淘系數據模型治理優秀實踐
具體將圍繞以下4部分展開
- 模型背景&問題
- 2問題分析
- 3治理方案
- 4未來規劃
模型背景&問題
1.整體情況
首先介紹一下淘系的整體數據背景。
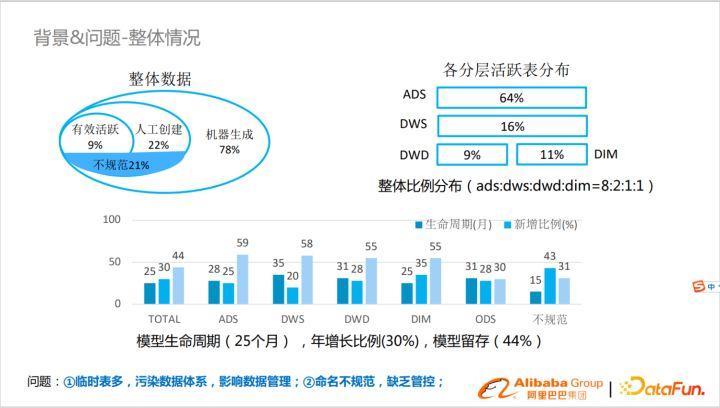
淘系的數據中臺成立至今已有7年左右,一直未作數據治理,整體數據生成構成比為:人工創建(22%)+機器生成78%。其中活躍數據占比:9%,不規范數據占比:21%。
數據活躍以倒三角形狀分布,整體分布比例為ads:dws:dwd:dim=8:2:1:1,分布還算合理。
上圖中下半部分是模型的生命周期,增長和留存情況。淘系的業務還屬于快速變化中,模型變化比較快。模型生命周期為25個月,模型年增長比例30%,模型留存44%。
2.公共層
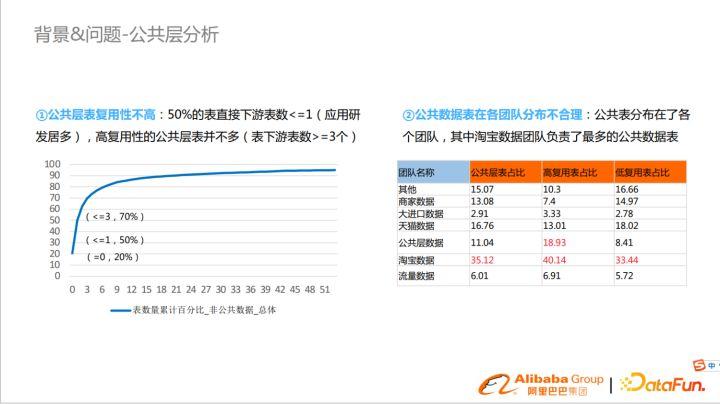
公共層兩大核心問題為:
- 首先,公共層表復用性不高。在2014年的時候公共層還比較規范,但可持續性不強。隨著時間流逝,業務增長和變化,復用性就逐年降低。因為大部分的數據是應用層做的,他們會開發自己的公共層,復用性降低,大部分都是無效表。
- 另外,公共數據表在各個團隊分布不合理。這是由于數據團隊多,為了滿足業務開發效率,每個團隊都有自己的公共表,容易出現公共表復用占比低,重復建設的場景。其中淘寶數據團隊負責最多的公共數據表。
3.應用層分析
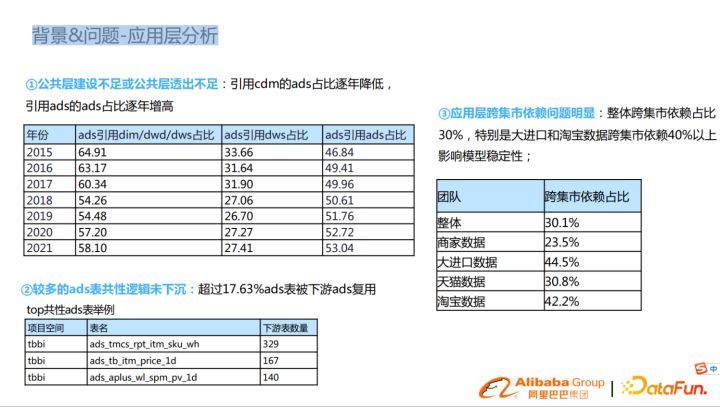
應用層的主要問題包括:
- 第一,公共層建設不足或公共層透出不足。隨著時間增長,公共層的指標不能滿足ads層的業務需要,ads復用指標邏輯沒有下層,引用cdm層的ads表占比逐年降低,引用ads的ads表占比逐年增高。
