













分區(qū)如何在分片數(shù)據(jù)庫系統(tǒng)中提高性能
譯文譯者 | 李睿
審校 | 孫淑娟
InfluxData公司資深軟件工程師Nga Tran曾在一篇文章中描述了分片數(shù)據(jù)庫系統(tǒng)來擴展查詢和攝取工作負載的吞吐量和性能。而本文將介紹另一種常用技術(shù),也就是分區(qū),它為分片數(shù)據(jù)庫在性能和管理方面提供了更多優(yōu)勢,還將描述如何有效地處理查詢和攝取工作負載的分區(qū),以及如何管理讀取要求完全不同的熱分區(qū)和冷分區(qū)。
分片 vs. 分區(qū)
分片是一種在分布式數(shù)據(jù)庫系統(tǒng)中拆分數(shù)據(jù)的方法。每個分片中的數(shù)據(jù)不必共享CPU或內(nèi)存等資源,并且可以并行讀取或?qū)懭搿?
圖1是一個分片數(shù)據(jù)庫的示例。例如美國50個州的銷售數(shù)據(jù)被分成4個分片,每個分片包含12個或13個州的數(shù)據(jù)。通過為每個分片分配一個查詢節(jié)點,讀取所有50個州的作業(yè)可以在并行運行的這四個節(jié)點之間拆分,并且與通過一個節(jié)點讀取所有50個州的設置相比,其執(zhí)行速度將快四倍。
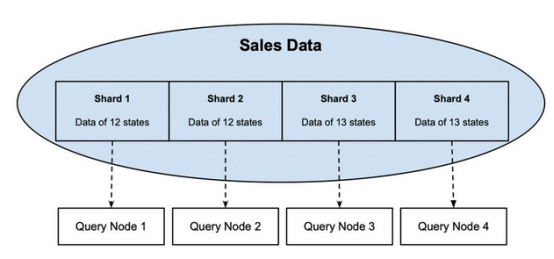
圖1銷售數(shù)據(jù)分為四個分片,每個分片分配給一個查詢節(jié)點
分區(qū)是一種將每個分片中的數(shù)據(jù)拆分為非重疊分區(qū)以進行進一步并行處理的方法。這減少了不必要數(shù)據(jù)的讀取,并允許有效地實施數(shù)據(jù)保留策略。
在圖2中,每個分片的數(shù)據(jù)按銷售日進行分區(qū)。如果需要創(chuàng)建一個特定日期(例如2022年5月1日)的銷售報告,查詢節(jié)點只需要讀取其對應分區(qū)2022.05.01的數(shù)據(jù)。
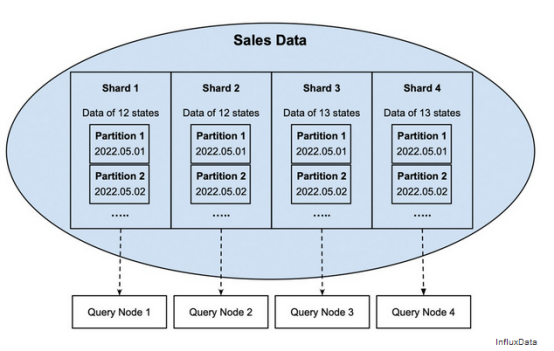
圖2每個分片的銷售數(shù)據(jù)進一步拆分為非重疊的日期分區(qū)
本文的其余部分將關(guān)注分區(qū)的影響,并將看到如何有效地管理對熱數(shù)據(jù)和冷數(shù)據(jù)的查詢和攝取工作負載的分區(qū)。
分區(qū)效果
數(shù)據(jù)分區(qū)的三個最常見的好處是數(shù)據(jù)剪枝、節(jié)點內(nèi)并行性和快速數(shù)據(jù)刪除。
數(shù)據(jù)剪枝
