基于機器學習的用戶實體行為分析技術在賬號異常檢測中的應用
伴隨企業業務的不斷擴增和電子化發展,企業自身數據和負載數據都開始暴增。然而,作為企業核心資產之一的內部數據,卻面臨著日益嚴峻的安全威脅。越來越多以周期長、頻率低、隱蔽強為典型特征的非明顯攻擊繞過傳統安全檢測方法,對大量數據造成損毀。
當前,用戶實體行為分析(User and Entity Behavior Analytics,UEBA)系統正作為一種新興的異常用戶檢測體系在逐步顛覆傳統防御手段,開啟網絡安全保衛從“被動防御”到“主動出擊”的新篇章。因此,將主要介紹UEBA在企業異常用戶檢測中的應用情況。
首先,通過用戶、實體、行為三要素的關聯,整合可以反映用戶行為基線的各類數據;其次,定義4類特征提取維度,有效提取幾十種最能反映用戶異常的基礎特征;再次,將3種異常檢測算法通過集成學習方法用于異常用戶建模;最后,通過異常打分,定位異常風險最大的一批用戶。
在實踐中,對排名前10的異常用戶進行排查,證明安恒信息的UEBA落地方式在異常用戶檢測中極其高效。隨著互聯網技術的日益發展和國家在大數據戰略層面的深化推動,數據采集終端越來越多,收錄的種類越來越豐富,數據已經成為企業重要乃至最核心的資產之一。
在數據價值受到高度重視的同時,企業面臨的各種針對數據安全威脅的問題也愈發嚴重,信息安全保障逐漸聚焦為數據的安全保障。通常情況下,外部攻擊種類繁多、持續高頻,企業習慣于將資源布置于構筑安全防護堡壘,以抵御來自外部的進攻。然而,除了外部的黑客攻擊,內部人員參與信息販賣、共享第三方的違規泄露事件也層出不窮。
調查顯示,約有75%的安全威脅是從組織內部發起的。無論是離職員工順走專利數據,還是心懷怨恨的員工蓄意破壞系統,一再發生的各種安全事件證明,攻破堡壘的最容易的方式往往來自內部威脅。面對這種威脅,內外雙向的安全需求催生了用戶實體行為分析(User and Entity Behavior Analytics,UEBA)。對內,傳統威脅防御手段不足。對于已經意識到問題緊迫性的企業而言,使用傳統的安全技術并未能幫助他們有效解決來自內部的安全問題。
原因在于傳統方法多為分散的、事后的、缺少針對性的。安全最薄弱的環節是人,只有建立以用戶為核心對象的分析體系,才能更加及時發現和終止內部威脅,杜絕信息泄漏于萌芽狀態。對外,市場需求推動技術更新。
作為一種高級網絡威脅檢測手段,UEBA發展迅速,甚至正在顛覆原有市場格局。UEBA是基于大數據驅動、以用戶為核心、關聯實體資產、采用機器學習算法進行異常分析以發現解決內部威脅的一套框架和體系。
相較于傳統手段對安全事件的關注,UEBA更關心人,通過用戶畫像和資產畫像,檢測諸如賬號失陷、主機失陷、數據泄漏、權限濫用等風險,以極高的準確率定位異常用戶。
1 企業員工賬號的關聯
UEBA本質上屬于數據驅動的安全分析技術,需要采集大量而廣泛的用戶行為類數據。大數據時代,數據是一切分析的基礎,少量的或者質量不高的輸入必然導致價值不高的輸出。然而,這并不意味著數據純粹的越多越好,與場景不相關的數據,過多收集只會增加系統負擔。
