













作者 | 劍蕭
阿里大淘系數據體系經過多年發展,通過豐富的數據和產品支撐了復雜的業務場景,在數據領域取得了非常大的領先優勢。隨著數據規模越來越大,開發人員越來越多,雖有阿里大數據體系規范進行統一管理,但是由于沒有在產品側進行有效的模型設計和管控,在模型規范性、應用層效率、通用層復用性等方面的問題逐漸凸顯。計存成本提升、效率降低、規范減弱、數據使用難度變大、運維負擔增加等。
為了解決這些問題,我們進行了大淘系模型治理專項,在數據服務業務的同時,追求極致的降本提效目標。
參與團隊:
- 數據技術及產品部-大淘系數據團隊
- 數據技術及產品部-數據安全生產平臺&計算平臺事業部-DataWorks
- 計算平臺事業部-產品與解決方案-DataWorks
- PAI產品組
一、數據現狀
為了更好的分析當前大淘系的數據問題,我們進行了詳細的數據分析,首先進行數字化。(整個問題分析有詳細的數據支撐,涉及到數據安全,因此只抽象問題,不展示具體數據細節)。
1 規范性問題
- 表命名不規范,缺乏管控:隨著數據量增長,大淘系的表出現了大量命名未遵循阿里大數據體系的情況,難以管控。
2 通用層復用性問題
- 通用層表復用性不高:通用層表下游引用少于2個的數量非常多;
- 通用層建設不足或通用層透出不足:cdm引用下降,ads引用上升;
- 較多的ads表共性邏輯未下沉:出現很多ads表代碼重復,字段相似度高的情況;
3 應用層效率問題
- 臨時表多,影響數據管理:出現了很多TDDL臨時表、PAI臨時表、機器臨時表、壓測臨時表等;
- 通用層表在各團隊分布不合理:散布多個團隊;
- 較多的ads表共性邏輯未下沉;
- 部分ads表層內依賴深度較深:很多ads表在應用層的深度超過10層;
- 應用層跨集市依賴問題明顯:不同集市間ads互相依賴,不僅影響了數據穩定性,而且數據準確性也難以保障;
