













對比學習算法在轉轉的實踐
- 1 什么是對比學習
- 1.1 對比學習的定義
- 1.2 對比學習的原理
- 1.3 經典對比學習算法系列
- 2 對比學習的應用
- 3 對比學習在轉轉的實踐
- 3.1 CL在推薦召回的實踐
- 3.2 CL在轉轉的未來規劃
1 什么是對比學習
1.1 對比學習的定義
對比學習(Contrastive Learning, CL)是近年來 AI 領域的熱門研究方向,吸引了眾多研究學者的關注,其所屬的自監督學習方式,更是在 ICLR 2020 被 Bengio 和 LeCun 等大佬點名稱為 AI 的未來,后陸續登陸 NIPS, ACL, KDD, CIKM 等各大頂會,Google, Facebook, DeepMind,阿里、騰訊、字節等大廠也紛紛對其投入精力,CL 的相關工作也是刷爆了 CV,乃至 NLP 部分問題的 SOTA,在 AI 圈的風頭可謂一時無兩。
CL 的技術源泉來自度量學習,大概的思想是:定義好樣本的正例和負例,以及映射關系(將實體映射到新的空間),優化目標是讓正例在空間中與目標樣本的距離近一些,而負例要相對遠一些。正因為如此,CL 看上去跟向量化召回思路很像,但其實二者有本質的區別,向量化召回屬于監督學習的一種,會有明確的標簽數據,而且更注重的負樣本的選擇(素有負樣本為王的“學說”);而 CL 是自監督學習(屬于無監督學習的一種范式)的一支,不需要人工標注的標簽信息,直接利用數據本身作為監督信息,學習樣本數據的特征表達,進而引用于下游任務。此外,CL 的核心技術是數據增強(Data Augmentation),更加注重的是如何構造正樣本。下圖是一個抽象的 CL 整體流程圖

對比學習的標簽信息來源于數據本身,核心模塊是數據增強。圖像領域的數據增強技術是比較直觀的,比如圖像的旋轉、遮擋、取部分、著色、模糊等操作,都可以得到一張與原圖整體相似但局部相異的新圖(即增強出來的新圖),下圖是部分圖像數據增強的手段(出自SimCLR[1])。

