數(shù)據(jù)庫讀寫分離和分庫分表
讀寫分離
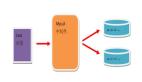
讀寫分離主要是為了將對數(shù)據(jù)庫的讀寫操作分散到不同的數(shù)據(jù)庫節(jié)點(diǎn)上。
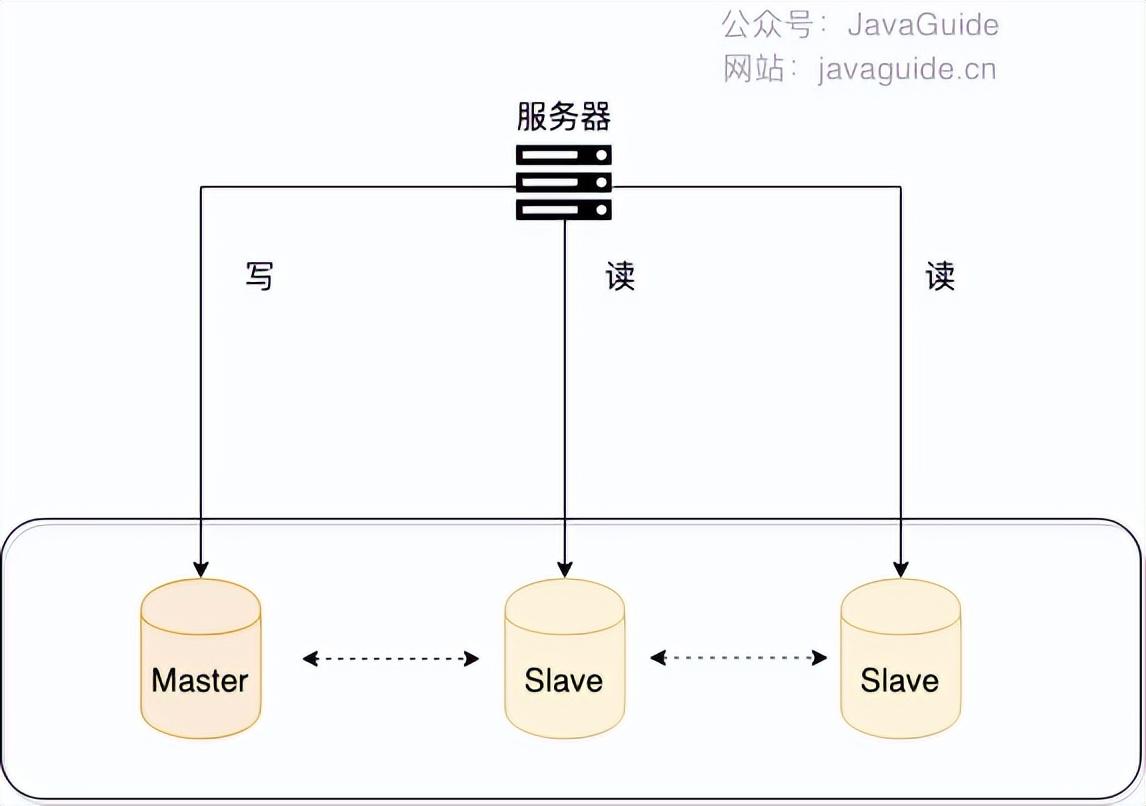
一般情況下,我們都會選擇一主多從,也就是一臺主數(shù)據(jù)庫負(fù)責(zé)寫,其他的從數(shù)據(jù)庫負(fù)責(zé)讀。主庫和從庫之間會進(jìn)行數(shù)據(jù)同步,以保證從庫中數(shù)據(jù)的準(zhǔn)確性。這樣的架構(gòu)實(shí)現(xiàn)起來比較簡單,并且也符合系統(tǒng)的寫少讀多的特點(diǎn)。
