ClickHouse在自助行為分析場景的實踐應用
導讀
公司每日產生海量數據,按業務需要進行統計產出各類分析報表,但巨大的數據量加上復雜的數據模型,以及個性化的分析維度,采用傳統的離線預計算方式難以靈活支持,為此需引入一種滿足實時多維分析場景的計算引擎框架來支撐業務精細化運營場景。本文將分享ClickHouse在自助分析場景中的探索及實踐,文章將從以下4個方面介紹:
- 自助分析場景OLAP技術選型
- 高斯平臺自助分析場景
- ClickHouse的優化實踐
- ClickHouse未來的規劃與展望
一、自助分析場景OLAP技術選型
1.1 背景

轉轉平臺主要對業務運營數據(埋點)進行分析,埋點數據包含在售商品的曝光、點擊、展現等事件,覆蓋場景數據量很大,且在部分分析場景需要支持精確去重。大數據量加上去重、數據分組等計算使得指標在統計過程中運算量較大。除此之外,在一些數據分析場景中需要計算留存率、漏斗轉化等復雜的數據模型。
雖然在離線數倉的數倉分層和匯總層對通用指標做了預計算處理,但由于這些模型的分析維度通常是不確定的,因此預計算無法滿足產品或者運營提出的個性化報表的需求,需分析師或數倉工程師進行sql開發,使得數據開發鏈路長交付慢,數據價值也隨著時間的推移而減少。
作為分析平臺,既需要保證數據時效性、架構的高可用,也要做到任意維度、任意指標的秒級響應。基于以上情況,需要一個即席查詢的引擎來實現。
1.2 OLAP選型考量

轉轉對OLAP引擎選型考量有三個方面:性能,靈活性,復雜性。
- 性能:
數據量級(億級/百億級/千億級等)
數據計算反饋時效性(毫秒級/秒級/分鐘級)
- 靈活性:
能否支持聚合結果或明細數據的查詢,還是兩者都支持
數據鏈路能否支持離線數據和實時數據的攝取
是否支持高并發的即席查詢
- 復雜性:
架構簡單
使用門檻低
運維難度低
擴展性強
根據這三個方面的考量,調研了目前主流的幾類開源OLAP引擎:

OLAP引擎主要分為兩大類:
- 基于預計算的MOLAP引擎的優勢是對整個計算結果做了預計算,查詢比較穩定,可以保證查詢結果亞秒級或者是秒級響應。但由于依賴預計算,查詢的靈活性比較弱,無法統計預計算外的數據,代表是Kylin和Druid。
- 基于MPP架構的ROLAP引擎可以支持實時數據的攝入和實時分析,查詢場景靈活,但查詢穩定性較弱,取決于運算的數據量級和資源配比,基于MPP架構的OLAP一般都是基于內存的,代表是Impala和Presto。
Kylin采用的技術是完全預聚合立方體,能提供較好的SQL支持以及join能力,查詢速度基本上都是亞秒級響應。同時,Kylin有良好的web管理界面,可以監控和使用立方體。但當維度較多,交叉深度較深時,底層的數據會爆炸式的膨脹。而且Kylin的查詢靈活性比較弱,這也是MOLAP引擎普遍的弱點。
Druid采用位圖索引、字符串編碼和預聚合技術,可以對數據進行實時攝入,支持高可用高并發的查詢,但是對OLAP引擎的分析場景支持能力比較弱,join的能力不成熟,無法支持需要做精確去重計算的場景。
Impala支持窗口函數和UDF,查詢性能比較好,但對內存的依賴較大,且Impala的元數據存儲在Hive Metastore里,需要與Hadoop組件緊密的結合,對實時數據攝入一般要結合Kudu這類存儲引擎做DML操作,多系統架構運維也比較復雜。
Presto可跨數據源做聯邦查詢,能支持多表的join,但在高并發的場景下性能較弱的。