1.2 對比學習的原理
談到CL的原理,不得不提自監督學習,它避開了人工標注的高成本,以及標簽低覆蓋的稀疏性,更容易學到通用的特征表示。自監督學習可以分成兩大類:生成式方法和對比式方法。生成式方法的典型代表是自編碼器,而對比式學習的經典代表即ICLR 2020的SimCLR,通過(增強后的)正負樣本在特征空間的對比學習特征表示。相比較生成式方法,對比式方法的優勢在于無需對樣本進行像素級的重構,只需要在特征空間能夠學到可區分性即可,這使得相關的優化變得簡單。筆者認為,CL的有效性主要體現在學習item表示的可區分性,而可區分性的學習依賴正負樣本的構造思路,以及具體的模型結構和優化目標。
結合CL的實現過程,Dr Zhang[2]抽象了三個CL必須要回答的問題,也是其區別于度量學習的典型特征,即(1)如何構造正例和負例,也就是數據增強具體是如何實現的;(2)Encoder映射函數如何構造,不僅要盡可能多地保留原始信息,而且要防止坍塌問題;(3)損失函數如何設計,目前通常使用的NCE loss,如下公式所示。不難看出,這三個基本問題對應建模的三要素:樣本,模型,優化算法。
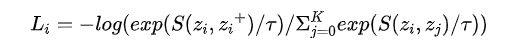
從 loss 公式中可以看出,分子部分強調的是與正例的距離越近越好,S函數衡量的是相似性,距離越近對應的S值越大,分母強調的是與負例的距離越遠越好,loss 越低,對應的可區分性越高。
在這三個基本問題中,數據增強是 CL 算法的核心創新點,不同的增強手段是算法有效性的基本保障,也是各大 CL 算法的identity;Encoder函數通常借助神經網絡實現;除 NCE loss外,還有其他 loss 的變體,比如Google[3]就提出了監督對比損失。
1.3 經典對比學習算法系列
CL是自監督學習的一種學習算法,提到自監督學習,Bert 恐怕是 NLP 領域無法回避的話題,Bert 預訓練 + Fine-tuning 的模式在諸多問題的解決方案中實現了突破,既然自監督可以在 NLP 取得成功,難道計算機視覺就不可以嗎?實際上 Bert 在 NLP 領域取得的成功,也直接地刺激了 CL 在圖像領域的發生和發展。鑒于數據增強可以在圖像領域直觀地展開,CL 也是率先在 CV 領域取得進展,比如 CL 的發展契機—— SimCLR 算法,其創新點主要包括(1)探索了多種不同的數據增強技術的組合,選擇了最優;(2)在 Encoder 之后增加了非線性映射 Projector,主要是考慮 Encoder 學習的向量表示會把增強的信息包含在內,而 Projector 則旨在去除這部分影響,回歸數據的本質。后來Hinton的學生在 SimCLR 的基礎上實現了 SimCLR v2,主要改進點在于 Encoder 的網絡結構,同時借鑒了 MoCo 使用的 Memory Bank 的思想,進一步提升了 SOTA。
實際上,在 SimCLR 之前,Kaiming He 在2019年底提出了對比學習的另一個經典算法MoCo[4],其主要思想是既然對比是在正負樣本之間進行的,那么增加負樣本數量,可以提高學習任務的難度,從而增強模型性能,Memory Bank 是解決該問題的經典思路,但卻無法避免表示不一致的問題,鑒于此,MoCo 算法提出了使用動量的方式更新 Encoder 參數,從而解決新舊候選樣本編碼不一致的問題。后來,Kaiming He 又在 MoCo 的基礎上提出了 MoCo v2(在 SimCLR 提出之后),模型主要框架沒有改動,主要在數據增強的方法、Encoder 結構以及學習率等細節問題上做了優化。
2 對比學習的應用
對比學習不僅是學術界在圖像、文本、多模態等多個領域的熱門研究方向,同時也在以推薦系統為代表的工業界得到了應用。
Google 將 CL 應用于推薦系統Google SSL[5],目的在于針對冷門、小眾的 item 也能學習到高質量的向量表示,從而輔助解決推薦冷啟動問題。其數據增強技術主要采用 Random Feature Masking(RFM),Correlated Feature Masking(CFM)的方法(CFM 一定程度上解決了 RFM 可能構造出無效變體的問題),進而 CL 以輔助塔的形式,結合雙塔召回的主任務共同訓練,整體流程如下圖所示

在模型的訓練過程中,主任務的 item 主要還是來自曝光日志,因此也是對頭部熱門 item 比較友好,為了消除馬太效應的影響,在輔助任務中的樣本構造需要考慮與主任務不同的分布,后續 CL 在轉轉的實踐過程中也是借鑒了這樣的思考,從而確保模型學習結果的充分覆蓋。
數據增強不局限在 item 側,Alibaba-Seq2seq[6]將 CL 的思想應用在序列推薦問題上,即輸入用戶行為序列,預測下一個可能交互的 item。具體地,其數據增強主要應用在用戶行為序列特征,將用戶歷史行為序列按照時序劃分成兩個子序列,作為數據增強后的用戶的表示,喂入雙塔模型,最終輸出結果越相似越好。與此同時,該文為了顯式建模用戶的多興趣,在 Encoder 部分提取出多個向量,而不是壓縮成一個用戶向量。因為隨著子序列的拆分,以及正負例的構造,用戶天然具有多個行為序列的向量表示,在正例中,用戶前一部分歷史行為的向量,與后一部分歷史行為的向量,距離相近,而在負例中,不同用戶的距離相對較遠,而且即使同一用戶,在不同類別商品的向量表示也相對較遠。
CL 還可以與其他學習范式結合應用,圖對比學習[7],整體框架如下圖所示