# 讀寫分離會帶來什么問題?如何解決?
讀寫分離對于提升數(shù)據(jù)庫的并發(fā)非常有效,但是,同時也會引來一個問題:主庫和從庫的數(shù)據(jù)存在延遲,比如你寫完主庫之后,主庫的數(shù)據(jù)同步到從庫是需要時間的,這個時間差就導(dǎo)致了主庫和從庫的數(shù)據(jù)不一致性問題。這也就是我們經(jīng)常說的 主從同步延遲 。
主從同步延遲問題的解決,沒有特別好的一種方案(可能是我太菜了,歡迎評論區(qū)補(bǔ)充)。你可以根據(jù)自己的業(yè)務(wù)場景,參考一下下面幾種解決辦法。
1.強(qiáng)制將讀請求路由到主庫處理。
既然你從庫的數(shù)據(jù)過期了,那我就直接從主庫讀取嘛!這種方案雖然會增加主庫的壓力,但是,實(shí)現(xiàn)起來比較簡單,也是我了解到的使用最多的一種方式。
比如 Sharding-JDBC 就是采用的這種方案。通過使用 Sharding-JDBC 的 HintManager 分片鍵值管理器,我們可以強(qiáng)制使用主庫。
對于這種方案,你可以將那些必須獲取最新數(shù)據(jù)的讀請求都交給主庫處理。
2.延遲讀取。
還有一些朋友肯定會想既然主從同步存在延遲,那我就在延遲之后讀取啊,比如主從同步延遲 0.5s,那我就 1s 之后再讀取數(shù)據(jù)。這樣多方便啊!方便是方便,但是也很扯淡。