數(shù)據(jù)庫系統(tǒng)可能包含幾年的數(shù)據(jù),但大多數(shù)查詢只需要讀取最近的數(shù)據(jù)(例如“最近三天有多少訂單?”)。將數(shù)據(jù)分區(qū)到不重疊的分區(qū)中,如圖2所示,可以輕松跳過整個越界分區(qū),并只讀取和處理相關(guān)的非常小的數(shù)據(jù)集以快速返回結(jié)果。
節(jié)點內(nèi)并行性
多線程處理和流數(shù)據(jù)在數(shù)據(jù)庫系統(tǒng)中對于充分利用可用CPU和內(nèi)存并獲得最佳性能至關(guān)重要。而將數(shù)據(jù)劃分為小分區(qū)可以更輕松地實現(xiàn)每個分區(qū)執(zhí)行一個線程的多線程引擎。對于每個分區(qū),可以產(chǎn)生更多線程來處理該分區(qū)內(nèi)的數(shù)據(jù)。了解分區(qū)統(tǒng)計信息(例如大小和行數(shù))將有助于為特定分區(qū)分配最佳CPU和內(nèi)存量。
快速數(shù)據(jù)刪除
許多企業(yè)只保留最近的數(shù)據(jù)(例如最近三個月的數(shù)據(jù)),并希望盡快刪除舊數(shù)據(jù)。通過在不重疊的時間窗口上對數(shù)據(jù)進行分區(qū),刪除舊分區(qū)變得像刪除文件一樣簡單,無需重新組織數(shù)據(jù)和中斷其他查詢或攝取活動。如果必須保留所有數(shù)據(jù),本文后面的部分將介紹如何以不同方式管理新舊數(shù)據(jù),以確保數(shù)據(jù)庫系統(tǒng)在所有情況下都能提供出色的性能。
存儲和管理分區(qū)
針對查詢工作負載進行優(yōu)化
一個分區(qū)已經(jīng)包含一部分數(shù)據(jù),因此不希望將一個分區(qū)存儲在許多較小的文件中(或者在內(nèi)存數(shù)據(jù)庫的情況下為塊)。一個分區(qū)應該只包含一個或幾個文件。
最小化分區(qū)中的文件數(shù)量有兩個重要的好處。它既減少了讀取數(shù)據(jù)以執(zhí)行查詢的I/O操作,又改進了數(shù)據(jù)編碼/壓縮。改進編碼反過來會降低存儲成本,更重要的是,通過讀取更少的數(shù)據(jù)來提高查詢執(zhí)行速度。
針對攝取工作負載進行優(yōu)化
Naive攝取。為了將一個分區(qū)的數(shù)據(jù)保存在一個文件中以利于上述讀取優(yōu)化,每次攝取一組數(shù)據(jù)時,都必須將其解析并拆分為正確的分區(qū),然后合并到其對應分區(qū)的現(xiàn)有文件中,如圖3所示。
由于I/O以及混合和編碼分區(qū)數(shù)據(jù)的成本高昂,將新數(shù)據(jù)與現(xiàn)有數(shù)據(jù)合并的過程通常需要時間。這將導致向客戶端返回數(shù)據(jù)已成功攝取的響應以及對新攝取的數(shù)據(jù)的查詢的長時間延遲,因為它不會立即在存儲中可用。