所以,行為分析的基礎是數據,數據采集的前提是場景,采集的數據要和分析的特定場景相匹配,高質量多種類的數據是用戶實體行為分析的核心。用戶實體行為分析可以使用的數據,包括安全日志、網絡流量、威脅情報以及身份訪問相關日志等,盡可能多地接入和用戶場景相關的數據,常見如VPN日志、OA日志、員工卡消費日志以及門禁刷臉日志等。
可以將這些數據大致歸納為用戶身份數據、實體身份數據和用戶行為數據3種類型。用戶身份數據分為兩類:一類是真實身份數據,如人事部門提供的員工資料;一類是虛擬身份數據,如用戶在網絡上的注冊資料。由于UEBA嚴重依賴高質量數據,使得企業需要有數據治理的基礎能力,需要有統一的數據字典。
通過統一數據字典,可以統一不同日志的字段信息,進而關聯不同日志的用戶信息,通過關聯真實身份與虛擬身份,達到定位具體的用戶的目標。實體身份數據是網絡中用戶的唯一身份標識,如IP地址、MAC地址等。用戶行為數據分類則可分為網絡行為信息和終端行為信息。
2 員工賬號與實體資產的關聯
員工賬號與實體資產的關聯,即用戶身份數據與實體身份數據的關聯,它們通過用戶行為數據實現關聯。例如,某用戶登錄VPN,通過登錄日志的用戶信息相關字段,可以定位用戶的身份信息。用戶使用VPN訪問公司內網,通過訪問日志的目標地址信息相關字段,可以定位實體資產的身份信息,獲取會話期間終端日志信息,同時也實現員工賬號與實體資產的關聯。
訪問日志的獲取有多種形式,可以是VPN設備自身記錄的日志,也可以是其他安全設備的記錄日志,如深度包檢測(Deep Packet Inspection,DPI)系統日志。所謂“深度”是和普通的報文分析層次相比較而言的。
“普通報文檢測”僅分析IP包4層以下(物理層、數據鏈路層、網絡層、傳輸層)的內容,包括源地址、目的地址、源端口、目的端口以及協議類型。而DPI除了對前面的4層進行分析外,還增加了應用層等其他層的分析,識別各種應用及其內容。DPI系統提供的審計信息、應用程序會話識別信息、應用程序會話流量統計信息、網絡傳輸層流量統計信息、應用層流量統計信息等,可以極大豐富用戶網絡行為信息。終端日志可以通過終端檢測與響應(Endpoint Detection and Response,EDR)系統獲取。
EDR日志可以幫助采集終端的內存操作、磁盤操作、文件操作、系統調用、端口調用、網絡操作、注冊表操作等,通過分析進程行為、應用行為以及服務行為等,補全用戶終端行為信息。通過用戶網絡行為與終端行為等信息整合,可以完成用戶與實體的關聯,同時也完整地還原了用戶的網絡會話和會話期間的用戶行為,為后期的行為分析提供高質量的數據素材。
3 基礎特征提取
用戶行為特征提取是整個用戶行為分析建模的基礎,需結合業務實際需求,找出相關的數據實體,以數據實體為中心,規約數據維度類型和關聯關系,形成符合業務實際情況的建模體系。一般的特征提取步驟包括用戶數據與實體數據的分解和對應、實體間關聯關系分解、用戶特征維度分解以及用戶行為特征的提取。