不過,如果你是這樣設(shè)計(jì)業(yè)務(wù)流程就會好很多:對于一些對數(shù)據(jù)比較敏感的場景,你可以在完成寫請求之后,避免立即進(jìn)行請求操作。比如你支付成功之后,跳轉(zhuǎn)到一個支付成功的頁面,當(dāng)你點(diǎn)擊返回之后才返回自己的賬戶。
落實(shí)到項(xiàng)目本身的話,常用的方式有兩種:
1.代理方式
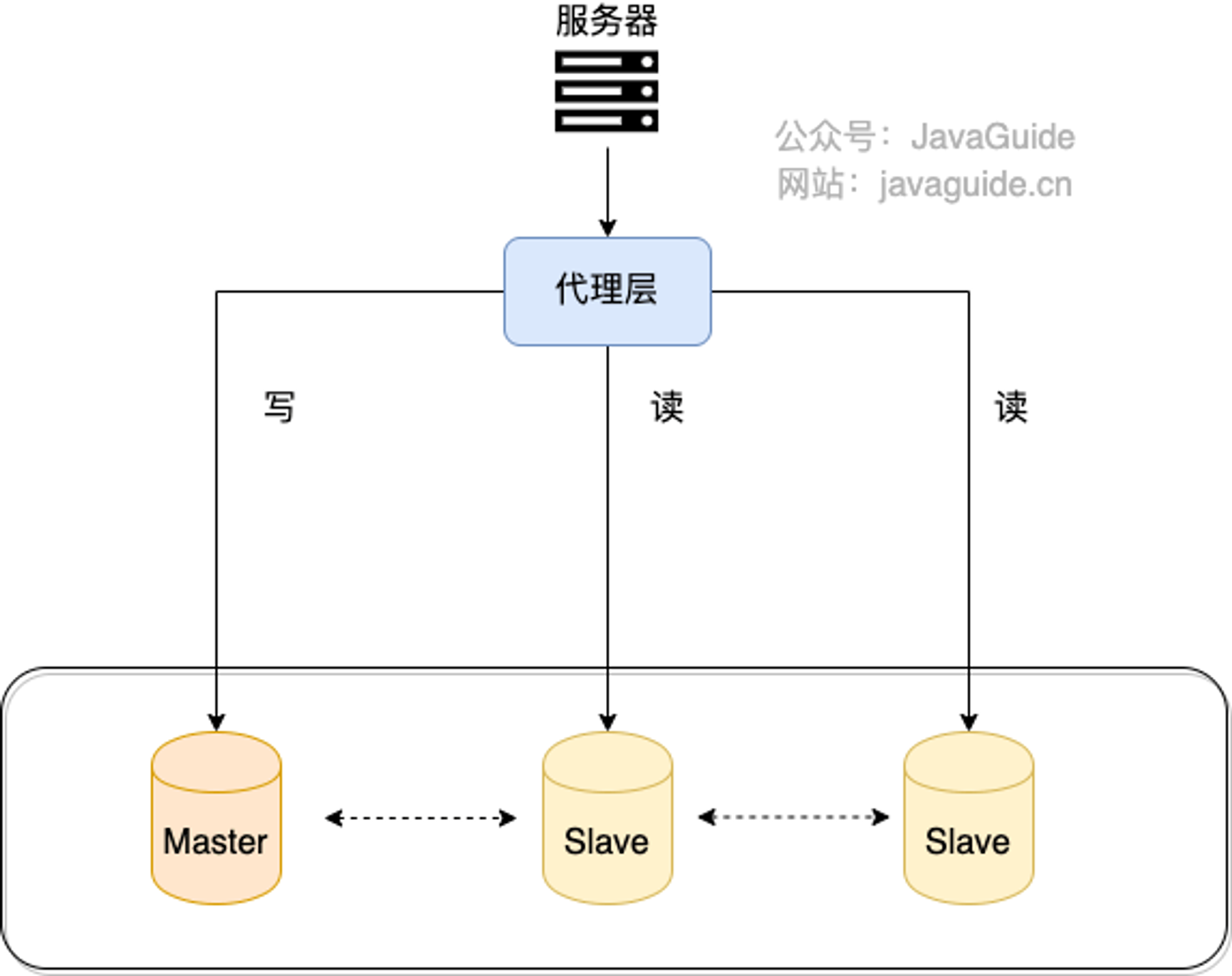
我們可以在應(yīng)用和數(shù)據(jù)中間加了一個代理層。應(yīng)用程序所有的數(shù)據(jù)請求都交給代理層處理,代理層負(fù)責(zé)分離讀寫請求,將它們路由到對應(yīng)的數(shù)據(jù)庫中。
提供類似功能的中間件有 MySQL Router(官方)、Atlas(基于 MySQL Proxy)、Maxscale、MyCat。
2.組件方式
在這種方式中,我們可以通過引入第三方組件來幫助我們讀寫請求。
這也是我比較推薦的一種方式。這種方式目前在各種互聯(lián)網(wǎng)公司中用的最多的,相關(guān)的實(shí)際的案例也非常多。如果你要采用這種方式的話,推薦使用 sharding-jdbc ,直接引入 jar 包即可使用,非常方便。同時,也節(jié)省了很多運(yùn)維的成本。
