













常見Serialize技術(shù)探秘(XML、JSON、JDBC byte編碼、Protobuf)
目前業(yè)界有各種各樣的網(wǎng)絡輸出傳輸時的序列化和反序列化方案,它們在技術(shù)上的實現(xiàn)的初衷和背景有較大的區(qū)別,因此在設(shè)計的架構(gòu)也會有很大的區(qū)別,最終在落地后的:解析速度、對系統(tǒng)的影響、傳輸數(shù)據(jù)的大小、可維護性及可閱讀性等方面有著較大的區(qū)別,本文分享一些我在一些常見序列化技術(shù)的分析和理解:
文章分成3個部分:
1、列舉常見的序列化和反序列化方案(ObjectXXStream、XML、JSON)
2、MySQL JDBC結(jié)果集的處理方案
3、Google Protocol Buffer處理方案
【一、常見的在API及消息通信調(diào)的用中Serialize方案】:
方案1、基于Java原生的ObjectOutputStream.write()和ObjectInputStream.read()來進行對象序列化和反序列化。
方案2、基于JSON進行序列化和反序列化。
方案3、基于XML進行序列化和反序列化。
【方案1淺析,ObjectXXXStream】:
優(yōu)點:
(1)、由Java自帶API序列化,簡單、方便、無第三方依賴。
(2)、不用擔心其中的數(shù)據(jù)解析會丟失精度、丟失字段、Object的反序列化類型不確定等問題。
缺點:
(1)、雙方調(diào)試麻煩,發(fā)送方和接收方***是同版本的對象描述,否則會有奇怪的問題,調(diào)試周期相對長,跨團隊合作升級問題很多。
(2)、傳遞的對象中包含了元數(shù)據(jù)信息,占用空間較大。
【方案2淺析,JSON序列化】:
優(yōu)點:
(1)、簡單、方便,無需關(guān)注要序列化的對象格式。
(2)、開源界有較多的組件可以支持,例如FastJSON性能非常好。
(3)、在現(xiàn)在很多RPC的框架中,基本都支持這樣的方案。
缺點:
(1)、對象屬性中如果包含Object類型,在反序列化的時候如果業(yè)務也本身也不明確數(shù)據(jù)類型,處理起來會很麻煩。
(2)、由于文本類型,所以一定會占用較大的數(shù)據(jù)空間,例如下圖。
(3)、比較比較依賴于JSON的解析包的兼容性和性能,在JSON的一些細節(jié)處理上(例如一些非標的JSON),各自處理方式可能不一樣。
(4)、序列化無論任何數(shù)據(jù)類型先要轉(zhuǎn)換為String,轉(zhuǎn)成byte[],會增加內(nèi)存拷貝的次數(shù)。
(5)、反序列化的時候,必須將整個JSON反序列化成對象后才能進行讀取,大家應該知道,Java對象尤其是層次嵌套較多的對象,占用的內(nèi)存空間將會遠遠大于數(shù)據(jù)本身的空間。
數(shù)據(jù)放大的極端案例1:
傳遞數(shù)據(jù)描述信息為:
- class PP {
- long userId = 102333320132133L;
- int passportNumber = 123456;
- }
此時傳遞JSON的格式為:
- {
- "userId":102333320132133,
- "passportNumber":123456
- }
我們要傳遞的數(shù)據(jù)是1個long、1個int,也就是12個字節(jié)的數(shù)據(jù),這個JSON的字符串長度將是實際的字節(jié)數(shù)(不包含回車、空格,這里只是為了可讀性,同時注意,這里的long在JSON里面是字符串了),這個字符串有:51個字節(jié),也就是數(shù)據(jù)放到了4.25倍左右。
數(shù)據(jù)放大極端案例2:
當你的對象內(nèi)部有數(shù)據(jù)是byte[]類型,JSON是文本格式的數(shù)據(jù),是無法存儲byte[]的,那么要序列化這樣的數(shù)據(jù),只有一個辦法就是把byte轉(zhuǎn)成字符,通常的做法有兩種:
(1)使用BASE64編碼,目前JSON中比較常用的做法。