相比算法層面的精進,有效提取數據特征經常會取得更直接的收益,能夠展現數據的基本屬性和業務邏輯的特性,甚至僅需要使用簡單的模型就能取得很好的結果,而冗余的無邏輯特征不僅無益于建模,甚至會降低分析的精度與速度。在特征提取的設計中,專家知識至關重要。經驗往往是取得成果的捷徑,但是在實際情況中總會遇到一些陌生的場景,缺少經驗知識,這時邏輯和方法論顯得更為普適。
通常采用4類通用的維度來提取用戶行為特征,分別是用戶與用戶之間行為基線的對比、用戶組與用戶組之間行為基線的對比、基于用戶自身行為基線對比的離散數據特征提取和基于用戶自身行為基線對比的連續數據特征提取。第1類維度是用戶與用戶之間行為基線的對比。
基于大部分用戶行為是正常的原則,通過用戶與用戶之間的行為基線對比,可以發現偏離集群基線的少數用戶。在某一個特征維度上,這些少數用戶就是疑似異常的。典型事件為非工作時間的用戶行為異常。
通常情況下,員工對公司內部資源的訪問應該在工作時間,任何非工作時間的行為都應該重點關注。那么,如何定義非工作時間呢?不同行業不同性質的企業,工作時間會有較大差別。國企與民企、傳統產業與新興產業,工作時間段上存在比較大的偏差。
此外,同一領域的不同企業也有各自的加班文化,不能排除很多員工在考勤外時間通過VPN訪問內網是用于正常工作的可能。因此,基于對所有員工的歷史行為記錄,通過核密度估計(Kernel Density Estimation,KDE)計算一天24 h每個時間點用戶訪問資源的概率密度,將概率低于動態閾值的時間點定義為非工作時間,從而把員工在非工作時間段產生的行為提取為一個異常特征。
圖1為某公司的員工賬號24 h在線概率密度分布圖,可得賬號在白天工作時間在線的概率最大。當動態閾值為0.01時,可以看出該公司的員工在凌晨3點到凌晨6點的在線概率最小。在凌晨0點到凌晨3點,該公司還有部分員工在使用VPN加班工作,說明該公司加班嚴重,加班到凌晨一兩點是常態。
如果直接定義晚上22點到早上6點為非工作時間,將導致較多的誤報,而利用該類特征,能夠自適應地學習該公司真正的非工作時間。
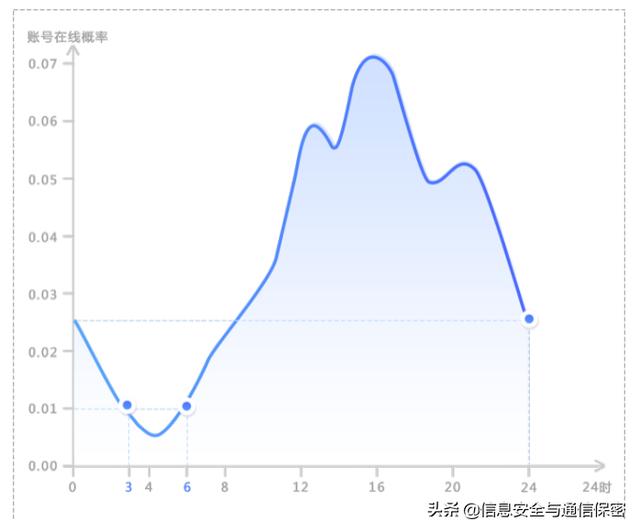
圖1 用戶賬號24小時在線概率密度分布
第2類維度是用戶組與用戶組之間行為基線的對比。一般而言,在企業內部處于同一個部門相似崗位的員工應該有類似的行為基線,不同部門之間如技術部門與銷售部門工作上有較大差異,反映在網絡行為和終端行為上肯定會有較大不同。一個易于理解的事件是,基于不同角色屬性的員工訪問統一資源定位符(Uniform Resource Locator,URL)記錄的聚類。
顯然,同角色屬性或者同部門的員工應該會有更多共同訪問對象和訪問目的。根據日志信息,建立用戶和一段時間內被訪問較多的或者業務相關的URL的關聯矩陣。矩陣元素可以是訪問次數、訪問時長或者平均訪問時長,利用歐式距離計算客戶之間的距離,并進行聚類操作。