你可以在 shardingsphere 官方找到 sharding-jdbc 關(guān)于讀寫分離的操作。
MySQL主從復(fù)制原理
MySQL binlog(binary log 即二進(jìn)制日志文件) 主要記錄了 MySQL 數(shù)據(jù)庫中數(shù)據(jù)的所有變化(數(shù)據(jù)庫執(zhí)行的所有 DDL 和 DML 語句)。因此,我們根據(jù)主庫的 MySQL binlog 日志就能夠?qū)⒅鲙斓臄?shù)據(jù)同步到從庫中。
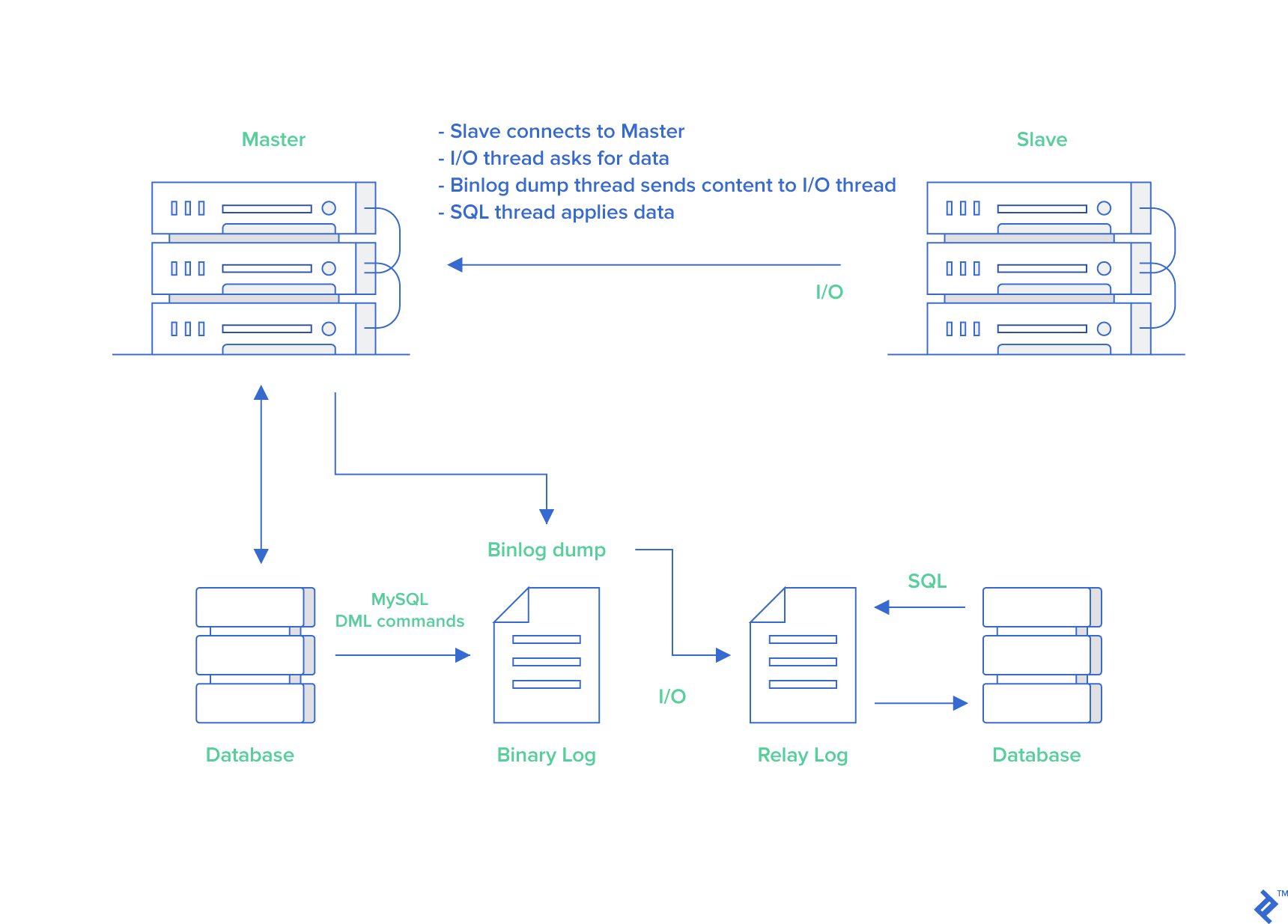
- 主庫將數(shù)據(jù)庫中數(shù)據(jù)的變化寫入到 binlog
- 從庫連接主庫
- 從庫會創(chuàng)建一個 I/O 線程向主庫請求更新的 binlog
- 主庫會創(chuàng)建一個 binlog dump 線程來發(fā)送 binlog ,從庫中的 I/O 線程負(fù)責(zé)接收
- 從庫的 I/O 線程將接收的 binlog 寫入到 relay log 中。
- 從庫的 SQL 線程讀取 relay log 同步數(shù)據(jù)本地(也就是再執(zhí)行一遍 SQL )。
分庫分表
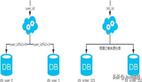
何為分庫?