(2)按照字節(jié)進行16進制字符編碼,例如字符串:“FF”代表的是0xFF這個字節(jié)。
不論上面兩種做法的那一種,1個字節(jié)都會變成2個字符來傳遞,也就是byte[]數(shù)據(jù)會被放大2倍以上。為什么不用ISO-8859-1的字符來編碼呢?因為這樣編碼后,在最終序列化成網(wǎng)絡byte[]數(shù)據(jù)后,對應的byte[]雖然沒變大,但是在反序列化成文本的時候,接收方并不知道是ISO-8859-1,還會用例如GBK、UTF-8這樣比較常見的字符集解析成String,才能進一步解析JSON對象,這樣這個byte[]可能在編碼的過程中被改變了,要處理這個問題會非常麻煩。
【方案2淺析,XML序列化】:
優(yōu)點:
(1)、使用簡單、方便,無需關(guān)注要序列化的對象格式
(2)、可讀性較好,XML在業(yè)界比較通用,大家也習慣性在配置文件中看到XML的樣子
(3)、大量RPC框架都支持,通過XML可以直接形成文檔進行傳閱
缺點:
(1)、在序列化和反序列化的性能上一直不是太好。
(2)、也有與JSON同樣的數(shù)據(jù)類型問題,和數(shù)據(jù)放大的問題,同時數(shù)據(jù)放大的問題更為嚴重,同時內(nèi)存拷貝次數(shù)也和JSON類型,不可避免。
XML數(shù)據(jù)放大說明:
XML的數(shù)據(jù)放大通常比JSON更為嚴重,以上面的JSON案例來講,XML傳遞這份數(shù)據(jù)通常會這樣傳:
- <Msg>
- <userId>102333320132133</userId>
- <passportNumber>123456<passportNumber>
- <Msg>
這個消息就有80+以上的字節(jié)了,如果XML里面再搞一些Property屬性,對象再嵌套嵌套,那么這個放大的比例有可能會達到10倍都是有可能的,因此它的放大比JSON更為嚴重,這也是為什么現(xiàn)在越來越多的API更加喜歡用JSON,而不是XML的原因。
【放大的問題是什么】:
(1)、花費更多的時間去拼接字符串和拷貝內(nèi)存,占用更多的Java內(nèi)存,產(chǎn)生更多的碎片。
(2)、產(chǎn)生的JSON對象要轉(zhuǎn)為byte[]需要先轉(zhuǎn)成String文本再進行byte[]編碼,因為這本身是文本協(xié)議,那么自然再多一次內(nèi)存全量的拷貝。
(3)、傳輸過程由于數(shù)據(jù)被放大,占用更大的網(wǎng)絡流量。
(4)、由于網(wǎng)絡的package變多了,所以TCP的ACK也會變多,自然系統(tǒng)也會更大,同等丟包率的情況下丟包數(shù)量會增加,整體傳輸時間會更長,如果這個數(shù)據(jù)傳送的網(wǎng)絡延遲很大且丟包率很高,我們要盡量降低大小;壓縮是一條途徑,但是壓縮會帶來巨大的CPU負載提高,在壓縮前盡量降低數(shù)據(jù)的放大是我們所期望的,然后傳送數(shù)據(jù)時根據(jù)RT和數(shù)據(jù)大小再判定是否壓縮,有必要的時候,壓縮前如果數(shù)據(jù)過大還可以進行部分采樣數(shù)據(jù)壓縮測試壓縮率。
(5)、接收方要處理數(shù)據(jù)也會花費更多的時間來處理。
(6)、由于是文本協(xié)議,在處理過程中會增加開銷,例如數(shù)字轉(zhuǎn)字符串,字符串轉(zhuǎn)數(shù)字;byte[]轉(zhuǎn)字符串,字符串轉(zhuǎn)byte[]都會增加額外的內(nèi)存和計算開銷。
不過由于在平時大量的應用程序中,這個開銷相對業(yè)務邏輯來講簡直微不足道,所以優(yōu)化方面,這并不是我們關(guān)注的重點,但面臨一些特定的數(shù)據(jù)處理較多的場景,即核心業(yè)務在數(shù)據(jù)序列化和反序列化的時候,就要考慮這個問題了,那么下面我繼續(xù)討論問題。
此時提出點問題:
(1)、網(wǎng)絡傳遞是不是有更好的方案,如果有,為什么現(xiàn)在沒有大面積采用?
(2)、相對底層的數(shù)據(jù)通信,例如JDBC是如何做的,如果它像上面3種方案傳遞結(jié)果集,會怎么樣?