- 存在大量的可交接的通用層表:不同團隊的通用層數據與大淘系數據混合在一起;
- 表人員分配不均衡:表owner管理的表數量分布很不均勻,有些owner名下只有幾十張,有些owner名下有幾千張;
二、問題分析
通過對當前數據問題的數字化,我們發現問題涉及到數據的評、建、管、用各個環節。
評:缺乏一套統一數據評估體系。數據問題的發現以往主要通過專家經驗、開發使用環節發現和離散型的數據分析得到,缺乏一套統一的數字化評估體系。數據量有多少?不同層次的數據分布如何?表的命名規范性如何?表的復用性如何?表的加工效率和消費效率如何?如何評價數據建設、使用和維護的好不好?好的數據應該通過哪些指標評估出來?
建:基于數據問題分析我們發現:在統一進行通用層構建和治理的時間段,數據在規范性、復用性、鏈路復雜度、使用效率等方面表現較好,但是在沒有進行統一構建和治理的時間,數據在各方面都表現不好。原因在于:我們有一套阿里大數據體系規范,但是我們并沒有一套覆蓋設計、評審、開發、管控、治理的建模開發產品。
管:數據構建完成后后,并沒有有效的對數據進行成本、復用性、效率、健康情況的管理,通常依賴于集中治理、專項治理或推送治理。成本高、迭代慢。同時還存在表管理分布不均的問題,有些owner承擔了大量的管理和運維工作,數據交接后難以維護,導致數據使用難度高。
用:數據最終是為了使用,通過數據分析和調研問卷來看,普遍存在以下問題:找數難、不會用、不敢用等問題。就導致除了一些非常核心的模型數據外,很多開發者寧愿重新開發也不愿去花費很大精力去找數和理解數據,造成惡性循環。
三、解決方案
針對對問題的分析,我們確定了以下目標:
- 模型數字化:構建一套通用的大淘系模型評估體系,能夠清晰的從多個維度評估當前數據的健康情況,針對問題數據提供改進建議。
- 提效公共模型下沉:定義清晰通用層數據下沉標準,能夠清晰的界定哪些數據應該沉淀到通用層,對于需要沉淀的數據要及時進行沉淀。