- 第二,較多的ads表共性邏輯未下沉,統計顯示超過17.63%ads表被下游ads復用。
- 第三,跨集市依賴嚴重,統計顯示,整體跨集市依賴占比為30%,特別是大進口和淘寶數據跨集市依賴達到了40%,影響模型的穩定性,影響了模型的下線、修改。
問題分析
1.問題匯總
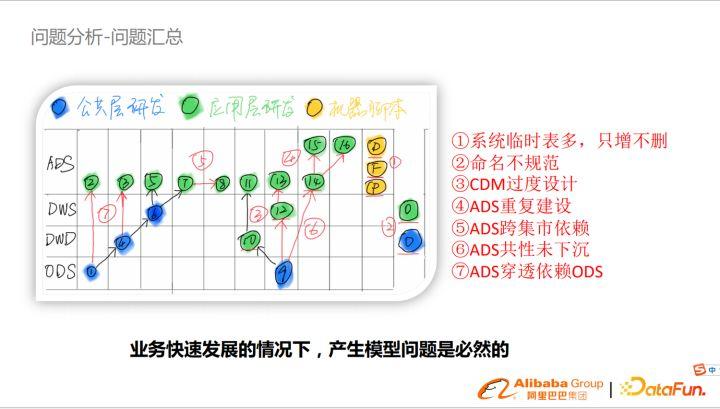
以上這副圖是簡化后的數據模型,我們可以發現存在很多不規范問題影響了模型的穩定性。業務在快速發展的情況下,為了快速響應業務需求,產生模型問題是必然的。日常工作中,數據研發流程大致如下,接到業務需求,直接引用ODS層表開發ADS數據,待數據需要復用的時候就把邏輯沉淀到公共層,同理指標也會有類似情況。主要問題可以歸納為七點:
- 系統臨時表多,只增不刪,對于消費側影響較大,因為表量巨大,有效比例低,很難檢索到;
- 命名不規范;
- 公共層過度設計;
- ADS重復建設;
- ADS跨集市依賴;
- ADS共性未下沉;
- ADS穿透依賴ODS。
2.原因分析

從問題分類上看,主要有三大類問題:規范性問題,公共層復用性問題和應用層復用性問題。
從問題原因上看,主要有四大類原因:架構規范,流程機制,產品工具,以及研發能力。
3.模型治理的問題

模型治理的挑戰:
- 業務價值不明顯,治理帶來的是長期價值,短期對業務影響不大。
- 治理協作復雜,治理需要ODS、CDM、ADS層多人多團隊協作
- 問題治理難根治,容易出現新模型依賴有問題模型
- 模型平均生命周期不長(25個月)
綜上所述,模型治理的ROI比較低,我們的問題就是如何模型治理才最高效?