對遠離自身角色所在部門群組的用戶可以標記為異常,同時基于用戶與群組中心的距離給出偏離度,針對異常出現的偏離程度,可提取訪問異常特征。偏離度的計算公式如下:
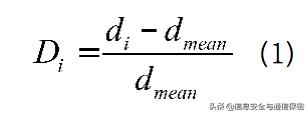
式中,
代表第i個用戶的偏離度;
代表第i個用戶與類簇中心距離;
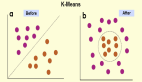
代表同組用戶與類簇中心的平均距離。圖2為技術部門與銷售部門在訪問次數、訪問時長上的聚類圖,圓圈代表技術部門,三角形代表銷售部門,五角星代表這兩個組的聚類中心,兩個類簇中間散落的幾個用戶可以明顯看出異常。如果不分用戶組,那么圓圈中的三角形將被認為是正常用戶;現在區分用戶組進行聚類,則可以明顯看出,這些混雜在圓圈中的三角形離實際的聚類中心很遠,是異常最大的用戶。
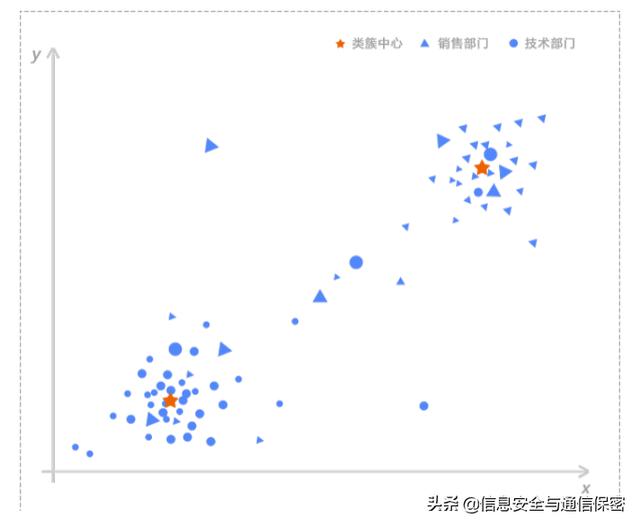
圖2 用戶組聚類結果
第3類維度是基于用戶自身行為基線對比的離散數據特征提取。通過學習大量的歷史行為數據建立正常的用戶基線后,可以對偏離歷史基線的用戶行為提取異常特征。典型事件是用戶使用新的IP地址。一個沒有在歷史記錄中出現的IP地址,意味著用戶的活動基線偏離了原有的軌跡,當然也可能是諸如用戶出差等客觀原因造成的。
但當結合其他的一些信息如新IP地址伴隨著新的MAC地址,這意味著用戶不僅變更了登錄地址,也變更了登錄設備,加重了可疑度。如果還有其他的信息輔助,或者用戶的新IP地址不斷出現,需要將這類現象歸納為疑似異常。
所以,通過一些場景的設想,可以基于用戶自身行為基線提取離散數據的異常特征。第4類維度是基于用戶自身行為基線對比的連續數據特征提取。通過學習用戶的連續數據的行為基線,可以對偏離歷史基線的用戶行為提取異常特征。舉例來說,用戶正常的網絡行為都應該有在一定范圍內波動的出入流量,DPI系統可以幫助記錄每次訪問目標的流量情況。
用戶的出入流量是連續變量,應該滿足某種分布。假設用戶的訪問流量持續大幅遠離了歷史分布,則有理由懷疑用戶使用習慣發生了改變,需要對此加以關注。通過使用RPCA-SST、ARIMA等算法對這類連續的時序數據進行異常檢測,從而提取出異常特征。
圖3為某用戶在6月份的流量時序圖,實線為實際的流量時序,陰影為時序異常檢測算法擬合的正常范圍。超出預測范圍的點被標記為異常,為圖3中的圓點。根據異常點的個數及異常程度,能提取出該用戶的異常特征。
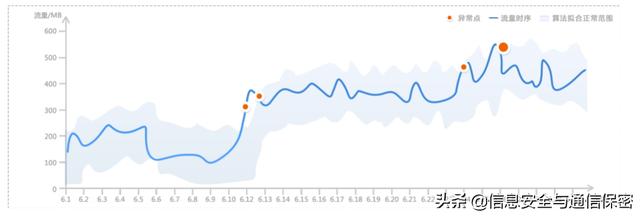
圖3 時序異常檢測
4 基于Ensemble Learning的異常用戶檢測
用戶異常行為建模的3大要素為用戶、實體和行為特征。通過訪問關系的關聯,將3大要素映射到核心的用戶行為上。經過第3章節介紹的4類維度的分解,提取了幾十種有效的用戶行為特征。獲取特征后,即能使用機器學習算法檢測異常用戶。
