













Google 開源 TensorStore,為讀寫大型多維數(shù)據(jù)而設(shè)計(jì)
Google 在上周發(fā)表了一篇博客文章,當(dāng)中介紹了一個(gè)開源的 C++ 和 Python 庫 —— TensorStore,開發(fā)者可以使用它來存儲(chǔ)和操作多維數(shù)據(jù),該庫旨在通過更好地管理和處理大型數(shù)據(jù)集來解決科學(xué)計(jì)算中的關(guān)鍵工程挑戰(zhàn)。
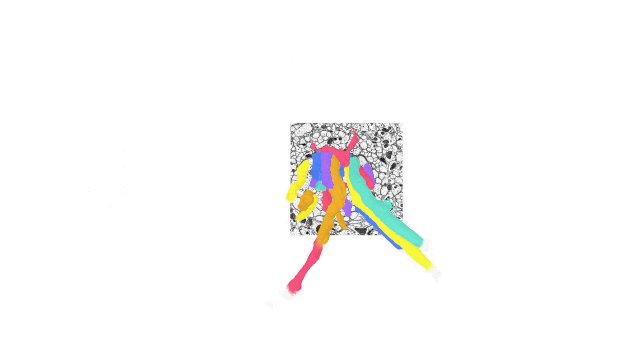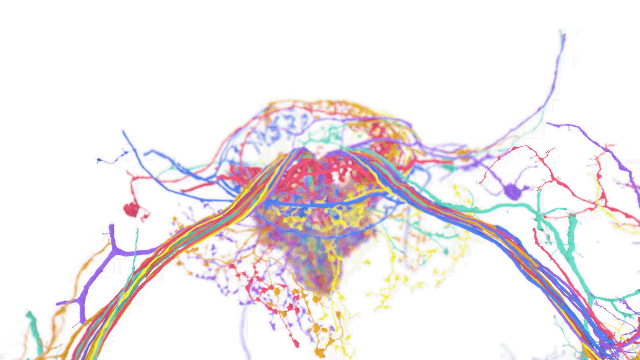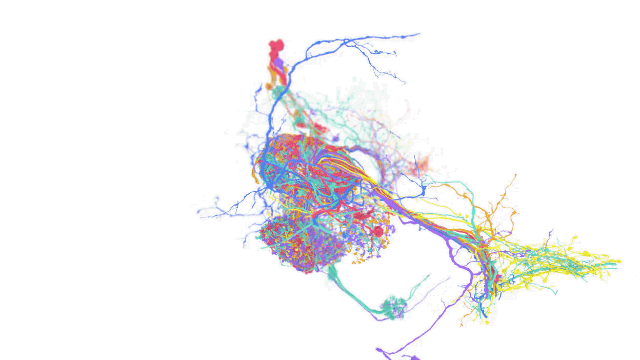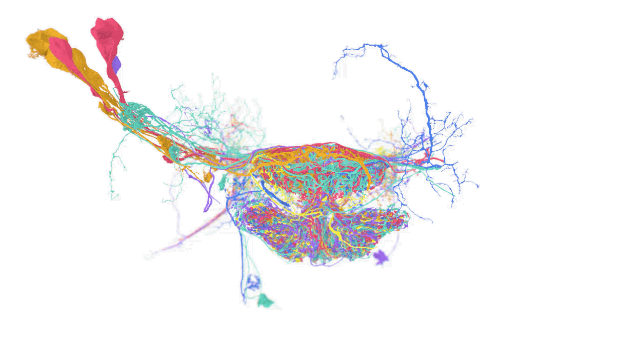
如今計(jì)算機(jī)科學(xué)和機(jī)器學(xué)習(xí)中的各種應(yīng)用都在操作跨越單一坐標(biāo)系的多維數(shù)據(jù)集。在這些應(yīng)用中,一個(gè)單一的數(shù)據(jù)集可能就需要 PB 級(jí)的存儲(chǔ)空間,而且處理這種數(shù)據(jù)集也同樣面對(duì)挑戰(zhàn) —— 因?yàn)橛脩艨赡芤圆煌囊?guī)模和不可預(yù)測(cè)的時(shí)間間隔接收和寫入數(shù)據(jù)。
TensorStore 提供了一個(gè)簡單的 Python API 來加載和處理大量的數(shù)據(jù)數(shù)組,任意大型的底層數(shù)據(jù)集都可以被加載和操作,而且不需要將整個(gè)數(shù)據(jù)集存儲(chǔ)在內(nèi)存中,因?yàn)樵谡?qǐng)求精確分片之前,TensorStore 不會(huì)讀取實(shí)際數(shù)據(jù)或?qū)⑵浔4嬖趦?nèi)存中。這可以通過索引和操作語法實(shí)現(xiàn),這與 NumPy 操作所用的語法基本相同。
TensorStore 還支持多種存儲(chǔ)系統(tǒng),如 Google Cloud、本地和網(wǎng)絡(luò)文件系統(tǒng)等。它提供了一個(gè)統(tǒng)一的 API 來讀寫不同的數(shù)組類型(如 zarr 和 N5)。憑借強(qiáng)大的原子性、隔離性、一致性和持久性(ACID)保證,該庫還提供了讀 / 寫回的緩存和事務(wù)。