治理方案
1.整體方案
基于以上的問題原因分析,我們制定了如下治理方案。
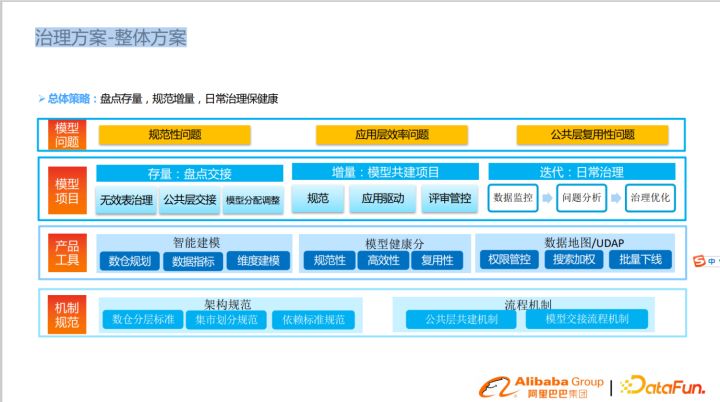
核心策略為以下三點:
1:盤點存量,掌握數據的整體情況
2:規范增量,避免新增模型走老路,重復出現相同問題,考慮到數據的生命周期,歷史數據可以先不管。
3:日常治理保健康,以數據化驅動長期治理
2.機制規范
架構分層標準
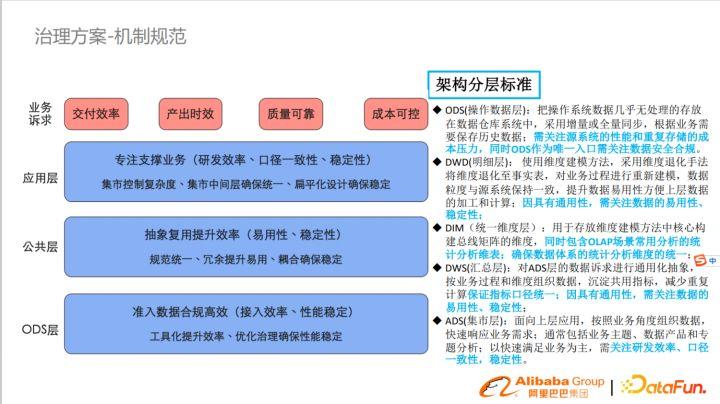
往年我們關注的是數據視角,今年關注的是業務視角,業務視角核心訴求主要有四點,交付效率、產出時效、質量可靠、成本可控。過去OneData定義了每一層的作用,但每個層次的分工定位不清晰,針對這些問題重新做了清晰的定義。
應用層核心是專注支持業務,需要考慮研發效率、交付數據口徑一致性和穩定性。
通過集市規范來控制復雜度,通過輕度聚合的中間層確保口徑統一,通過扁平化設計確保穩定。
公共層的核心是抽象復用來提升效率,需要考慮易用性和穩定性。通過規范和冗余寬表提升復用性,通過解耦來確保穩定性。
ODS層的核心是合規高效,需要考慮接入效率和性能穩定。通過工具化提升效率、優化治理確保性能的穩定。特別是在數據達到一定量之后要考慮采用merge的方式接入數據。
集市劃分規范

數據集市,是用來滿足特定部門或者用戶的需求,按照多維的方式進行存儲。通過對相似數據業務場景內聚進行抽象分類,以降低ADS層重復建設和數據管理復雜度,讓應用研發更聚焦更高效。
集市劃分的原則有以下兩點:
原則一:以業務場景或者服務對象作為劃分原則,對相似數據業務場景內聚抽象進行分類。
原則二:集市劃分需要統一標準,盡量符合MECE原則。
公共層共建機制
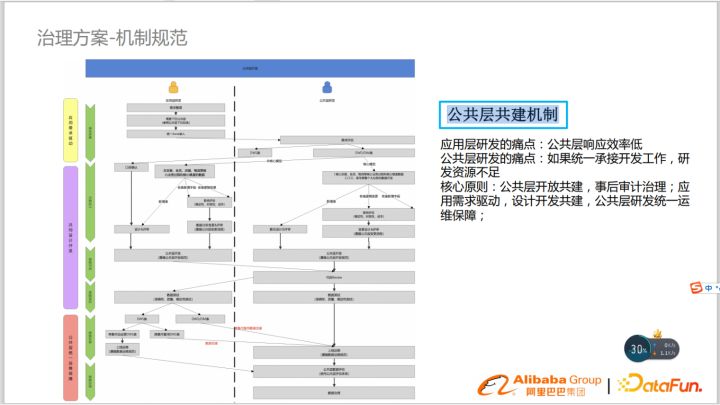
在建設公共層的建設過程中,我們通常會遇到以下兩個痛點:
- 應用研發的痛點:公共層相應效率低。
- 公共層研發的痛點:如果統一承接開發工作,涉及的業務很廣泛,研發資源不足。
為了解決以上兩個痛點,我們通過以下核心原則來解決:
原則一:公共層開放共建,事后審計治理
應用開發整理需求,把需要下沉的公共維度提給公共層研發,公共開發需求評估。
原則二:以應用需求驅動,設計開發共建 以需求為驅動,拆分出核心模型和非核心模型,核心模型公共研發負責,非核心模型由業務開發進行,共同開發以提高效率。
原則三:公共層研發統一運維保障
非核心模型上線并完成相關測試(準確性、確定性、治理)后轉交給公共層研發,由公共層統一運維。
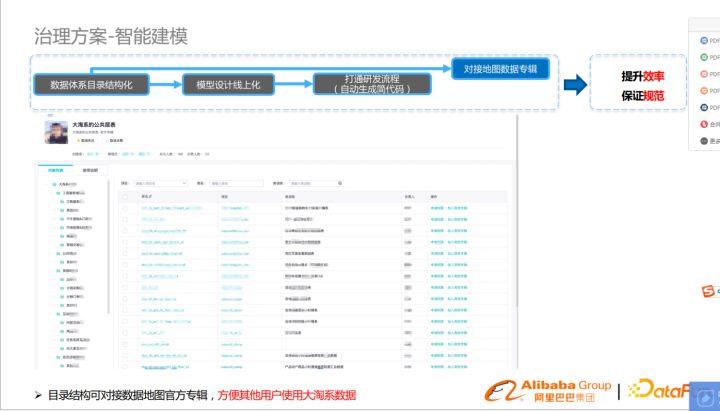
3.智能建模
在數據治理中有數據規范與共建機制依然是不夠的,還需要結合自動化工具來提升效率、保障規范。我們是從以下4個方面入手的(詳情可以體驗DataWorks的產品):
- 數據體系目錄結構化
- 模型設計線上化
- 打通研發流程(自動化生成簡代碼)
- 對接地圖數據專輯
數據目錄體系結構化
形成數據體系目錄有利于了解掌握數據,分門別類的方式降低了大家的使用成本。