- 產品化:通過共建開發一套覆蓋設計、評審、開發、管控、治理的建模開發產品。
- 日常治理:日常監控模型健康情況,并進行治理優化。
- 找數提效:通過共建提高數據檢索效率,提高推薦準確度,將核心數據在數據專輯展示。
為了實現以上目標,我們進行了模型治理整體設計:
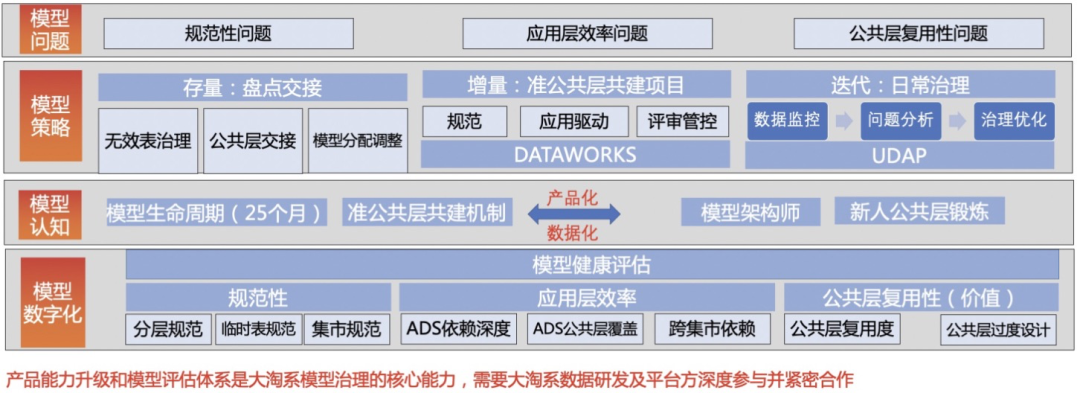
1.DataWorks共建
DataWorks是基于MaxCompute/EMR/Hologres等大數據計算引擎,提供專業高效、安全可靠的一站式大數據開發與治理平臺。通過與DataWorks團隊進行深度共建,利用大淘系多年積累的模型、開發、運維等數據經驗提供輸入和DataWorks強大的產品研發能力,進行智能建模、開發助手、數據地圖等功能的升級,實現數據設計、開發、管控、使用全鏈路產品化,解決長久以來的數據問題。
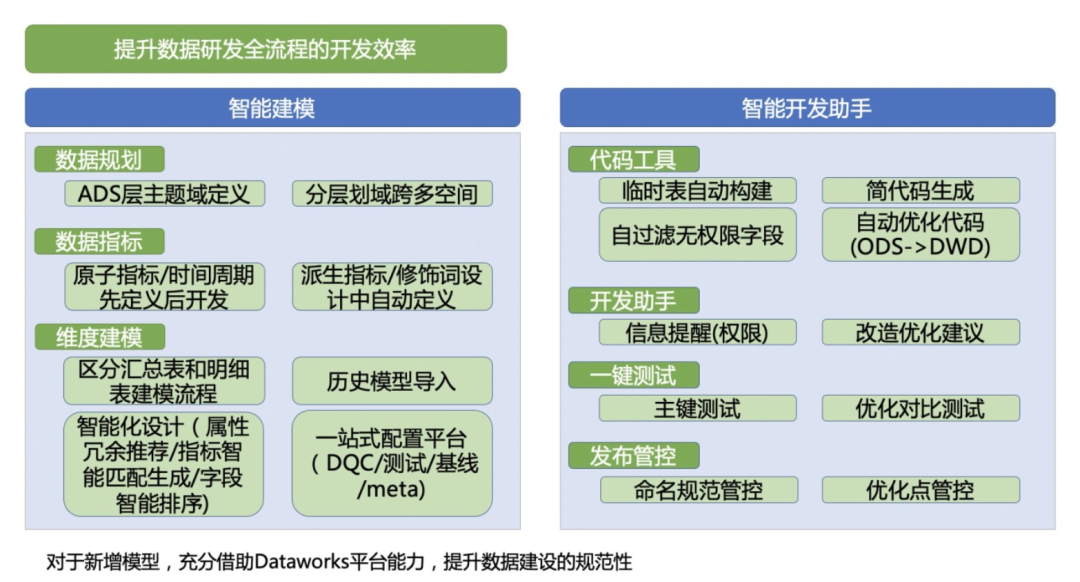
DataWorks智能數據建模
目前,DataWorks智能數據建模產品完成了數倉規劃、數據標準、維度建模、數據指標四大產品模塊的重大產品功能迭代,具備逆向建模、正向可視化建模、excel建模、代碼建模等產品能力,并完成了DataWorks智能數據建模產品在2021年云棲大會的新功能重磅發布。
DataWorks智能數據建模產品全新發布的核心產品功能主要包含以下內容:
數倉規劃:
- 支持公共層及應用層數倉經典分層化域方案所需要素(如數據域、數據集市等)的業務自定義;
- 支持數倉規范的業務自定義,如各層表名規范定義;
- 支持建模空間,支持設置建模空間與數據研發空間的關系建立,滿足大淘系多業務共享數據規范統籌管理數據模型的需求。
維度建模:
- 支持數倉已有物理表的、的逆向建模,解決了大淘系已有物理表的冷啟動難題。
