













向量化如何提高數據庫性能
譯文?譯者 | 李睿
審校 | 孫淑娟
提高分析性能非常重要。大家都明白這一點,但要確保用戶在不增加額外工作量的情況下獲得所需的速度,最好的方法是什么?
作為數據工程師,通常面臨著這個挑戰。為了找到解決方案,一個研究團隊啟動了開放項目StarRocks,這是一個分析引擎,可以滿足快速增長的分析性能需求,同時也易于使用和維護。
隨著開放項目和技術社區在過去幾年的發展,人們已經了解到很多關于分析性能的有效方法和無效方法。如今分享一些關于構建高性能分析引擎的關鍵技術之一的見解:向量化。
為什么向量化可以提高數據庫性能
在深入研究StarRocks如何實現向量化之前,有一點很重要:當談論向量化時,談論的是使用現代CPU架構的數據庫的向量化。有了這些了解,就可以開始回答這個問題:為什么向量化可以提高數據庫性能?
要回答這個問題,首先要回答以下幾個問題:
(1)如何衡量CPU性能?
(2)影響CPU性能的因素有哪些?
第一個問題的答案可以用這個公式表示:
CPU時間=(指令數)*CPI*(時鐘周期時間)
- 指令數=CPU生成的指令數
- CPI(每條指令的周期)=執行一條指令所需的CPU周期
- 時鐘周期時間=CPU時鐘周期所用的時間
這個公式提供了一些術語,可以用來討論影響性能的杠桿。由于對時鐘周期時間無能為力,所以需要關注指令號和CPI來提高軟件性能。
此外,還知道的另一個重要信息是,CPU指令的執行可以分為五個步驟:
(1)提取
(2)解碼
(3)執行
(4)內存訪問
(5)寫回結果(寫入寄存器)
步驟1和步驟2由CPU前端執行,步驟3到步驟5由CPU后端處理。Intel公司發布了自頂向下微架構分析方法,如下圖所示。
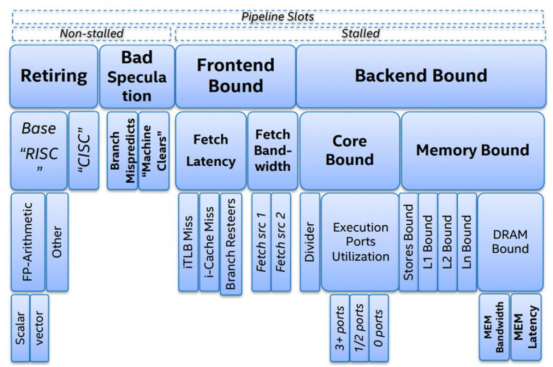
自頂向下微架構分析方法(Intel)
下面是上述方法的簡化版本。
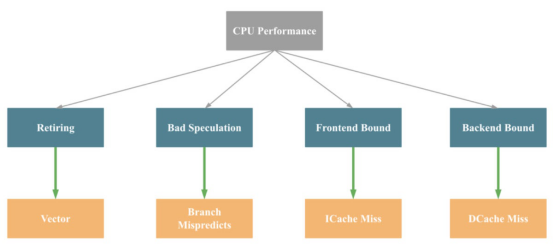
正如人們所看到的,導致CPU性能問題的主要因素是退役、錯誤猜測、前端綁定和后端綁定。
這些問題背后的主要驅動因素分別是缺乏SIMD指令優化、分支預測錯誤、指令緩存失誤和數據緩存失誤。
因此,如果將上述原因映射到前面介紹的CPU性能公式,可以得到以下結論:
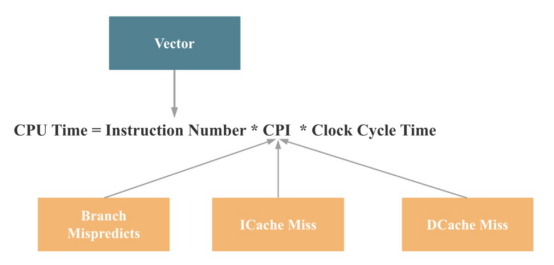
那么,設計什么來提高這四個方面的CPU性能呢?