分庫 就是將數(shù)據(jù)庫中的數(shù)據(jù)分散到不同的數(shù)據(jù)庫上。
下面這些操作都涉及到了分庫:
- 你將數(shù)據(jù)庫中的用戶表和用戶訂單表分別放在兩個不同的數(shù)據(jù)庫。
- 由于用戶表數(shù)據(jù)量太大,你對用戶表進(jìn)行了水平切分,然后將切分后的 2 張用戶表分別放在兩個不同的數(shù)據(jù)庫。
# 何為分表?
分表 就是對單表的數(shù)據(jù)進(jìn)行拆分,可以是垂直拆分,也可以是水平拆分。
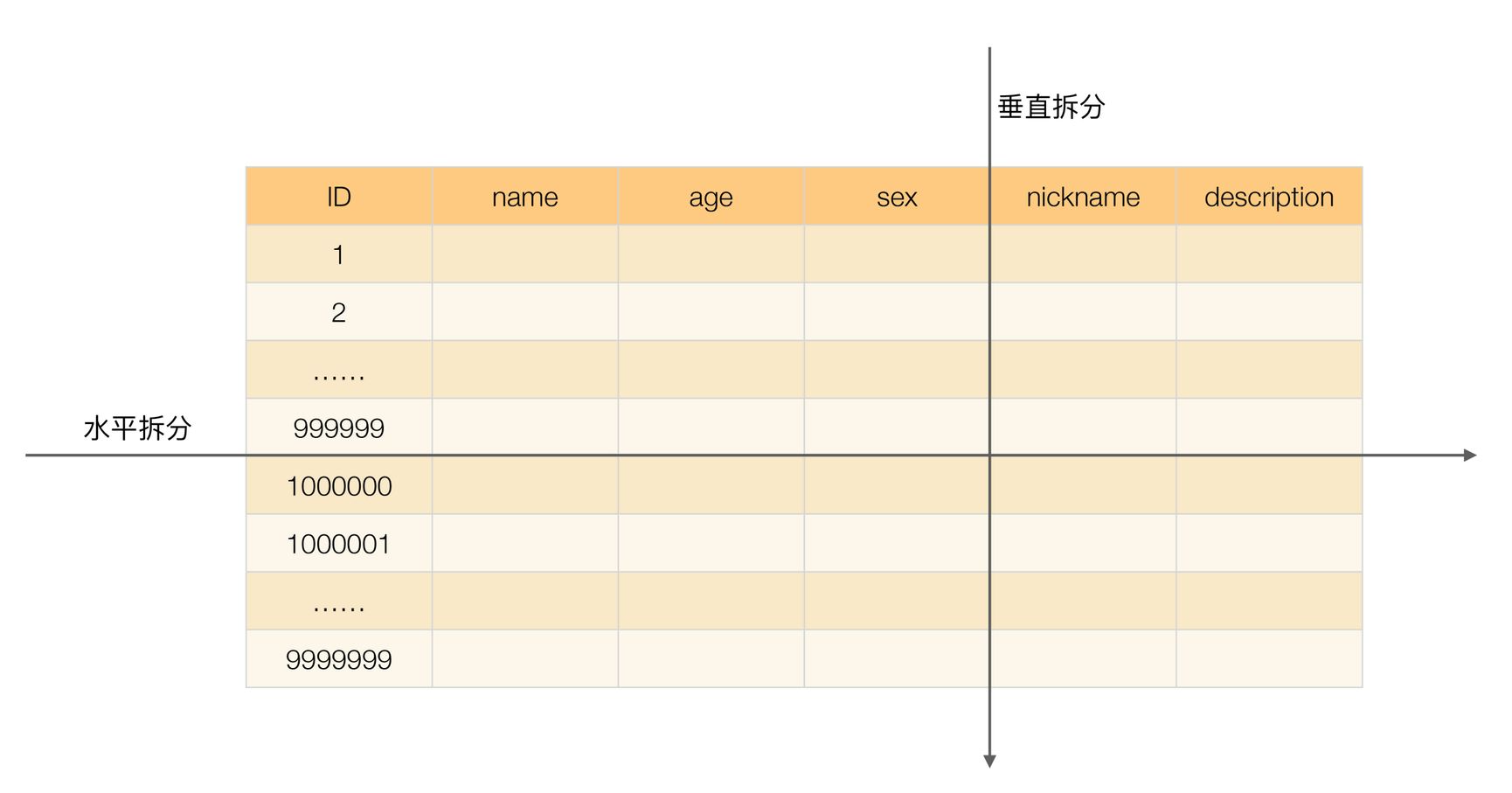
何為垂直拆分?