此外,TensorStore 具備的并發(fā)性能夠確保當(dāng)許多機(jī)器訪問同一個(gè)數(shù)據(jù)集時(shí),并行操作的安全性。它與各種底層存儲(chǔ)層保持兼容,而不嚴(yán)重影響性能。
研究人員提到,處理和分析大型數(shù)值數(shù)據(jù)集時(shí),需要大量的運(yùn)算資源,一般情況下,這是由分布在多個(gè)設(shè)備上的大量 CPU 或加速器核心之間的并行操作來完成的,這些資源通常也分散在眾多機(jī)器上。TensorStore 的基本目標(biāo),便是要能夠?qū)蝹€(gè)數(shù)據(jù)集進(jìn)行安全并行處理,使這些數(shù)據(jù)集不會(huì)因?yàn)椴⑿写嫒∧J剑a(chǎn)生損壞或是不一致,但又同時(shí)維持高性能。事實(shí)上,在 Google 數(shù)據(jù)中心內(nèi)的一項(xiàng)測(cè)試中發(fā)現(xiàn),隨著 CPU 數(shù)量的增加,讀寫性能幾乎呈線性增長。
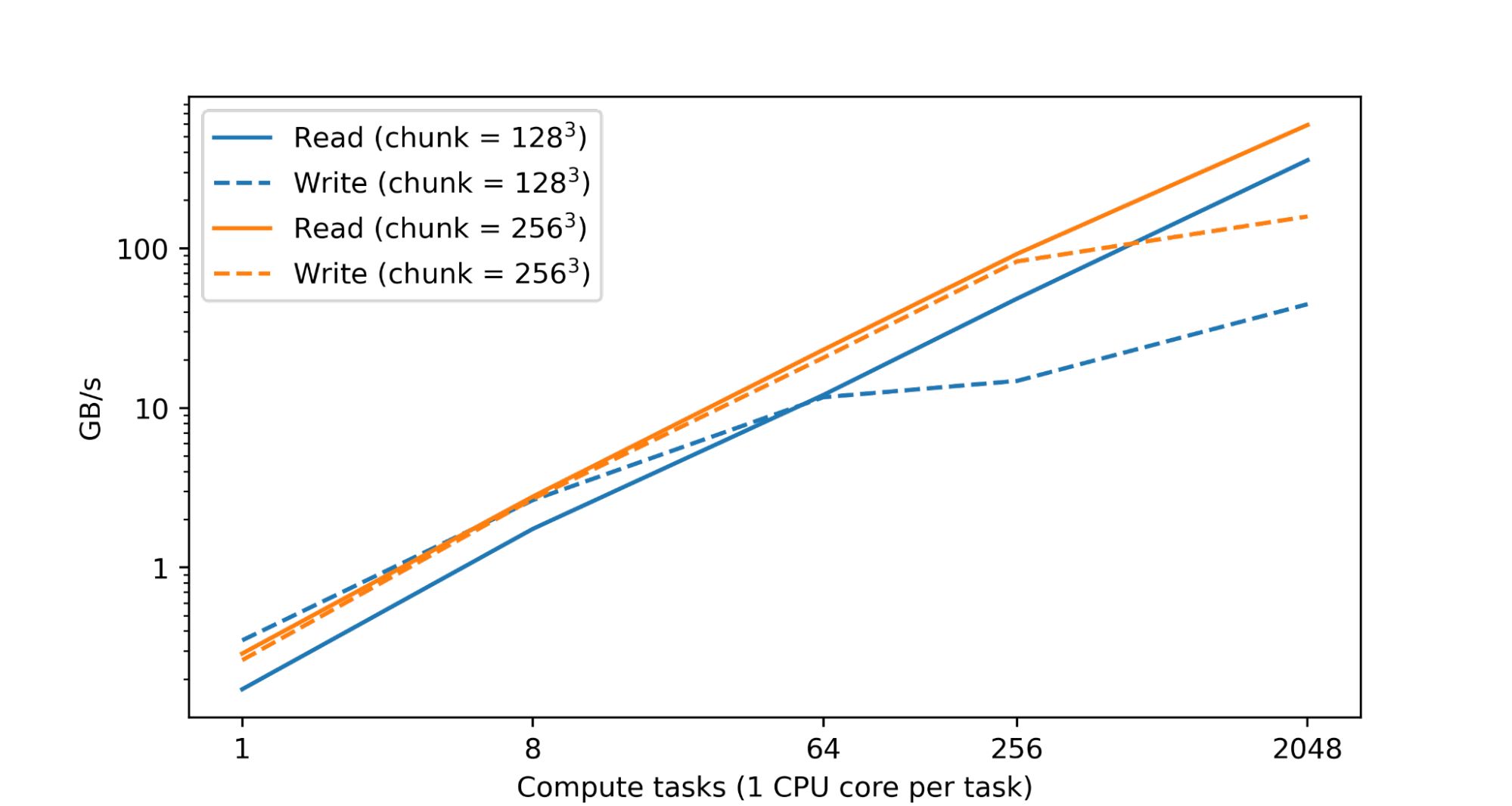
TensorStore 也有一個(gè)異步 API,允許程序在進(jìn)行其他任務(wù)時(shí),可以繼續(xù)在后臺(tái)進(jìn)行讀或?qū)懖僮鳌ensorStore 還與 Apache Beam 和 Dask 等并行計(jì)算框架集成,以使 TensorStore 的分布式計(jì)算與當(dāng)前許多數(shù)據(jù)處理工作流程兼容。
TensorStore 的用例包括語言模型,可在訓(xùn)練過程高效讀取和寫入模型參數(shù),另外也能用于大腦映射上,儲(chǔ)存用于描繪大腦神經(jīng)的高解析度映射圖。
項(xiàng)目 Github 地址: https://github.com/google/tensorstore
本文轉(zhuǎn)自O(shè)SCHINA
本文標(biāo)題:Google 開源 TensorStore,為讀寫大型多維數(shù)據(jù)而設(shè)計(jì)
本文地址:https://www.oschina.net/news/211942/google-tensorstore

