沒錯,是向量化。
現在已經確定了向量化可以提高數據庫性能。下面將講解向量化是如何做到這一點。
向量化的基本原理
如果已經很好地理解了向量化,那么可以跳過這一節,然后轉到關于數據庫向量化的一節,但是如果不熟悉向量化的基礎知識,或者可能需要復習一下,那么將簡要概述應該知道的內容。
在這里將向量化的討論局限于SIMD。SIMD向量化不同于接下來將要討論的一般數據庫向量化。
SIMD的介紹
SIMD的意思是“單指令、多數據”。顧名思義,使用SIMD架構,一條指令可以同時操作多個數據點。在SISD(單指令、單數據)架構中,其中一條指令只能在單個數據點上操作,但情況并非如此。
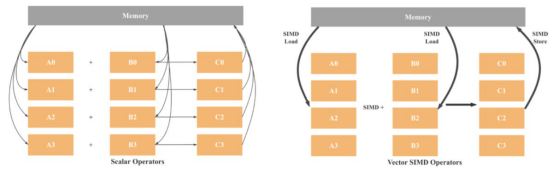
如上所述,在SISD架構中,操作是標量的,這意味著只處理一組數據。因此,4個添加操作將涉及8個加載操作(每個變量一個)、4個添加操作和4個存儲操作。如果使用128位SIMD,只需要兩個加載,一個添加,一個存儲。在理論上,與SISD相比,性能提高了4倍。考慮到現代CPU已經有512位寄存器,可以預期高達16倍的性能增益。
如何向量化一個程序?
以上了解了SIMD向量化如何極大地提高程序的性能。那么,如何開始在自己的工作中使用它呢?
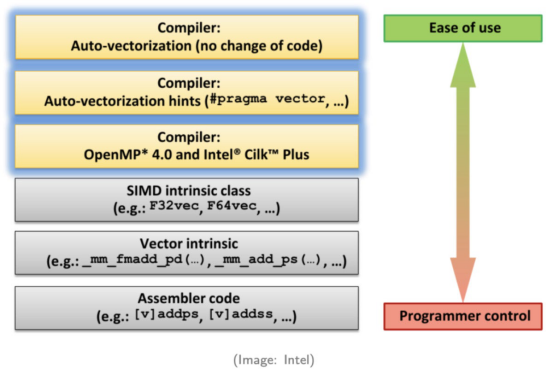
調用SIMD的不同方法
正如英特爾公司的這張圖片所示,SIMD有六種調用方式。從上到下,每個方法都需要程序員更多的專業知識,并需要更多的編碼工作。
方法1.編譯器自動向量化
程序員不需要對他們的代碼做任何更改。編譯器將自動將標量代碼轉換為向量代碼。只有一些簡單的情況可以自動轉換為向量代碼。
方法2.給編譯器的提示
在這個方法中,向編譯器提供了一些提示。通過提供額外的信息,編譯器可以生成更多的SIMD代碼。
方法3.并行編程API
在OpenMP或Intel TBB等并行編程API的幫助下,開發人員可以添加Pragma來生成向量代碼。
方法4.使用SIMD類庫
這些庫包裝了啟用SIMD指令的類。
方法5.使用SIMD intrinsic
intrinsic是一組程序集編碼的函數,允許使用c++函數調用和變量來代替程序集指令。
方法6.直接編寫程序集代碼
1和方法2。對于不能自動轉換為向量代碼的性能關鍵操作,將使用SIMD intrinsic。
驗證程序實際生成了SIMD代碼
這里有一個重要的問題,當一個程序有一個復雜的代碼結構,那么如何確保代碼執行是向量化的?
有兩種方法可以檢查和確認代碼已經向量化。
方法1.向編譯器添加選項
有了這些選項,編譯器將生成關于代碼是否向量化的輸出,如果沒有,原因是什么。例如,可以在GCC編譯器中添加--fopt-info-vec-all, -fopt-info-vec-optimized, -fopt-info-vec-missed, 和 -fopt-info-vec-note選項,如下圖所示:
方法2.檢查執行的程序集代碼
可以使用https://gcc.godbolt.org/這樣的網站或Perf和Vtun這樣的工具來檢查程序集代碼。如果匯編代碼中的寄存器是xmm、ymm、zmm等,或者指令以v開頭,那么就知道該代碼已經向量化了。
既然已經掌握了向量化的基礎知識,現在是時候討論向量化數據庫提高性能的能力了。
數據庫的向量化