【二、MySQL JDBC數(shù)據(jù)傳遞方案】:
在前文中提到數(shù)據(jù)在序列化過程被放大數(shù)倍的問題,我們是否想看看一些相對底層的通信是否也是如此呢?那么我們以MySQL JDBC為例子來看看它與JDBC之間進行通信是否也是如此。
JDBC驅(qū)動程序根據(jù)數(shù)據(jù)庫不同有很多實現(xiàn),每一種數(shù)據(jù)庫實現(xiàn)細節(jié)上都有巨大的區(qū)別,本文以MySQL JDBC的數(shù)據(jù)解析為例(MySQL 8.0以前),給大家說明它是如何傳遞數(shù)據(jù)的,而傳遞數(shù)據(jù)的過程中,相信大家最為關(guān)注的就是ResultSet的數(shù)據(jù)是如何傳遞的。
拋開結(jié)果集中的MetaData等基本信息,單看數(shù)據(jù)本身:
(1)JDBC會讀取數(shù)據(jù)行的時候,首先會從緩沖區(qū)讀取一個row packege,row package就是從網(wǎng)絡package中拿到的,根據(jù)協(xié)議中傳遞過來的package的頭部判定package大小,然后從網(wǎng)絡緩沖中讀取對應大小的內(nèi)容,下圖想表達網(wǎng)絡傳遞的package和業(yè)務數(shù)據(jù)中的package之間可能并不是完全對應的。另外,網(wǎng)絡中的package如果都到了本地緩沖區(qū),邏輯上講它們是連續(xù)的(圖中故意分開是讓大家了解到網(wǎng)絡中傳遞是分不同的package傳遞到本地的),JDBC從本地buffer讀取row package這個過程就是內(nèi)核package到JVM的package拷貝過程,對于我們Java來講,我們主要關(guān)注row package(JDBC中可能存在一些特殊情況讀取過來的package并不是行級別的,這種特殊情況請有興趣的同學自行查閱源碼)。

(2)、單行數(shù)據(jù)除頭部外,就是body了,body部分包含各種各樣不同的數(shù)據(jù)類型,此時在body上放數(shù)據(jù)類型顯然是占空間的,所以數(shù)據(jù)類型是從metadata中提取的,body中數(shù)據(jù)列的順序?qū)蚼etdata中的列的順序保持一致。
(3)、MySQL詳細解析數(shù)據(jù)類型:
3.1、如果Metadata對應數(shù)據(jù)發(fā)現(xiàn)是int、longint、tinyint、year、float、double等數(shù)據(jù)類型會按照定長字節(jié)數(shù)讀取,例如int自然按照4字節(jié)讀取,long會按照8字節(jié)讀取。
3.2、如果發(fā)現(xiàn)是其它的類型,例如varchar、binary、text等等會按照變長讀取。
3.3、變長字符串首先讀取1個字節(jié)標志位。
3.4、如果這個標志位的值小于等于250,則直接代表后續(xù)字節(jié)的長度(注意字符串在這里是算轉(zhuǎn)換為字節(jié)的長度),這樣確保大部分業(yè)務中存放的變長字符串,在網(wǎng)絡傳遞過程中只需要1個字節(jié)的放大。
3.5、如果這個標志位是:251,代表這個字段為NULL
3.6、如果標志位是:252,代表需要2個字節(jié)代表字段的長度,此時加上標志位就是3個字節(jié),在65536以內(nèi)的長度的數(shù)據(jù)(64KB),注意,這里會在轉(zhuǎn)成long的時候高位補0,所以2個字節(jié)可以填滿到65536,只需要放大3個字節(jié)來表示這個數(shù)據(jù)。
3.7、如果標志位是:253,代表需要4個自己大表字段的長度,可以表示4GB(同上高位補0),這樣的數(shù)據(jù)幾乎不會出現(xiàn)在數(shù)據(jù)庫里面,即使出現(xiàn),只會出現(xiàn)5個字節(jié)的放大。
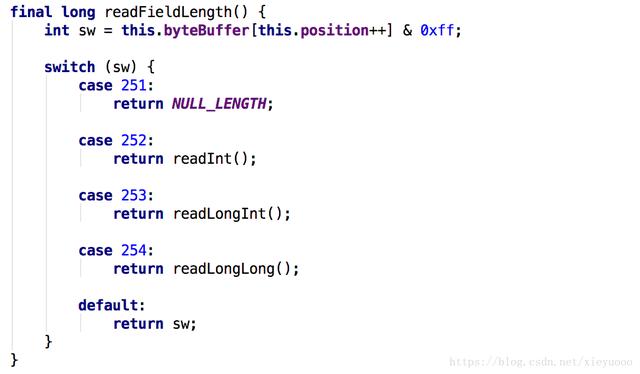
3.8、如果標志位是:254,8個字節(jié)代表長度,此時沒有高位補0,最多可以讀取Long.MAX_VALUE的長度,但是這個空間目前不可能有內(nèi)存放得下,所以無需擔心使用問題,此時9個字節(jié)的放大,源碼如下圖:
(4)、我們先按照這個理解,MySQL在傳遞數(shù)據(jù)的過程中,對數(shù)據(jù)的放大是很小很小的,是不是真的這樣呢?請下面第5點說明。
補充說明:
a、在MySQL JDBC中對于ResultSetRow數(shù)據(jù)的解析(除對MySQL 8.0以上JDBC版本)有2個實現(xiàn)類:BufferRow、ByteArrayRow,這兩種方式在讀取單行數(shù)據(jù)在解析這個階段是一樣的邏輯,只不過解析存放數(shù)據(jù)的方式有所不同,BufferRow一個會解析成數(shù)據(jù)行的byte[],ByteArrayRow會解析成byte[][]二維數(shù)組,第二維就是每1個列的信息,這都是客戶端行為,與網(wǎng)絡傳遞數(shù)據(jù)的格式無關(guān)。(兩者在不同場景下使用,例如其中一種場景是:ByteArrayRow在游標開啟UPDATE模式的時候會啟用,但這不是本文的重點,這里提到主要告知大家,無論哪一種方式,讀取數(shù)據(jù)的方式是一致的)
b、在MySQL JDBC中的RowData是ResultSet里面數(shù)據(jù)處理的入口,其實現(xiàn)類有3個:RowStatStatic、RowDataCursor、RowDataDynamic,這雖然有3個實現(xiàn)類,但是同樣不會影響數(shù)據(jù)的格式,它們只是從緩沖區(qū)讀取數(shù)據(jù)的方式有所不同:RowStatStatic、RowDataCursor會每次將緩沖區(qū)的數(shù)據(jù)全部讀取到JDBC當中形成數(shù)組,RowDataCursor在處理上有一個區(qū)別在于數(shù)據(jù)庫每次返回的是FetchSize大小的數(shù)據(jù)內(nèi)容(實現(xiàn)的細節(jié)在上一篇文章中有提到);RowDataDynamic是需要行的時候再從pakcege中去讀,package讀取完成后就嘗試讀取下一個package。這些都不會影響數(shù)據(jù)本身在網(wǎng)絡上的傳遞格式,所以文本提到的解析是目前MySQL JDBC比較通用的解析,與它內(nèi)部的執(zhí)行路徑無關(guān)。
(5)、以BufferRow為例,當你發(fā)起getString('xxx')、getDate(int)的時候,首先它需要在內(nèi)部找到是第幾個列(傳數(shù)字省略該動作),然后其內(nèi)部會有一個lastRequestedIndex、lastRequestedPos分別記錄***讀取的第幾個字段和所在字節(jié)的位置,如果你傳入的index比這個index大,則從當前位置開始,向后掃描,掃描規(guī)則和上面的數(shù)據(jù)庫寬度一致,找到對應位置,拷貝出對應的byte[]數(shù)組,轉(zhuǎn)換你要的對象類型。
PS:lastRequestedIndex、lastRequestedPos這種其實就是JDBC認為你絕大部分情況是從前向后讀取的,因此這樣讀取對JDBC程序也是最友好的方案,否則指針向前移動,需要從0開始,理由很簡單(數(shù)據(jù)的長度不是在尾部,而是在頭部),因此指針來回來回移動的時候,這樣會產(chǎn)生很多開銷,同時會產(chǎn)生更多的內(nèi)存拷貝出來的碎片。ByteArrayRow雖然可以解決這個問題,但是其本身會占用相對較大的空間另外,其內(nèi)部的二維數(shù)組返回的byte[]字節(jié)是可以被外部所修改的(因為沒有拷貝)。
另外,按照這種讀取數(shù)據(jù)的方式,如果單行數(shù)據(jù)過大(例如有大字段100MB+),讀取到Java內(nèi)存里面來,即使使用CursorFetch和Stream讀取,讀取幾十條數(shù)據(jù),就能把JVM內(nèi)存干掛掉。到目前為止,我還沒看到MySQL里面可以“設(shè)置限制單行數(shù)據(jù)長度”的參數(shù),后續(xù)估計官方支持這類特殊需求的可能性很小,大多也只能自己改源碼來實現(xiàn)。
【回到話題本身:MySQL和JDBC之間的通信似乎放大很小?】
其實不然,MySQL傳遞數(shù)據(jù)給JDBC默認是走文本協(xié)議的,而不是Binary協(xié)議,雖然說它的byte[]數(shù)組不會像JSON那樣放大,并不算真正意義上的文本協(xié)議,但是它很多種數(shù)據(jù)類型默認情況下,都是文本傳輸,例如一個上面提到的賬號:102333320132133在數(shù)據(jù)庫中是8個自己,但是網(wǎng)絡傳遞的時候如果有文本格式傳遞將會是:15個字節(jié),如果是DateTime數(shù)據(jù)在數(shù)據(jù)庫中可以用8個字節(jié)存放,但是網(wǎng)絡傳遞如果按照YYYY-MM-DD HH:MI:SS傳遞,可以達到19個字節(jié),而當他們用String在網(wǎng)絡傳遞的時候,按照我們前面提到的,MySQL會將其當成變長字符,因此會在數(shù)據(jù)頭部加上最少1個自己的標志位。另外,這里增加不僅僅是幾個字節(jié),而是你要取到真正的數(shù)據(jù),接收方還需要進一步計算處理才能得到,例如102333320132133用文本傳送后,接收方是需要將這個字符串轉(zhuǎn)換為long類型才能可以得到long的,大家試想一下你處理500萬數(shù)據(jù),每一行數(shù)據(jù)有20個列,有大量的類似的處理不是開銷增加了特別多呢?