簡單來說,垂直拆分是對數(shù)據(jù)表列的拆分,把一張列比較多的表拆分為多張表。
舉個例子:我們可以將用戶信息表中的一些列單獨(dú)抽出來作為一個表。
何為水平拆分?
簡單來說,水平拆分是對數(shù)據(jù)表行的拆分,把一張行比較多的表拆分為多張表。
舉個例子:我們可以將用戶信息表拆分成多個用戶信息表,這樣就可以避免單一表數(shù)據(jù)量過大對性能造成影響。
《從零開始學(xué)架構(gòu)》中的有一張圖片對于垂直拆分和水平拆分的描述還挺直觀的。
# 什么情況下需要分庫分表?
遇到下面幾種場景可以考慮分庫分表:
- 單表的數(shù)據(jù)達(dá)到千萬級別以上,數(shù)據(jù)庫讀寫速度比較緩慢(分表)。
- 數(shù)據(jù)庫中的數(shù)據(jù)占用的空間越來越大,備份時間越來越長(分庫)。
- 應(yīng)用的并發(fā)量太大(分庫)。
# 分庫分表會帶來什么問題呢?
記住,你在公司做的任何技術(shù)決策,不光是要考慮這個技術(shù)能不能滿足我們的要求,是否適合當(dāng)前業(yè)務(wù)場景,還要重點(diǎn)考慮其帶來的成本。
引入分庫分表之后,會給系統(tǒng)帶來什么挑戰(zhàn)呢?
- join 操作: 同一個數(shù)據(jù)庫中的表分布在了不同的數(shù)據(jù)庫中,導(dǎo)致無法使用 join 操作。這樣就導(dǎo)致我們需要手動進(jìn)行數(shù)據(jù)的封裝,比如你在一個數(shù)據(jù)庫中查詢到一個數(shù)據(jù)之后,再根據(jù)這個數(shù)據(jù)去另外一個數(shù)據(jù)庫中找對應(yīng)的數(shù)據(jù)。
- 事務(wù)問題:同一個數(shù)據(jù)庫中的表分布在了不同的數(shù)據(jù)庫中,如果單個操作涉及到多個數(shù)據(jù)庫,那么數(shù)據(jù)庫自帶的事務(wù)就無法滿足我們的要求了。
- 分布式 id:分庫之后, 數(shù)據(jù)遍布在不同服務(wù)器上的數(shù)據(jù)庫,數(shù)據(jù)庫的自增主鍵已經(jīng)沒辦法滿足生成的主鍵唯一了。我們?nèi)绾螢椴煌臄?shù)據(jù)節(jié)點(diǎn)生成全局唯一主鍵呢?這個時候,我們就需要為我們的系統(tǒng)引入分布式 id 了。
- ......
另外,引入分庫分表之后,一般需要 DBA 的參與,同時還需要更多的數(shù)據(jù)庫服務(wù)器,這些都屬于成本。
分庫分表有沒有什么比較推薦的方案?