雖然StarRocks項目已經發展成為一個成熟、穩定、行業領先的MPP數據庫(甚至還從CelerData推出了企業級版本),但該社區必須克服許多挑戰才能實現這一目標。數據庫向量化是最大的突破之一,也是最大的挑戰之一。
數據庫向量化的挑戰
根據經驗,向量化數據庫要比簡單地在CPU中啟用SIMD指令復雜得多。這是一個龐大的系統工程。特別是面臨著六個技術挑戰:
(1)端到端的柱狀數據。數據需要跨存儲層、網絡層和內存層以柱狀格式存儲、傳輸和處理,以消除“阻抗失配”。存儲引擎和查詢引擎需要重新設計以支持列數據。
(2)所有運算符、表達式和函數都必須實現向量化。這是一項艱巨的任務,需要幾年才能完成。
(3)如果可能,操作符和表達式應該調用SIMD指令。這需要詳細的逐行優化。
(4)內存管理。為了充分利用SIMD CPU的并行處理能力,必須重新考慮內存管理。
(5)新的數據結構。所有用于核心操作符的數據結構,如連接、聚合、排序等,都需要從頭開始支持向量化。
(6)系統的優化。對StarRocks的目標是,與其他市場領先的產品(具有相同的硬件配置)相比,性能提高5倍。為了達到這個目標,必須確保數據庫系統中的所有組件都得到了優化。
向量化運算符和表達式
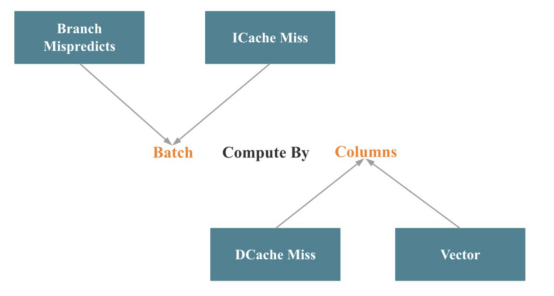
在向量化StarRocks時,大部分工程工作都花在向量化操作符和表達式上。這些工作可以總結為按列批量計算,如下圖所示:
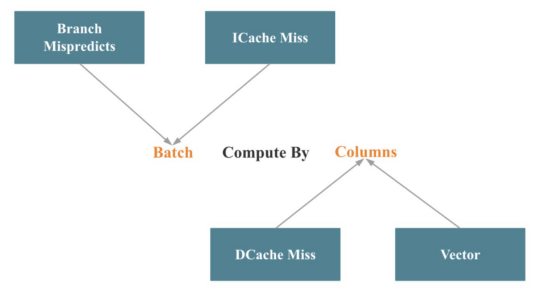
與本文前面討論的Intel公司自頂向下微架構分析方法相對應,Batch減少了分支錯誤預測和指令緩存失誤。按列減少了數據緩存丟失,并使調用SIMD優化更容易。
實現批處理計算相對容易。困難的部分是關鍵操作符(如聯接、聚合、排序和混洗)的列處理。在進行柱狀處理的同時調用盡可能多的SIMD優化是一個更大的挑戰。
如何用數據庫向量化提高數據庫性能
如上所述,向量化數據庫是一項系統工程工作。在過去的幾年里,在開發StarRocks的過程中實施了數百項優化。以下是需要關注的7個最重要的優化領域。
- 高性能的第三方庫。對于數據結構和算法,有許多優秀的開源庫。對于StarRocks,使用了許多第三方庫,例如Parallel Hashmap、Fmt、SIMD Json和Hyper Scan。
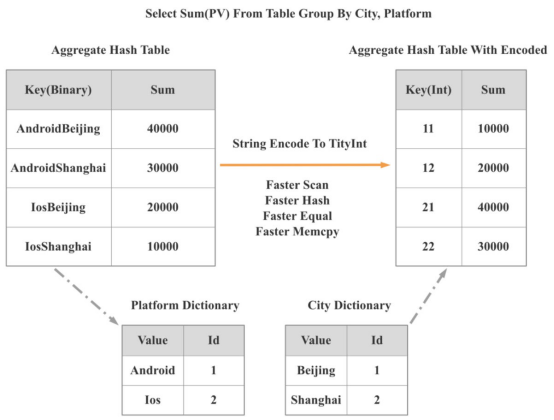
- 數據結構和算法。高效的數據結構和算法可以將CPU周期減少一個數量級。正因為如此,當StarRocks 2.0發布時,引入了一個低基數的全局字典。使用這個全局字典,可以將基于字符串的操作轉換為基于整數的操作。
如下圖所示,通過操作將兩個基于字符串的組轉換為一個基于整數的組。因此,掃描、散列、相等和mumcpy等操作的性能提高了許多倍,整體查詢性能提高了300%以上。
- 自適應優化。如果能夠理解查詢的場景,就可以進一步優化查詢執行。然而,通常直到執行時才得到查詢場景信息。因此,查詢引擎必須根據在查詢執行過程中獲得的場景信息動態調整其策略。這被稱為自適應優化。
下面的代碼片段顯示了一個基于選擇率動態選擇連接運行時過濾器的示例:
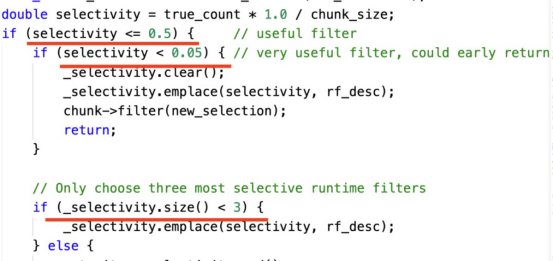
有三個決策點可以指導上述示例:
(1)如果過濾器不能過濾大部分數據,那么就不會使用它。
(2)如果一個過濾器可以過濾幾乎所有的數據,那么我們只保留這個過濾器。