JDBC和MySQL之間可以通過binary協(xié)議來進行通信的,也就是按照實際數(shù)字占用的空間大小來進行通信,但是比較坑的時,MySQL目前開啟Binary協(xié)議的方案是:“開啟服務端prepareStatemet”,這個一旦開啟,會有一大堆的坑出來,尤其是在互聯(lián)網(wǎng)的編程中,我會在后續(xù)的文章中逐步闡述。
拋開“開啟binary協(xié)議的坑”,我們認為MySQL JDBC在通信的過程中對數(shù)據(jù)的編碼還是很不錯的,非常緊湊的編碼(當然,如果你開啟了SSL訪問,那么數(shù)據(jù)又會被放大,而且加密后的數(shù)據(jù)基本很難壓縮)。
對比傳統(tǒng)的數(shù)據(jù)序列化優(yōu)劣勢匯總:
優(yōu)勢:
(1)、數(shù)據(jù)全部按照byte[]編碼后,由于緊湊編碼,所以對數(shù)據(jù)本身的放大很小。
(2)、由于編碼和解碼都沒有解析的過程,都是向ByteBuffer的尾部順序地寫,也就是說不用找位置,讀取的時候根據(jù)設(shè)計也可以減少找位置,即使找位置也是移動偏移量,非常高效。
(3)、如果傳遞多行數(shù)據(jù),反序列化的過程不用像XML或JSON那樣一次要將整個傳遞過來的數(shù)據(jù)全部解析后再處理,試想一下,如果5000行、20列的結(jié)果集,會產(chǎn)生多少Java對象,每一個Java對象對數(shù)據(jù)本身的放大又是多少,采用字節(jié)傳遞后可以按需轉(zhuǎn)變?yōu)镴ava對象,使用完的Java對象可以釋放,這樣就不用同時占用那樣大的JVM內(nèi)存,而byte[]數(shù)組也只是數(shù)據(jù)本身的大小,也可以按需釋放。
(4)、相對前面提到的3種方式,例如JSON,它不需要在序列化和反序列化的時候要經(jīng)歷一次String的轉(zhuǎn)換,這樣會減少一次內(nèi)存拷貝。
(5)、自己寫代碼用類似的通信方案,可以在網(wǎng)絡優(yōu)化上做到***。
劣勢:
(1)、編碼是MySQL和MySQL JDBC之間自定義的,別人沒法用(我們可以參考別人的思路)
(2)、byte編碼和解碼過程程序員自己寫,對程序員水平和嚴謹性要求都很高,前期需要大量的測試,后期在網(wǎng)絡問題上考慮稍有偏差就可能出現(xiàn)不可預期的Bug。(所以在公司內(nèi)部需要把這些內(nèi)容進行封裝,大部分程序員無需關(guān)注這個內(nèi)容)。
(3)、從內(nèi)存拷貝上來講,從rowBuffer到應用中的數(shù)據(jù),這一層內(nèi)存拷貝是無法避免的,如果你寫自定義程序,在必要的條件下,這個地方可以進一步減少內(nèi)存拷貝,但無法杜絕;同上文中提到,這點開銷,對于整個應用程序的業(yè)務處理來講,簡直微不足道。
為什么傳統(tǒng)通信協(xié)議不選擇這樣做:
(1)、參考劣勢中的3點。
(2)、傳統(tǒng)API通信,我們更講究快速、通用,也就是會經(jīng)常和不同團隊乃至不同公司調(diào)試代碼,要設(shè)計binary協(xié)議,開發(fā)成本和調(diào)試成本非常高。
(3)、可讀性,對于業(yè)務代碼來講,byte[]的可讀性較差,尤其是對象嵌套的時候,byte[]表達的方式是很復雜的。
MySQL JDBC如果用binary協(xié)議后,數(shù)據(jù)的緊湊性是不是達到***了呢?