首先要對表命名做一些管控,我們做了可視化的表命名檢測器,來確保規范性。另外,淘系不是一個單空間的數據體系,因此要解決跨多個空間的復雜數據體系的統一建模問題。
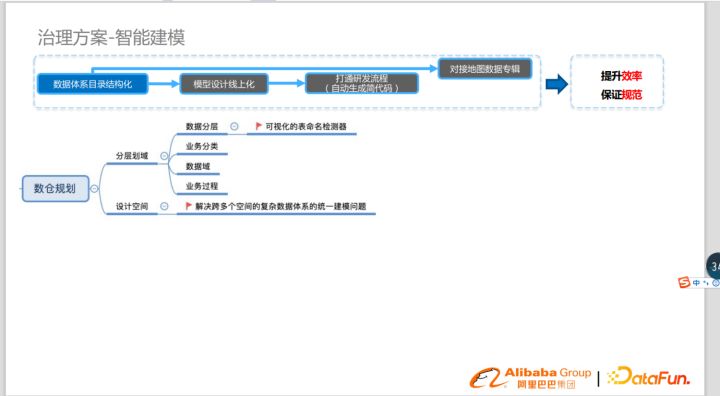
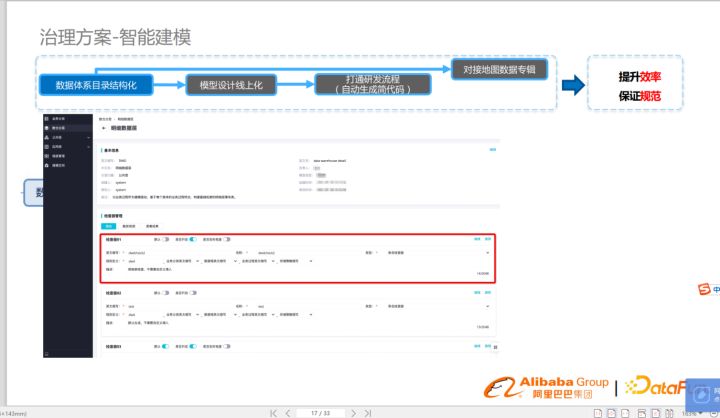
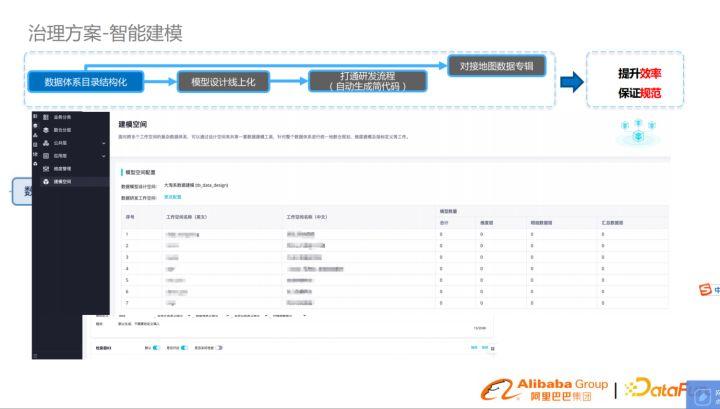
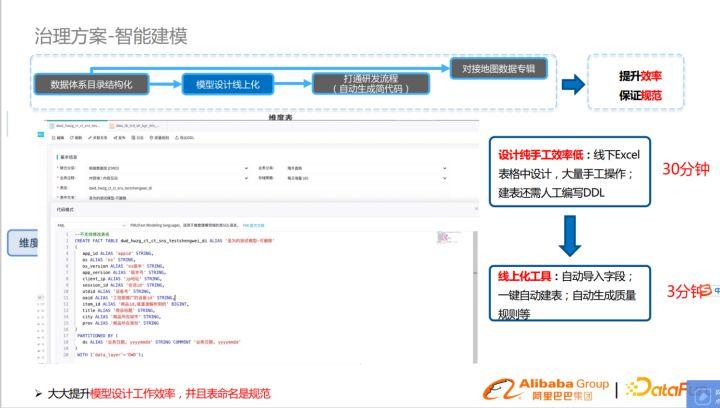
模型設計線上化
改變模型設計方式,由線下設計遷移到線上,通過一些自動化工具,提升效率,保證規范。

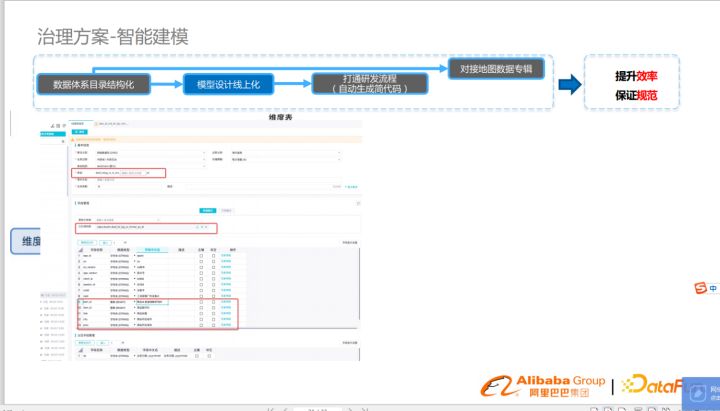
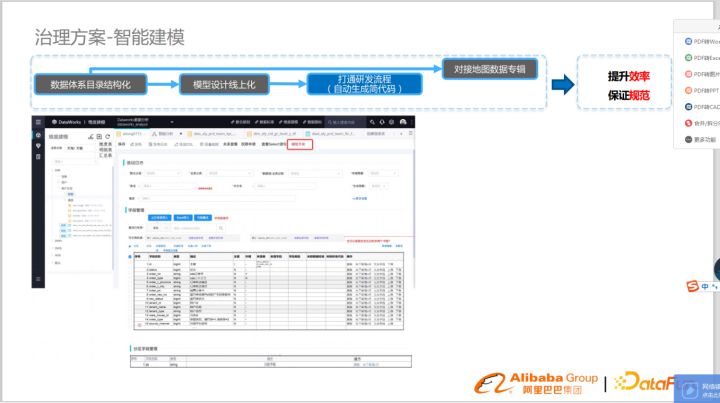
打通研發流程(自動化生成簡代碼)
模型遷移到線上后,打通研發流程自動生成簡代碼,生成代碼框架,建表語句,顯著提高了研發效

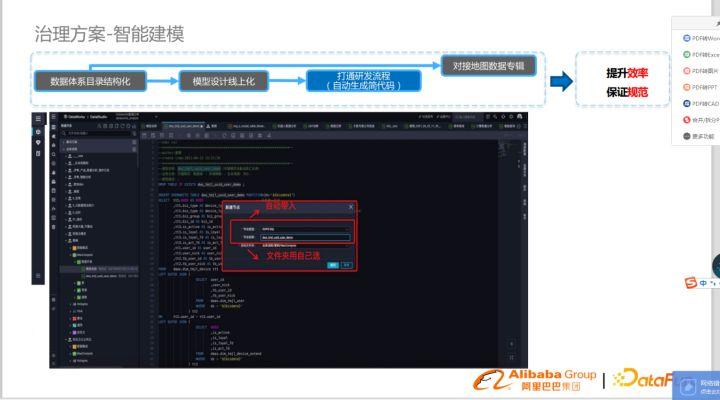
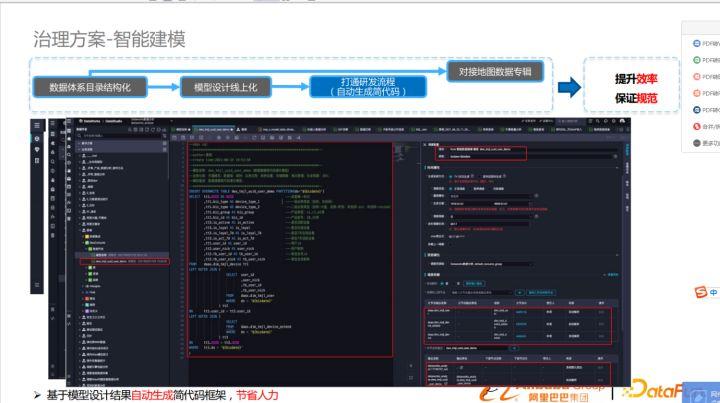
對接地圖數據專輯
形成相應的地圖數據專輯,方便其他用戶使用數據。
4.模型治理
打分模型
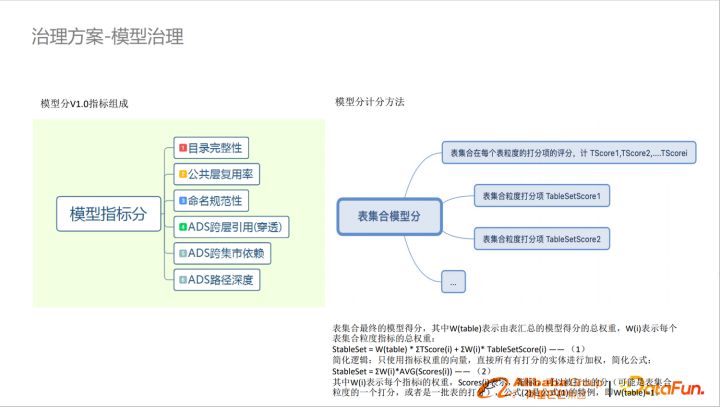
模型治理需要量化,如果沒有量化全靠專家經驗效率是非常低的,我們通過模型的指標形成到表級別的模型分。通過多維度對模型進行打分。
打分機制
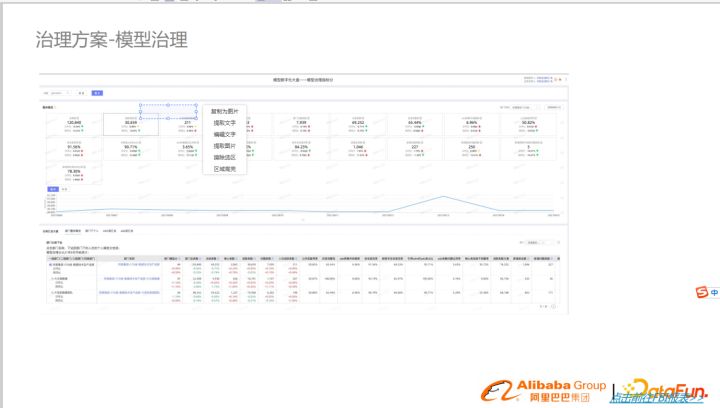
