩張表,因此改寫后的offset=全局offset/2=5/2=2。
最終的落到每張表的SQL如下:
select * from t_order_1 order by time asc limit 2,5;
select * from t_order_2 order by time asc limit 2,5;
執行后的結果如下:

下圖中紅色部分則為最終結果:

(2)返回數據的最小值
t_order_1:5條數據中最小值為:
t_order_1:5條數據中最小值為:
那么兩張表中的最小值為,記為,來自t_order_2這張表,這個過程只需要比較各個分庫第一條數據,時間復雜度很低。
(3)查詢二次改寫
第二次的SQL改寫也是非常簡單,使用between語句,起點就是第2步返回的最小值time_min,終點就是每個表中在第一次查詢時的最大值。
t_order_1這張表,第一次查詢時的最大值為1664088581,則SQL改寫后:
select * from t_order_1 where time between $time_min and 1664088581 order by time asc;
t_order_2這張表,第一次查詢時的最大值為1664088481,則SQL改寫后:
select * from t_order_2 where time between $time_min and 1664088481 order by time asc;
此時查詢的結果如下(紅色部分):

上述例子只是數據巧合導致第2步的結果和第3步的結果相同,實際情況下一般第3步的結果會比第2步的結果返回的數據會多。
(4)在每個結果集中虛擬一個time_min記錄,找到time_min在全局的offset。
在每個結果集中虛擬一個time_min記錄,找到time_min在全局的offset,下圖藍色部分為虛擬的time_min,紅色部分為第2步的查詢結果集。

因為第1步改后的SQL的offset為2,所以查詢結果集中每個分表的第一條數據offset為3(2+1);
t_order_1中的第一條數據為,這里的offset為3,則向上推移一個找到了虛擬的time_min,則offset=2。
t_order_2中的第一條數據就是time_min,則offset=3。
那么此時的time_min的全局offset=2+3=5。
(5) 查找最終數據
找到了time_min的最終全局offset=5之后,那么就可以知道排序的數據了。
將第2步獲取的兩個結果集在內存中重新排序后,結果如下:

現在time_min也就是的offset=5,那么原先的SQL:select * from t_order order by time asc limit 5,5;的結果顯而易見了,向后推移一位,則結果為:

剛好符合之前的結果,說明二次查詢的方案沒問題
這種方案的優點:可以精確的返回業務所需數據,每次返回的數據量都非常小,不會隨著翻頁增加數據的返回量。
缺點也是很明顯:需要進行兩次查詢
總結
本篇文章中介紹了分庫分表后的分頁查詢的三種方案:
全局查詢法:這種方案最簡單,但是隨著頁碼的增加,性能越來越低。
禁止跳頁查詢法:這種方案是在業務上更改,不能跳頁查詢,由于只返回一頁數據,性能較高。
二次查詢法:數據精確,查詢的數據較少,不會隨著翻頁增加數據的返回量,性能較高。