按照一般的理解,就是達到***了,所有數(shù)據(jù)都不會進一步放大,int就只用4個字節(jié)傳遞,long就只用8個字節(jié)傳遞,那么還能繼續(xù)變小,難道壓縮來做?
非也、非也,在二進制的世界里,如果你探究細節(jié),還有更多比較神奇的東西,下面我們來探討一下:
例如:
- long id = 1L;
此時網(wǎng)絡傳遞的時候會使用8個字節(jié)來方,大家可以看下8個字節(jié)的排布:
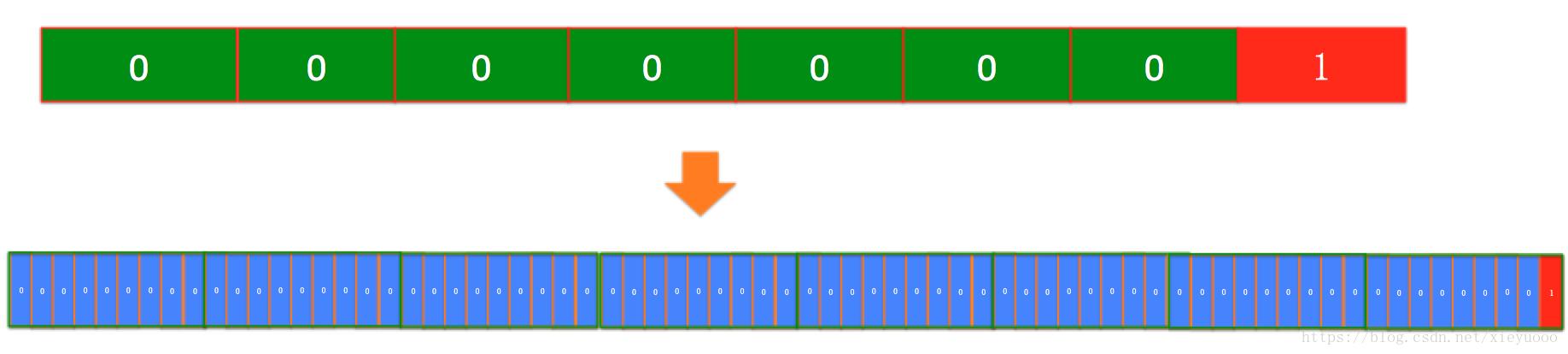
我們先不考慮按照bit有31個bit是0,先按照字節(jié)來看有7個0,代表字節(jié)沒有數(shù)據(jù),只有1個字節(jié)是有值的,大家可以去看一下自己的數(shù)據(jù)庫中大量的自動增長列,在id小于4194303之前,前面5個字節(jié)是浪費掉的,在增長到4個字節(jié)(2的32次方-1)之前前面4個自己都是0,浪費掉的。另外,即使8個字節(jié)中的***個字節(jié)開始使用,也會有大量的數(shù)據(jù),中間字節(jié)是為:0的概率極高,就像十進制中進入1億,那么1億下面最多會有8個0,越高位的0約難補充上去。
如果真的想去嘗試,可以用這個辦法:用1個字節(jié)來做標志,但會占用一定的計算開銷,所以是否為了這個空間去做這個事情,由你決定,本文僅僅是技術(shù)性探討:
方法1:表達目前有幾個低位被使用的字節(jié)數(shù),由于long只有8個字節(jié),所以用3個bit就夠了,另外5個bit是浪費掉的,也無所謂了,反序列化的時候按照高位數(shù)量補充0x00即可。
方法2:相對方法1,更徹底,但處理起來更復雜,用1這個字節(jié)的8個bit的0、1分別代表long的8個字節(jié)是被使用,序列化和反序列化過程根據(jù)標志位和數(shù)據(jù)本身進行字節(jié)補0x00操作,補充完整8個字節(jié)就是long的值了,最壞情況是9個字節(jié)代表long,***情況0是1個字節(jié),字節(jié)中只占用了2個字節(jié)的時候,即使數(shù)據(jù)變得相當大,也會有大量的數(shù)據(jù)的字節(jié)存在空位的情況,在這些情況下,就通常可以用少于8個字節(jié)的情況來表達,要用滿7個字節(jié)才能夠與原數(shù)字long的占用空間一樣,此時的數(shù)據(jù)已經(jīng)是比2的48次方-1更大的數(shù)據(jù)了。
【三、Google Protocol Buffer技術(shù)方案】:
這個對于很多人來講未必用過,也不知道它是用來干什么的,不過我不得不說,它是目前數(shù)據(jù)序列化和反序列化的一個神器,這個東西是在谷歌內(nèi)部為了約定好自己內(nèi)部的數(shù)據(jù)通信設(shè)計出來的,大家都知道谷歌的全球網(wǎng)絡非常牛逼,那么自然在數(shù)據(jù)傳輸方面做得那是相當***,在這里我會講解下它的原理,就本身其使用請大家查閱其它人的博客,本文篇幅所限沒法step by step進行講解。
看到這個名字,應該知道是協(xié)議Buffer,或者是協(xié)議編碼,其目的和上文中提到的用JSON、XML用來進行RPC調(diào)用類似,就是系統(tǒng)之間傳遞消息或調(diào)用API。但是谷歌一方面為了達到類似于XML、JSON的可讀性和跨語言的通用性,另一方面又希望達到較高的序列化和反序列化性能,數(shù)據(jù)放大能夠進行控制,所以它又希望有一種比底層編碼更容易使用,而又可以使用底層編碼的方式,又具備文檔的可讀性能力。
它首先需要定義一個格式文件,如下:
- syntax = "proto2";
- package com.xxx.proto.buffer.test;
- message TestData2 {
- optional int32 id = 2;