精細化的打分機制,針對團隊、數據域、核心進行打分,形成相應的標簽。
整體流程
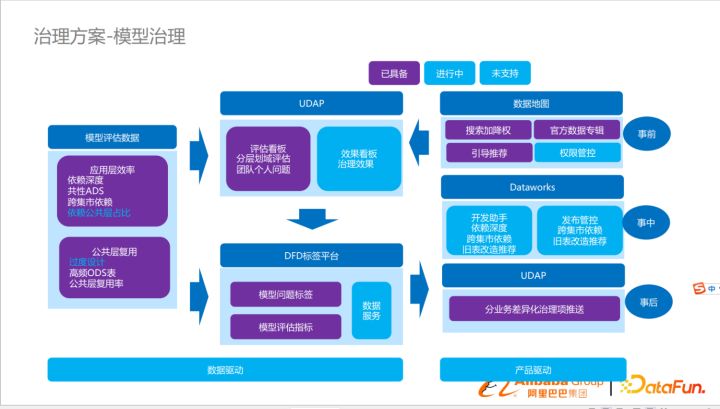
以數據驅動,上圖左邊,以模型評估數據為出發點,通過各個維度對模型進行評估,得到各個域、各個團隊的評分,形成相應的問題標簽。
以產品驅動,上圖右邊,通過專家經驗判斷新上線模型升級搜索權限、下線模型降權限,讓業務迅速感知數據變化,引導業務。
未來規劃
應用層效率
在整個數據體系中,應用層的數據體量是最大的,投入了大量的人力。OneData缺少對應用層的數據建設指導,集市高度耦合,給運維效率帶來了不少問題,如跨集市依賴、依賴深度的問題。過去都是以業務為主導,為了保障研發效率放棄了部分研發規范,以后要完善應用層的研發規范,同時通過工具做好研發效率與規范的平衡。
架構規范管控
基于分層標準落地,對研發過程規范完善,包括對設計、開發、運維、變更、治理等規范進行細化。
目前核心是表命名規范,對依賴規范、代碼規范、運維規范等管控能力尚不足。
產品工具提效
將繼續與Dataworks共建。
- 應用層智能建模能力還不能滿足研發效率要求,因此會繼續功能提效;
- 數據測試功能集成;
- 數據運維功能升級;
- 事中數據治理能力構建(開發助手);
- 事后治理能力提效(批量刪除、主動推送優化等);
- 數據地圖,找數用數提效。
問答環節
1:核心公共層的建設是自頂向下還是自底向上?