(3)最多保留三個過濾器。
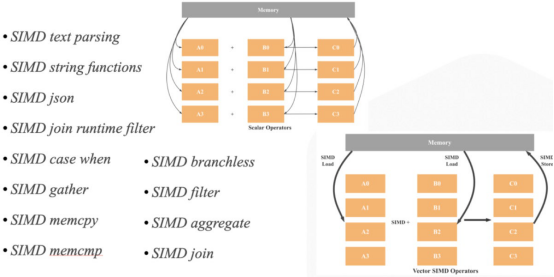
- SIMD優化。如下圖所示,StarRocks在其操作符和表達式實現中進行了大量SIMD優化。
- C++底層優化。即使使用相同的數據結構和算法,不同C++實現的性能也可能不同。例如,可以使用移動或復制操作,可以保留向量,或者可以內聯函數調用。這些只是必須考慮的一些優化。
- 內存管理優化。批處理大小越大,并發性越高,分配和釋放內存的頻率就越高,內存管理對系統性能的影響就越大。
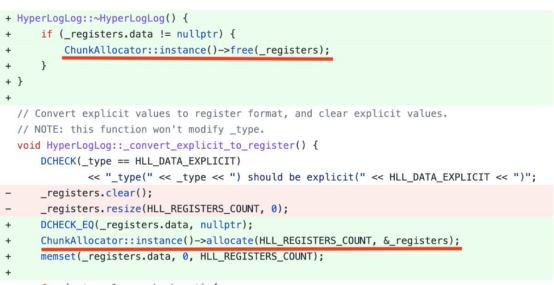
使用StarRocks,實現了一個列池數據結構來重用列的內存,并顯著提高了查詢性能。以下的代碼片段顯示了一個HLL(HyperLogLog)聚合函數內存優化。通過按塊分配HLL內存,并通過重用這些塊,將HLL的聚合性能提高了五倍。
- CPU緩存優化。CPU緩存丟失對性能有巨大的影響。可以從CPU周期的角度來理解這種影響。L1訪問緩存需要3個CPU周期,L2訪問緩存需要9個CPU周期,L3訪問緩存大約需要40個CPU周期,主存訪問緩存大約需要200個CPU周期。
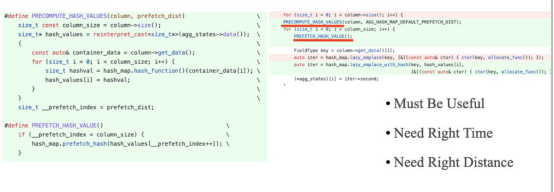
在調用SIMD優化和性能瓶頸從CPU限制轉移到內存限制之后,CPU緩存缺失成為了一個特別重要的因素。下面的代碼片段展示了如何通過預取減少CPU丟失。不過在這里指出的是,預取應該是優化CPU緩存的最后手段。這是因為很難控制預取的時間和距離。
回顧與感想
現在已經踏上了StarRocks數據庫向量化的旅程,以下回顧一下學到了什么。
- 不同系統的基本原理是相似的。當開始研究CPU的微架構時,意識到CPU的架構與數據庫架構的相似之處。在StarRocks的例子中,前端管理SQL解析和查詢規劃,后端負責SQL執行和與存儲層交互。研究的系統和體系結構越多,就會越深入地理解系統級別的相似性。
- 要建立高性能的數據庫,不僅需要設計良好的架構,而且還需要密切關注工程細節。雖然良好的設計和良好的工程似乎都是很明顯的需要,但在數據庫產品中往往缺少其中之一。如果真的相信這兩者,就不會只使用自底向上的方法(從算法和唯一的組件開始)來設計數據庫,而不實現確保所有這些組件都能很好地協同工作的高級架構。也不能選擇Java或Go等編程語言來實現查詢執行引擎和存儲引擎,而可以使用C++等更多性能語言。

- 混合向量化和編譯。向量化和編譯是兩種主要的查詢執行風格,但它們并不相互排斥。盡管大多數開源數據庫都選擇使用向量化,但可以利用查詢編譯,通過查詢執行期間獲得的信息生成更高效的向量代碼。與此同時,查詢編譯也在不斷改進。
- 嘗試采用新的硬件,例如GPUu和FPGA。經過大量優化后,可能已經接近CPU優化的收益遞減點。可以考慮其他新的硬件,以進一步提高StarRocks的性能。
隨著數據量的增長、數據源的擴展和用戶期望的提高,數據工程師的角色在未來幾年只會變得更加重要。有了StarRocks這樣的項目和數據庫向量化這樣的創新,可以滿足遇到的任何性能需求。
原文標題:??How vectorization improves database performance???,作者:James Li,Kaisen Kang?




