- optional int64 longId = 1;
- optional bool boolValue = 3;
- optional string name = 4;
- optional bytes bytesValue = 5;
- optional int32 id2 = 6;
- }
這個文件不是Java文件,也不是C文件,和語言無關(guān),通常把它的后綴命名為proto(文件中1、2、3數(shù)字代表序列化的順序,反序列化也會按照這個順序來做),然后本地安裝了protobuf后(不同OS安裝方式不同,在官方有下載和說明),會產(chǎn)生一個protoc運行文件,將其加入環(huán)境變量后,運行命令指定一個目標目錄:
- protoc --java_out=~/temp/ TestData2.proto
此時會在指定的目錄下,產(chǎn)生package所描述的目錄,在其目錄內(nèi)部有1個Java源文件(其它語言的會產(chǎn)生其它語言),這部分代碼是谷歌幫你生成的,你自己寫的話太費勁,所以谷歌就幫你干了;本地的Java project里面要引入protobuf包,maven引用(版本自行選擇):
- <dependency>
- <groupId>com.google.protobuf</groupId>
- <artifactId>protobuf-java</artifactId>
- <version>3.6.1</version>
- </dependency>
此時生成的代碼會調(diào)用這個谷歌包里面提供的方法庫來做序列化動作,我們的代碼只需要調(diào)用生成的這個類里面的API就可以做序列化和反序列化操作了,將這些生成的文件放在一個模塊里面發(fā)布到maven倉庫別人就可以引用了,關(guān)于測試代碼本身,大家可以參考目前有很多博客有提供測試代碼,還是很好用的。
谷歌編碼比較神奇的是,你可以按照對象的方式定義傳輸數(shù)據(jù)的格式,可讀性極高,甚至于相對XML和JSON更適合程序員閱讀,也可以作為交流文檔,不同語言都通用,定義的對象還是可以嵌套的,但是它序列化出來的字節(jié)比原始數(shù)據(jù)只大一點點,這尼瑪太厲害了吧。
經(jīng)過測試不同的數(shù)據(jù)類型,故意制造數(shù)據(jù)嵌套的層數(shù),進行二進制數(shù)組多層嵌套,發(fā)現(xiàn)其數(shù)據(jù)放大的比例非常非常小,幾乎可以等價于二進制傳輸,于是我把序列化后的數(shù)據(jù)其二進制進行了輸出,發(fā)現(xiàn)其編碼方式非常接近于上面的JDBC,雖然有一些細節(jié)上的區(qū)別,但是非常接近,除此之外,它在序列化的時候有幾大特征:
(1)、如果字段為空,它不會產(chǎn)生任何字節(jié),如果整合對象的屬性都為null,產(chǎn)生的字節(jié)將是0
(2)、對int32、int64這些數(shù)據(jù)采用了變長編碼,其思路和我們上面描述有一些共通之處,就是一個int64值在比較小的時候用比較少的字節(jié)就可以表達了,其內(nèi)部有一套字節(jié)的移位和異或算法來處理這個事情。
(3)、它對字符串、byte[]沒有做任何轉(zhuǎn)換,直接放入字節(jié)數(shù)組,和二進制編碼是差不多的道理。
(4)、由于字段為空它都可以不做任何字節(jié),它的做法是有數(shù)據(jù)的地方會有一個位置編碼信息,大家可以嘗試通過調(diào)整數(shù)字順序看看生成出來的byte是否會發(fā)生改變;那么此時它就有了很強兼容性,也就是普通的加字段是沒問題的,這個對于普通的二進制編碼來講很難做到。
(5)、序列化過程沒有產(chǎn)生metadata信息,也就是它不會把對象的結(jié)構(gòu)寫在字節(jié)里面,而是反序列化的接收方有同一個對象,就可以反解析出來了。
這與我自己寫編碼有何區(qū)別?