GCL 通常通過隨機刪除圖中的點或者邊,實現圖數據的增強,而本文的作者傾向于保持重要的結構和屬性不變,擾動發生在不重要的邊或者節點。
3 對比學習在轉轉的實踐
圖像領域取得了成功,文本領域也是可以的,比如美團-ConSERT[8]算法,在句子語義匹配任務的實驗中,相比之前的 SOTA(BERT-flow)提升了8%,并且在少量樣本下仍能表現出較好的性能提升。該算法將數據增強作用在 Embedding 層,采用隱式生成增強樣本的方法,具體地,提出了四種數據增強方法:對抗攻擊(Adversarial Attack),打亂詞序(Token Shuffling),裁剪(Cutoff)和 Dropout,這四種方法均通過調整 Embedding 矩陣得到,比顯式增強方法更高效。
3.1 CL在推薦召回的實踐
轉轉平臺致力于促進低碳循環經濟的更好發展,能夠覆蓋全品類商品,近年來尤其在手機3C領域的發展表現突出。CL 在轉轉推薦系統中的實踐也是選擇了基于文本的應用思路,考慮到二手交易特有的屬性,需要解決的問題包括(1)二手商品的孤品屬性,導致 ID 類的向量并不適用;(2)數據增強是怎么實現的;(3)正例和負例如何構造;(4)Encoder 的模型結構是怎樣的(包括 loss 的設計問題)。針對這四個問題,結合下面的整體流程圖進行詳細說明
針對二手商品的孤品屬性問題,我們采用基于文本的向量作為商品的表征,具體地,使用商品的文本描述(包括標題與內容)集合,訓練 word2vec 模型,并基于詞向量通過 pooling 得到商品的向量表示。
自編碼器(Auto Encoder)算法是文本對比學習領域常用的數據增強手段之一(除此之外,還有機器翻譯、CBERT等不同思路),我們也是采用 AE 算法訓練模型,學習商品向量,并利用算法的中間向量作為商品的增強向量表示,也就有了正例。
負例的生產原則是 Batch 內隨機選取不相似的商品,相似商品的判斷依據是根據用戶的后驗點擊行為計算而來。在以 CF(協同過濾)為代表的推薦系統召回結果中,能夠通過共同點擊行為召回的商品組合,認為是相似的,否則認為是不相似的。之所以采用行為依據判斷是否相似,一方面是為了將用戶的行為引入其中,實現文本與行為的有機結合,另一方面也是為了盡可能地貼合業務目標。
具體到 Encoder 部分,我們采用的是類似孿生網絡的雙塔結構,分別喂入樣本(正正 or 正負)的文本向量,訓練分類模型,網絡結構為三層全連接的神經網絡,雙塔共享該網絡參數,并通過優化交叉熵損失優化模型參數。實際工業界,大部分推薦系統中雙塔模型的訓練目標均為用戶后驗行為(點擊、收藏、下單等),而我們的訓練目標是樣本相似與否,之所以采用孿生網絡的形式,也是出于這樣做可以保證學習結果的覆蓋。
根據 CL 的常規思路,提取最終 Encoder 部分的輸入向量作為商品的向量化表示,可以進一步在推薦系統的召回、粗排甚至精排等環節應用。目前已經在轉轉推薦系統的召回模塊落地,給線上帶來了超過10%的下單提袋率的提升。
3.2 CL在轉轉的未來規劃
通過人工評估以及線上AB實驗,充分確認了CL習得向量表示的有效性,在召回模塊落地后,可以在推薦系統其他模塊,甚至其他算法場景推而廣之。以預訓練的方式學習商品向量表示(當然,也可以學習用戶的向量表示),只是一條應用路徑,CL 更多的是提供了一種學習框架或者學習思路,通過數據增強和對比的形式,使算法學習物品的可區分性,這樣的思路可以自然地引入推薦系統的排序模塊,因為排序問題也可以理解成物品的可區分性問題。
關于作者
李光明,資深算法工程師。參與轉轉搜索算法、推薦算法、用戶畫像等系統的算法體系建設,在GNN、小樣本學習、對比學習等相關領域有實踐應用。
參考資料
[1]SimCLR: A_Simple_Framework_for_Contrastive_Learning_of_Visual_Representations
[2]張俊林: ??https://mp.weixin.qq.com/s/2Js8-YwUEa1Hr_ZYx3bF_A??
[3]Google: Supervised_Contrastive_Learning
[4]MoCo: Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning
[5]SSL: Self-supervised_Learning_for_Large-scale_Item_Recommendations
[6]Ali-Seq2seq: Disentangled_Self-Supervision_in_Sequential_Recommenders
[7]GCL: Graph_contrastive_learning_with_adaptive_augmentation
[8]ConSERT: ConSERT:_A_Contrastive_Framework_for_Self-Supervised_Sentence_Representation_Transfer






