ClickHouse單機性能很強,基于列式存儲,能利用向量化引擎做到并行化計算,查詢基本上是毫秒級或秒級的反饋,但ClickHouse沒有完整的事務支持,對分布式表的join能力較弱。
Doris運維簡單,擴縮容容易且支持事務,但Doris版本更新迭代較快且成熟度不夠,也沒有像ClickHouse自帶的一些函數如漏斗、留存,不足以支撐轉轉的業務場景。
基于以上考量,最終選擇了ClickHouse作為分析引擎。
1.3 ClickHouse
ClickHouse是面向實時聯機分析處理的基于列式存儲的開源分析引擎,是俄羅斯于2016年開源的,底層開發語言為C++,可以支撐PB數據量級的分析。ClickHouse有以下特性:
- 具有完備的dbms功能,SQL支持較為完善。
- 基于列式存儲和數據壓縮,支持索引。
- 向量化引擎與SIMD提高CPU的利用率,多核多節點并行執行,可基于較大的數據集計算,提供亞秒級的查詢響應。
- 支持數據復制和數據完整性。
- 多樣化的表引擎。ClickHouse支持Kafka、HDFS等外部數據查詢引擎,以及MergeTree系列的引擎、Distribute分布式表引擎。

ClickHouse的查詢場景主要分為四大類:
- 交互式報表查詢:可基于ClickHouse構建用戶行為特征寬表,對于多維度,多指標的計算能秒級給出計算反饋。
- 用戶畫像系統:在ClickHouse里面構建用戶特征寬表,支持用戶細查、人群圈選等。
- AB測試:利用ClickHouse的高效存儲和它提供的一些自帶的函數,如grouparray函數,可以做到秒級給出AB實驗的效果數據。
- 監控系統:通過Flink實時采集業務指標、系統指標數據,寫到ClickHouse,可以結合Grafana做指標顯示。
二、高斯平臺自助分析場景
2.1 系統介紹

轉轉高斯平臺的核心功能主要包含兩個部分:
- 埋點數據管理:埋點元數據管理,埋點元數據質量監控和告警;
- 自助分析:基于業務特點和多部門復合需求,提供多維度、多指標的交叉分析能力,可以支持用戶畫像標簽選擇、人群圈選,AB TEST等分析功能,全面支撐日常數據分析需求。
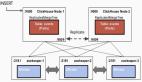
2.2 系統架構
下圖展示了高斯平臺的系統架構,總共分為四層:

?數據采集層:數據來源主要是業務庫和埋點數據。業務庫數據存儲在MySQL里,埋點數據通常是LOG日志。MySQL業務庫的數據通過Flink-CDC實時抽取到Kafka;LOG日志由Flume Agent采集并分發到實時和離線兩條通道,實時埋點日志會sink寫入Kafka,離線的日志sink到HDFS。
數據存儲層:主要是對數據采集層過來的數據進行存儲,存儲采用的是Kafka和HDFS,ClickHouse基于底層數據清洗和數據接入,實現寬表存儲。
數據服務層:對外統一封裝的HTTP服務,由外部系統調用,對內提供了SQL化的客戶端工具。
數據應用層:主要是基于ClickHouse的高斯自助分析平臺和用戶畫像平臺兩大產品。高斯分析平臺可以對于用戶去做事件分析,計算PV、UV等指標以及留存、LTV、漏斗分析、行為分析等,用戶畫像平臺提供了人群的圈選、用戶細查等功能。
2.3 ClickHouse在高斯平臺的業務場景
(1)行為分析

業務背景:App上線活動專題頁,業務方想查看活動頁面上線后各個坑位的點擊的效果。
技術實現:采用ClickHouse的物化視圖、聚合表引擎,以及明細表引擎。ClickHouse的物化視圖可以做實時的數據累加計算,POPULATE關鍵詞決定物化視圖的更新策略。在創建物化視圖時使用POPULATE關鍵詞會對底層表的歷史數據做物化視圖的計算。
技術實現:采用ClickHouse的物化視圖、聚合表引擎,以及明細表引擎。ClickHouse的物化視圖可以做實時的數據累加計算,POPULATE關鍵詞決定物化視圖的更新策略。在創建物化視圖時使用POPULATE關鍵詞會對底層表的歷史數據做物化視圖的計算。
(2)AB-TEST分析

業務背景:轉轉早期AB-TEST采用傳統的T+1日數據,但T+1日數據已無法滿足業務需求。
技術方案:Flink實時消費Kafka,自定義Sink(支持配置自定義Flush批次大小、時間)到ClickHouse,利用ClickHouse做實時指標的計算。
三、ClickHouse的優化實踐
3.1 內存優化