(1)、自己寫編碼有很多不確定性,寫不好的話,數(shù)據(jù)可能放得更大,也容易出錯。
(2)、google的工程師把內(nèi)部規(guī)范后,谷歌開源的產(chǎn)品也大量使用這樣的通信協(xié)議,越來越多的業(yè)界中間件產(chǎn)品開始使用該方案,就連MySQL數(shù)據(jù)庫***版本在數(shù)據(jù)傳輸方面也會開始兼容protobuf。
(3)、谷歌相當于開始在定義一個業(yè)界的新的數(shù)據(jù)傳輸方案,即有性能又降低代碼研發(fā)的難度,也有跨語言訪問的能力,所以才會有越來越多的人喜歡使用這個東西。
那么它有什么缺點呢?還真不多,它基本兼顧了很多序列化和反序列化中你需要考慮的所有的事情,達到了一種非常良好的平衡,但是硬要挑缺陷,我們就得找場景才行:
(1)、protobuf需要雙方明確數(shù)據(jù)類型,且定義的文件中每一個對象要明確數(shù)據(jù)類型,對于Object類型的表達沒有方案,你自己必須提前預知這個Object到底是什么類型。
(2)、使用repeated可以表達數(shù)組,但是只能表達相同類型的數(shù)據(jù),例如上面提到的JDBC一行數(shù)據(jù)的多個列數(shù)據(jù)類型不同的時候,要用這個表達,會比較麻煩;另外,默認情況下數(shù)組只能表達1維數(shù)組,要表達二維數(shù)組,需要使用對象嵌套來間接完成。
(3)、它提供的數(shù)據(jù)類型都是基本數(shù)據(jù)類型,如果不是普通類型,要自己想辦法轉(zhuǎn)換為普通類型進行傳輸,例如從MongoDB查處一個Docment對象,這個對象序列化是需要自己先通過別的方式轉(zhuǎn)換為byte[]或String放進去的,而相對XML、JSON普通是提供了遞歸的功能,但是如果protobuf要提供這個功能,必然會面臨數(shù)據(jù)放大的問題,通用和性能永遠是矛盾的。
(4)、相對于自定義byte的話,序列化和反序列化是一次性完成,不能逐步完成,這樣如果傳遞數(shù)組嵌套,在反序列化的時候會產(chǎn)生大量的Java對象,另外自定義byte的話可以進一步減少內(nèi)存拷貝,不過谷歌這個相對文本協(xié)議來講內(nèi)存拷貝已經(jīng)少很多了。
補充說明:
在第2點中提到repeated表達的數(shù)組,每一個元素必須是同類型的,無法直接表達不同類型的元素,因為它沒有像Java那樣Object[]這樣的數(shù)組,這樣它即使通過本地判定Object的類型傳遞了,反序列化會很麻煩,因為接收方也不知道數(shù)據(jù)是什么類型,而protobuf網(wǎng)絡傳遞數(shù)據(jù)是沒有metadata傳遞的,那么判定唯一的地方就是在客戶端自己根據(jù)業(yè)務需要進行傳遞。
因此,如果真的有必要的話,可以用List。
總之,每一種序列化和反序列化方案目前都有應用場景,它們在設(shè)計之初決定了架構(gòu),也將決定了最終的性能、穩(wěn)定性、系統(tǒng)開銷、網(wǎng)絡傳輸大小等等。