ShardingSphere 項(xiàng)目(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar)是當(dāng)當(dāng)捐入 Apache 的,目前主要由京東數(shù)科的一些巨佬維護(hù)。

ShardingSphere 絕對可以說是當(dāng)前分庫分表的首選!ShardingSphere 的功能完善,除了支持讀寫分離和分庫分表,還提供分布式事務(wù)、數(shù)據(jù)庫治理等功能。
另外,ShardingSphere 的生態(tài)體系完善,社區(qū)活躍,文檔完善,更新和發(fā)布比較頻繁。
# 分庫分表后,數(shù)據(jù)怎么遷移呢?
分庫分表之后,我們?nèi)绾螌⒗蠋欤▎螏靻伪恚┑臄?shù)據(jù)遷移到新庫(分庫分表后的數(shù)據(jù)庫系統(tǒng))呢?
?比較簡單同時也是非常常用的方案就是停機(jī)遷移,寫個腳本老庫的數(shù)據(jù)寫到新庫中。比如你在凌晨 2 點(diǎn),系統(tǒng)使用的人數(shù)非常少的時候,掛一個公告說系統(tǒng)要維護(hù)升級預(yù)計(jì) 1 小時。然后,你寫一個腳本將老庫的數(shù)據(jù)都同步到新庫中。
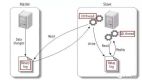
如果你不想停機(jī)遷移數(shù)據(jù)的話,也可以考慮雙寫方案。?雙寫方案是針對那種不能停機(jī)遷移的場景,實(shí)現(xiàn)起來要稍微麻煩一些。具體原理是這樣的:
- 我們對老庫的更新操作(增刪改),同時也要寫入新庫(雙寫)。如果操作的數(shù)據(jù)不存在于新庫的話,需要插入到新庫中。 這樣就能保證,咱們新庫里的數(shù)據(jù)是最新的。
- 在遷移過程,雙寫只會讓被更新操作過的老庫中的數(shù)據(jù)同步到新庫,我們還需要自己寫腳本將老庫中的數(shù)據(jù)和新庫的數(shù)據(jù)做比對。如果新庫中沒有,那咱們就把數(shù)據(jù)插入到新庫。如果新庫有,舊庫沒有,就把新庫對應(yīng)的數(shù)據(jù)刪除(冗余數(shù)據(jù)清理)。
- 重復(fù)上一步的操作,直到老庫和新庫的數(shù)據(jù)一致為止。
想要在項(xiàng)目中實(shí)施雙寫還是比較麻煩的,很容易會出現(xiàn)問題。我們可以借助上面提到的數(shù)據(jù)庫同步工具 Canal 做增量數(shù)據(jù)遷移(還是依賴 binlog,開發(fā)和維護(hù)成本較低)。
總結(jié)
- 讀寫分離主要是為了將對數(shù)據(jù)庫的讀寫操作分散到不同的數(shù)據(jù)庫節(jié)點(diǎn)上。 這樣的話,就能夠小幅提升寫性能,大幅提升讀性能。
- 讀寫分離基于主從復(fù)制,MySQL 主從復(fù)制是依賴于 binlog 。
- 分庫就是將數(shù)據(jù)庫中的數(shù)據(jù)分散到不同的數(shù)據(jù)庫上。分表就是對單表的數(shù)據(jù)進(jìn)行拆分,可以是垂直拆分,也可以是水平拆分。
- 引入分庫分表之后,需要系統(tǒng)解決事務(wù)、分布式 id、無法 join 操作問題。
- ShardingSphere 絕對可以說是當(dāng)前分庫分表的首選!ShardingSphere的功能完善,除了支持讀寫分離和分庫分表,還提供分布式事務(wù)、數(shù)據(jù)庫治理等功能。另外,ShardingSphere的生態(tài)體系完善,社區(qū)活躍,文檔完善,更新和發(fā)布比較頻繁。