在數據分析過程中常見的問題大都是和內存相關的。如上圖所示,當內存使用量大于了單臺服務器的內存上限,就會拋出該異常。
針對這個問題,需要對SQL語句和SQL查詢的場景進行分析:
- 如果是在進行count和disticnt計算時內存不足,可以使用一些預估函數減少內存的使用量來提升查詢速度;
- 如果SQL語句進行了group by或者是order by操作,可以配置max_bytes_before_external_group_by和max_bytes_before_external_sort這兩個參數調整。
3.2 性能調優參數

上圖是實踐的一些優化參數,主要是限制并發處理的請求數和限制內存相關的參數。
- max_concurrent_queries:限制每秒的并發請求數,默認值100,轉轉調整參數值為150。需根據集群性能以及節點的數量來調整此參數值。
- max_memory_usage:設置單個查詢單臺機器的最大內存使用量,建議設置值為總內存的80%,因為需要預留一些內存給系統os使用。
- max_memory_usage_for_all_queries:設置單服務器上查詢的最大內存量,建議設置為總內存的80%~90%。
- max_memory_usage_for_user & max_bytes_before_external_sort:group by和order by使用超出內存的閾值后,預寫磁盤進行group by或order by操作。
- background_pool_size:后臺線程池的大小,默認值為16,轉轉調整為32。這個線程池大小包含了后臺merge的線程數,增大這個參數值是有利于提升merge速度的。
3.3 億級數據JOIN

技術原理:在做用戶畫像數據和行為數據導入的時候,數據已經按照Join Key預分區了,相同的Join Key其實是在同一節點上,因此不需要去做兩個分布式表跨節點的Join,只需要去Join本地表就行,執行過程中會把具體的查詢邏輯改為本地表,Join本地表之后再匯總最后的計算結果,這樣就能得到正確的結果。
四、ClickHouse未來的規劃與展望
4.1 ClickHouse應用實踐痛點

- ClickHouse的高并發能力特別弱,官方的建議的QPS是每秒100左右。高并發查詢時,ClickHouse性能下降比較明顯。
- ClickHouse不支持事務性的DDL和其他的分布式事務,復制表引擎的數據同步的狀態和分片的元數據管理都強依賴于Zookeeper。
- 部分應用場景需要做到實時的行級數據update和delete操作,ClickHouse缺少完整的操作支持。
- ClickHouse缺少自動的re-balance機制,擴縮容時數據遷移需手動均衡。
4.2 未來規劃及展望

- 服務平臺化,故障規范化。提高業務易用性,提升業務治理,比如:資源的多租戶隔離,異常用戶的限流熔斷,以及對ClickHouse精細化監控報警,包括一些慢查詢監控。
- ClickHouse容器化的部署。支持數據的存算分離,更好的彈性集群擴縮容,擴縮容后自動數據均衡。
- 服務架構智能化。針對部分業務場景的高并發查詢,ClickHouse本身的支持高并發能力比較弱,引入Doris引擎。基于特定的業務場景去自適應的選擇ClickHouse或者是Doris引擎。
- ClickHouse內核級的優化。包括實時寫入一致性保證、分布式事務支持、移除Zookeeper的服務依賴。目前Zookeeper在ClickHouse數據達到一定量級是存在瓶頸的,所以移除Zookeeper服務依賴是迫切和必然的。
五、總結
本文主要分享了:
- OLAP分析領域技術生態
- 轉轉自助分析平臺的底層架構原理
- ClickHouse在落地實踐過程中的調優方案
- ClickHouse應用痛點及未來規劃和展望
在巨大的數據量面前,想追求極致的性能及全部場景適應性,必須在某些技術方案上進行取舍。ClickHouse從底層列式存儲到上層向量化并行計算,都沒有考慮存算分離、彈性擴展的技術方案,甚至于橫向擴容數據需要手動re-balance。因此,如果要實現云上的可動態伸縮、存算分離,ClickHouse需要重構底層代碼。
未來轉轉會針對痛點進行持續優化,輸出更多的技術實踐給大家。