11個常見的分類特征的編碼技術
機器學習算法只接受數值輸入,所以如果我們遇到分類特征的時候都會對分類特征進行編碼,本文總結了常見的11個分類變量編碼方法。

1、ONE HOT ENCODING
最流行且常用的編碼方法是One Hot Enoding。一個具有n個觀測值和d個不同值的單一變量被轉換成具有n個觀測值的d個二元變量,每個二元變量使用一位(0,1)進行標識。
例如:
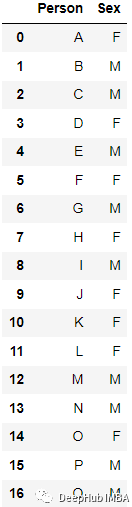
編碼后

最簡單的實現是使用pandas的' get_dummies
2、Label Encoding
為分類數據變量分配一個唯一標識的整數。這種方法非常簡單,但對于表示無序數據的分類變量是可能會產生問題。比如:具有高值的標簽可以比具有低值的標簽具有更高的優先級。
例如上面的數據,我們編碼后得到了下面的結果:

sklearn的LabelEncoder 可以直接進行轉換:
3、Label Binarizer
LabelBinarizer 是一個用來從多類別列表創建標簽矩陣的工具類,它將把一個列表轉換成一個列數與輸入集合中惟一值的列數完全相同的矩陣。
例如這個數據
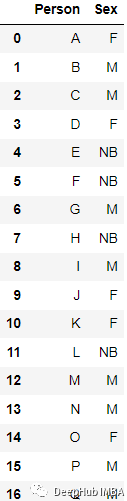
轉化后結果為

4、Leave one out Encoding
Leave One Out 編碼時,目標分類特征變量對具有相同值的所有記錄會被平均以確定目標變量的平均值。在訓練數據集和測試數據集之間,編碼算法略有不同。因為考慮到分類的特征記錄被排除在訓練數據集外,因此被稱為“Leave One Out”。
對特定類別變量的特定值的編碼如下。
例如下面的數據:

編碼后:

為了演示這個編碼過程,我們創建數據集:
然后進行編碼:
這樣就得到了上面的結果。
5、Hashing
當使用哈希函數時,字符串將被轉換為一個惟一的哈希值。因為它使用的內存很少可以處理更多的分類數據。對于管理機器學習中的稀疏高維特征,特征哈希是一種有效的方法。它適用于在線學習場景,具有快速、簡單、高效、快速的特點。
例如下面的數據:
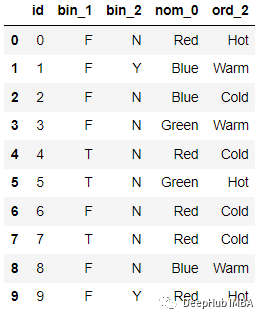
編碼后
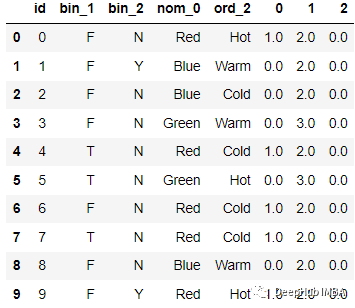
代碼如下:
6、Weight of Evidence Encoding
(WoE) 開發的主要目標是創建一個預測模型,用于評估信貸和金融行業的貸款違約風險。證據支持或駁斥理論的程度取決于其證據權重或 WOE。
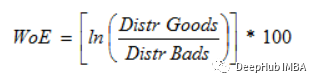
如果P(Goods) / P(Bads) = 1,則WoE為0。如果這個組的結果是隨機的,那么P(Bads) > P(Goods),比值比為1,證據的權重(WoE)為0。如果一組中P(Goods) > P(bad),則WoE大于0。
因為Logit轉換只是概率的對數,或ln(P(Goods)/P(bad)),所以WoE非常適合于邏輯回歸。當在邏輯回歸中使用wo編碼的預測因子時,預測因子被處理成與編碼到相同的尺度,這樣可以直接比較線性邏輯回歸方程中的變量。
例如下面的數據

會被編碼為:

代碼如下:
7、Helmert Encoding
Helmert Encoding將一個級別的因變量的平均值與該編碼中所有先前水平的因變量的平均值進行比較。
反向 Helmert 編碼是類別編碼器中變體的另一個名稱。它將因變量的特定水平平均值與其所有先前水平的水平的平均值進行比較。

會被編碼為

代碼如下:
8、Cat Boost Encoding
是CatBoost編碼器試圖解決的是目標泄漏問題,除了目標編碼外,還使用了一個排序概念。它的工作原理與時間序列數據驗證類似。當前特征的目標概率僅從它之前的行(觀測值)計算,這意味著目標統計值依賴于觀測歷史。

TargetCount:某個類別特性的目標值的總和(到當前為止)。
Prior:它的值是恒定的,用(數據集中的觀察總數(即行))/(整個數據集中的目標值之和)表示。
featucalculate:到目前為止已經看到的、具有與此相同值的分類特征的總數。

編碼后的結果如下:

代碼:
9、James Stein Encoding
James-Stein 為特征值提供以下加權平均值:
- 觀察到的特征值的平均目標值。
- 平均期望值(與特征值無關)。
James-Stein 編碼器將平均值縮小到全局的平均值。該編碼器是基于目標的。但是James-Stein 估計器有缺點:它只支持正態分布。
它只能在給定正態分布的情況下定義(實時情況并非如此)。為了防止這種情況,我們可以使用 beta 分布或使用對數-比值比轉換二元目標,就像在 WOE 編碼器中所做的那樣(默認使用它,因為它很簡單)。
10、M Estimator Encoding:
Target Encoder的一個更直接的變體是M Estimator Encoding。它只包含一個超參數m,它代表正則化冪。m值越大收縮越強。建議m的取值范圍為1 ~ 100。
11、 Sum Encoder
Sum Encoder將類別列的特定級別的因變量(目標)的平均值與目標的總體平均值進行比較。在線性回歸(LR)的模型中,Sum Encoder和ONE HOT ENCODING都是常用的方法。兩種模型對LR系數的解釋是不同的,Sum Encoder模型的截距代表了總體平均值(在所有條件下),而系數很容易被理解為主要效應。在OHE模型中,截距代表基線條件的平均值,系數代表簡單效應(一個特定條件與基線之間的差)。
最后,在編碼中我們用到了一個非常好用的Python包 “category-encoders”它還提供了其他的編碼方法,如果你對他感興趣,請查看它的官方文檔:
http://contrib.scikit-learn.org/category_encoders/