由于內部攻擊并不經常發生,標簽數據的稀少性決定了多數情況下UEBA使用的是無監督學習算法。從另一個角度說,不依賴先前的攻擊知識反而允許系統發現少見的和過往未曾發現的威脅。異常檢測的主要任務是在正常的用戶數據集中提取出小概率的異常數據點,這些異常點的產生不是由于隨機偏差,而是有如故障、威脅、入侵等完全不同的機制。
這些異常事件的發生頻率同大量的正常事件相比僅僅是少數的一部分。異常檢測算法眾多,它們的期望盡管都是盡可能分離出正常數據與異常數據,但其原理各不相同。針對不同的數據源,很難保證哪一類算法能夠取得最優的結果。采用孤立森林、One Class SVM以及局部異常因子3種算法的集成來全面識別和評價最可能影響系統的各種異常用戶。
利用這3種算法進行異常檢測,可以分別得到所有用戶的異常打分。對3種算法結果進行加權歸一,便可以得到最終的針對所有用戶的異常打分排名。利用這些信息,企業可以按照一定的邏輯順序,采用適當的對策處理現存的威脅,并按輕重緩急實施補救措施。
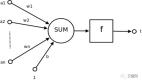
整個UEBA的核心系統框架如圖4所示。每個算法都會對用戶i計算一個獨立的異常分值。孤立森林、One Class SVM、局部異常因子3種算法的幾個分別記為
,其對應的權重分別為
,則最終的異常評分Score為:
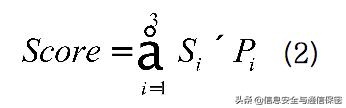
圖4 UEBA核心系統框架
5 實驗結果分析及案例
表1為排名前20的異常用戶分值及部分特征值,用戶名用Hash做了脫敏處理。對排名靠前的異常用戶一一驗證,在排名前10的用戶中,確認了包括賬號第三方共享、主機中毒、惡意掃描、離職員工潛入內網以及敏感信息被違規拉取等問題,賬號風險準確率達到90%。表1 排名前20異常用戶分值及部分特征值
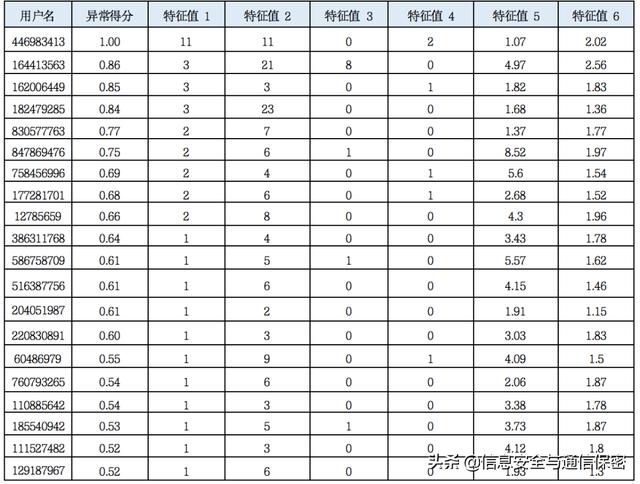
用戶446983413異常排名居首,對其異常特征進行排查,發現存在賬號爆破、異地登錄、端口掃描、從OA系統下載文件以及傳輸流量過大等異常,最終安全運維人員確定為因VPN賬號被爆破導致的敏感信息泄露事件。它在時間軸上的發生順序如圖5所示。
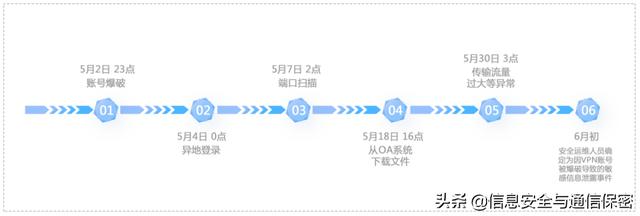
圖5 用戶446983413相關事件時間軸
6 結 語
本文介紹了UEBA即用戶行為實體分析在企業異常用戶檢測中的應用情況,通過用戶、實體、行為3要素的關聯,整合了可以反映用戶行為基線的各類數據,將用戶的行為特征提取分布到4類維度上展開,有效提取了幾十種最能反映用戶異常的基礎特征。
將3種異常檢測算法通過集成學習方法用于異常用戶建模,通過異常打分定位最可能異常的用戶,對排名前10的異常用戶進行排查,驗證證明存在問題的準確率達到90%。企業最開始部署UEBA系統時,基本不會有用戶賬號的標簽。
經過一段時間的使用及排查,會逐步積累用戶賬號的標簽,這樣整個系統的算法漸漸可以從無監督過渡到有監督,從而可進一步提升準確率。通過這樣的正向循環反饋強化,最終會筑起堅固的安全防線。