采用的是兩者相結合的方式。以需求為驅動,沒有需求就會導致過渡設計,在應用層有復用之后再下沉到公共層,這是自頂向下的。 在公共層設計階段是面向業務過程的,這時是自底向上的。
2:多BU公共層是否需要統一規范?怎么去做?怎么量化價值?
需要做統一的規范,規范利于數據流通,才能體現數據價值 。但是具體怎么規范需要具體去看,如電商、本地生活,業務和目標不一樣,很難做到統一的規范
3:怎么判斷指標需要下沉到公共層?
公共層的開發是需要成本的,是否需要下沉到公共層核心是看是否需要復用,可以從兩個方面入手。
專家經驗判斷:如電商交易環節數據,這類數據是核心數據,是要建設到公共層的。
事后判斷:如玩法之類的業務穩定性不強,那一開始不需要下沉到公共層,避免過度設計,事后再去判斷是否需要下沉。
4:關于表、字段的命名規范,是否需要先定義好詞根再開發?
需要分開看。對于公共層設計到的業務過程是有限的,對于公共部分要先定義好再開發。對于應用層,維度采用的是總建架構所以還需要先定義,對于指標特別是派生指標是多的,不建議先定義在開發。
5:如何解決口徑一致命名不一致,或者口徑不一致或者命名一致的場景。
模型是演變的。對于應用層,80%都是自定義的,第一次出現的時候都是不標準的,這部分如果采用先定義后開發的方式,效率是很低的,只有在下沉到公共層的時候才能夠管控。對于公共層,能做的是保障核心指標90%的規范與定義統一,剩下的那部分也無法保證。
6:跨集市依賴下沉到公共層的必要性?
短期來看,是沒影響的,新增效率高。
長期來會給數據的運維、治理帶來很多影響,在數據下線、變更、治理過程中不得不考慮到下游依賴,會影響全流程的開發效率。