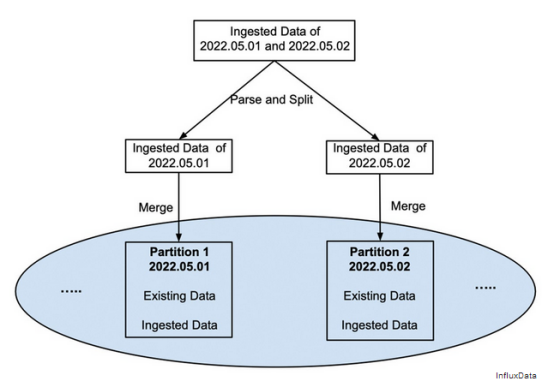
圖3新數(shù)據(jù)與現(xiàn)有數(shù)據(jù)立即合并到同一個文件中的原始攝取
低延遲攝取。為了保持每次攝取的低延遲,可以將過程分為兩個步驟:攝取和壓縮。
攝取
在攝取步驟中,攝取的數(shù)據(jù)被拆分并寫入自己的文件,如圖4所示。它不會與分區(qū)的現(xiàn)有數(shù)據(jù)合并。一旦攝取的數(shù)據(jù)成功持久化,攝取客戶端將收到成功信號,并且新攝取的文件將可用于查詢。
如果攝取率很高,許多小文件將累積在分區(qū)中,如圖5所示。在這個階段,需要從分區(qū)中獲取數(shù)據(jù)的查詢必須讀取該分區(qū)的所有文件。當然,這對查詢性能來說并不理想。如下所述的壓縮步驟將文件的這種積累保持在最低限度。
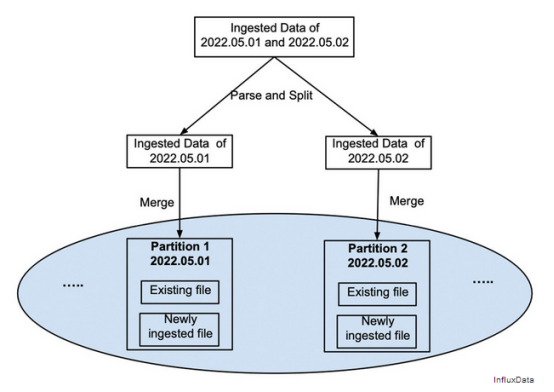
圖4將新攝取的數(shù)據(jù)寫入新文件
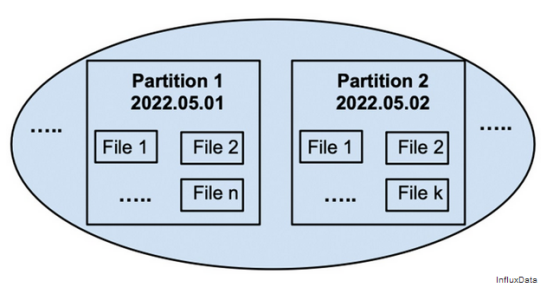
圖5 在高攝取數(shù)據(jù)工作負載下,一個分區(qū)將累積許多文件
壓縮
壓縮是將一個分區(qū)的文件合并成一個或幾個文件的過程,以獲得更好的查詢性能和壓縮。例如,圖6顯示了將分區(qū)2022.05.01中的所有文件合并為一個文件,并將分區(qū)2022.05.02中的所有文件合并為兩個文件,每個文件小于100MB。
對于不同的系統(tǒng),關(guān)于壓縮頻率和壓縮文件的大小的決定會有所不同,但共同的目標是通過減少I/O(即文件數(shù)量)并使文件足夠大以有效壓縮來保持高查詢性能。
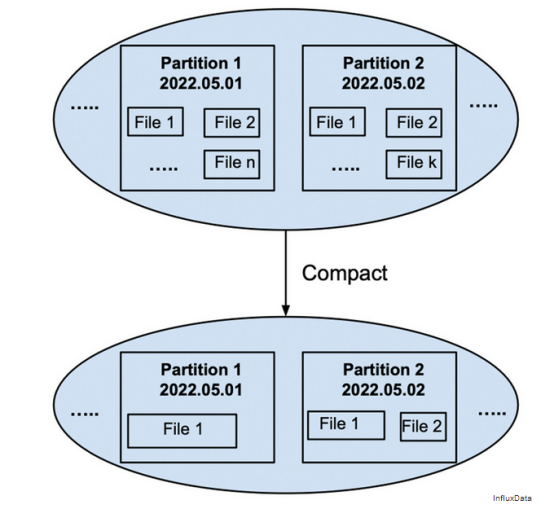
圖6 將一個分區(qū)的多個文件壓縮成一個或幾個文件
熱分區(qū) vs. 冷分區(qū)
經(jīng)常查詢的分區(qū)稱為熱分區(qū),而很少讀取的分區(qū)稱為冷分區(qū)。在數(shù)據(jù)庫中,熱分區(qū)通常是包含最近數(shù)據(jù)的分區(qū),例如最近的銷售日期。冷分區(qū)通常包含較舊的數(shù)據(jù),這些數(shù)據(jù)不太可能被讀取。
此外,當數(shù)據(jù)變舊時,通常會以較大的塊進行查詢,例如按月甚至按年進行查詢。以下是一些將數(shù)據(jù)從熱到冷明確分類的示例:
- 熱:本周的數(shù)據(jù)。
- 不太熱:前幾周但是當月的數(shù)據(jù)。
- 冷:來自前幾個月但是本年度的數(shù)據(jù)。
- 更冷:去年及以前的數(shù)據(jù)。
為了減少冷熱數(shù)據(jù)之間的歧義,需要找到兩個問題的答案。首先,需要量化熱、不太熱、冷、更冷,甚至可能越來越冷的數(shù)據(jù)。其次,需要考慮在讀取冷數(shù)據(jù)的情況下,如何實現(xiàn)更少的I/O。每個文件代表一天的數(shù)據(jù)分區(qū),人們不想只是為了獲得去年的銷售收入而去讀取365個文件。
分層分區(qū)
圖7所示的分層分區(qū)為上述兩個問題提供了答案。本周每一天的數(shù)據(jù)都存儲在其自己的分區(qū)中。本月前幾周的數(shù)據(jù)按周劃分。本年度前幾個月的數(shù)據(jù)按月份劃分。更早的數(shù)據(jù)按年份劃分。
通過定義活動分區(qū)來代替當前的日期分區(qū),可以放寬該模型。在活動分區(qū)之后到達的所有數(shù)據(jù)將按日期進行分區(qū),而在活動分區(qū)之前的數(shù)據(jù)將按周、月和年進行分區(qū)。這允許系統(tǒng)根據(jù)需要保留盡可能多的最近使用的小分區(qū)。盡管本文中的所有示例都按時間分區(qū)數(shù)據(jù),但只要可以為分區(qū)及其層次結(jié)構(gòu)定義表達式,非時間分區(qū)的工作方式也將類似。
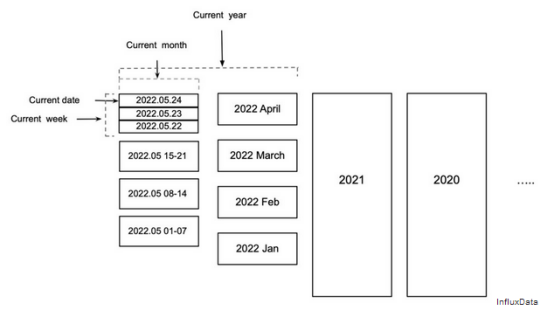
圖7分層分區(qū)
分層分區(qū)減少了系統(tǒng)中的分區(qū)數(shù)量,使其更易于管理,并減少了在查詢較大和較舊的塊時需要讀取的分區(qū)數(shù)量。
分層分區(qū)的查詢過程與非分層分區(qū)的查詢過程相同,因為它將應用相同的數(shù)據(jù)剪枝策略來僅讀取相關(guān)分區(qū)。攝取和壓縮過程會稍微復雜一些,因為在其定義的層次結(jié)構(gòu)中組織分區(qū)會更加困難。
聚合分區(qū)
許多企業(yè)并不想保留舊數(shù)據(jù),而是希望保留聚合數(shù)據(jù),例如每個月的訂單數(shù)量和每種產(chǎn)品的總銷售額。這可以通過聚合數(shù)據(jù)并按月分區(qū)提供支持。但是,由于聚合分區(qū)存儲聚合數(shù)據(jù),因此它們的架構(gòu)將與非聚合分區(qū)不同,這將導致攝取和查詢的額外工作。有不同的方法來管理這些冷數(shù)據(jù)和聚合數(shù)據(jù),但它們是適合未來的大主題。
文章標題:??Partitioning for performance in a sharding database system??,作者:Nga Tran
