- 支持維度表、明細表、輕度匯總表和應用層表的正向建模,支持可視化建模、excel文件導入模型及代碼建模三種方式。正向可視化建模產品功能汲取了大淘系建模同學沉淀的經典建模理論,依托了MaxCompute的優勢,實現了快速復制MC已有物理表的表結構并支持基于已有字段做維度字段冗余的產品功能,此外,匯總表及應用層表可快速引用已創建的指標生成模型表字段。正向建模excel文件導入模型將大淘系同學數年來沉淀的經典模型excel模版產品化,滿足部分習慣性excel建模同學的建模需求。正向建模產品功能,極大程度上提升了建模效率。
- 設計完成的模型,支持模型評審及物理表發布到MaxCompute、Hologres等五種引擎。
- 發布成功的模型,實現了和DataStuido(數據開發)的打通,支持自動生成ETL框架代碼,數據開發同學只需在此代碼基礎上補充業務邏輯代碼即可,該功能在一定程度上提升了數據開發同學的研發效率;
以上產品功能能很好的解決模型建設規范性和提效的目的。
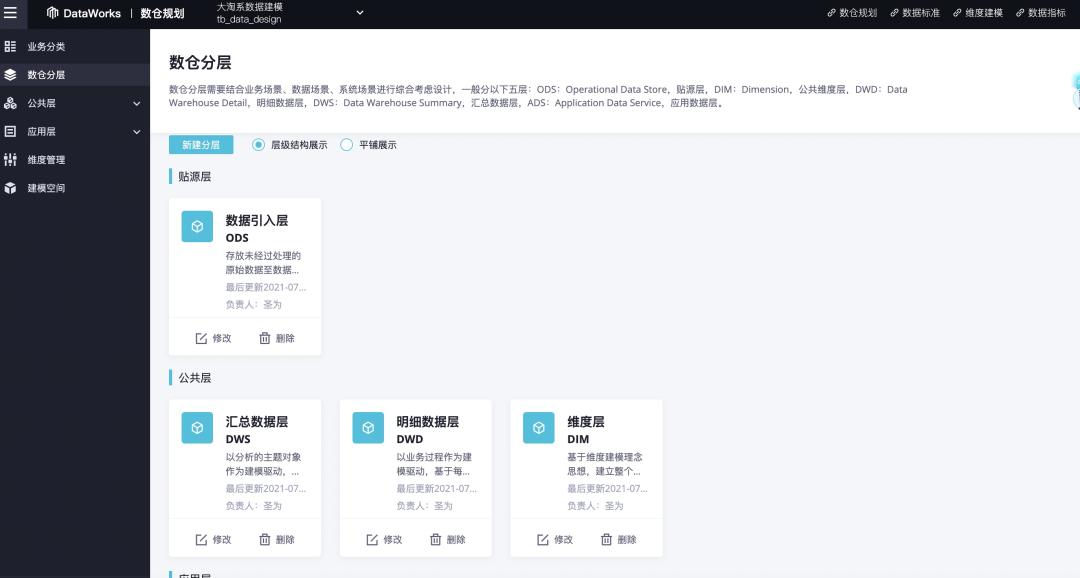
數倉規劃
維度建模
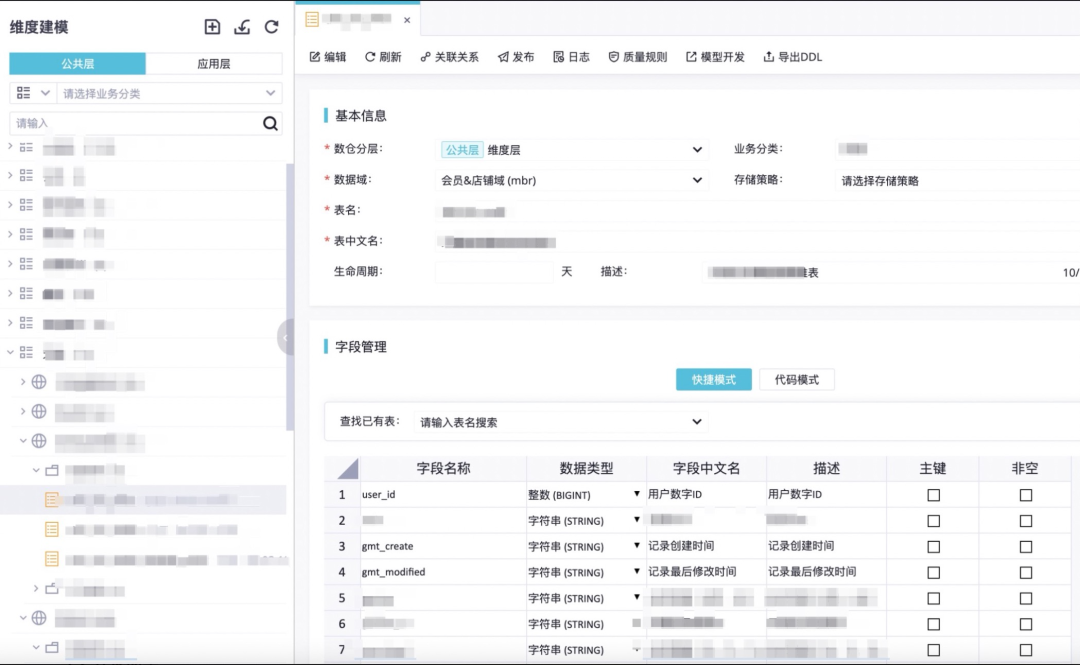
開發助手
開發助手可以在代碼開發中進行權限提醒、發布管控、臨時表自動構建等。
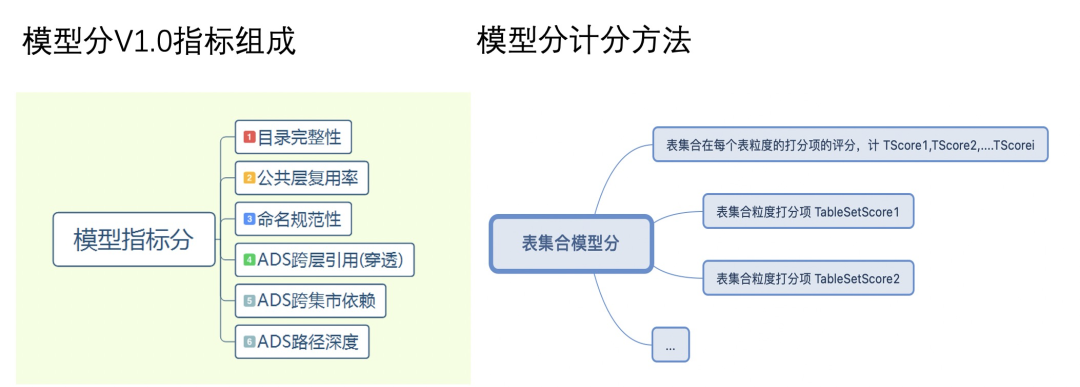
2.模型分
模型分打分邏輯
模型分大盤
我們將模型分評估在內部通過數字大盤的形式展示,并將對應的治理建議通過治理跳轉的方式直接跳轉到相應的產品頁面進行操作。
為了更好的實現復用,模型分支持快速配置接入,只要提供project清單即可通過修改配置快速接入對應BU的數據,產出表級別、owner級別、BU級別模型分及治理動作。
模型大盤的治理項使用了全鏈路血緣和標簽能力,可以比較精準的實現針對性治理。
3.找數提效
找數提效方案:
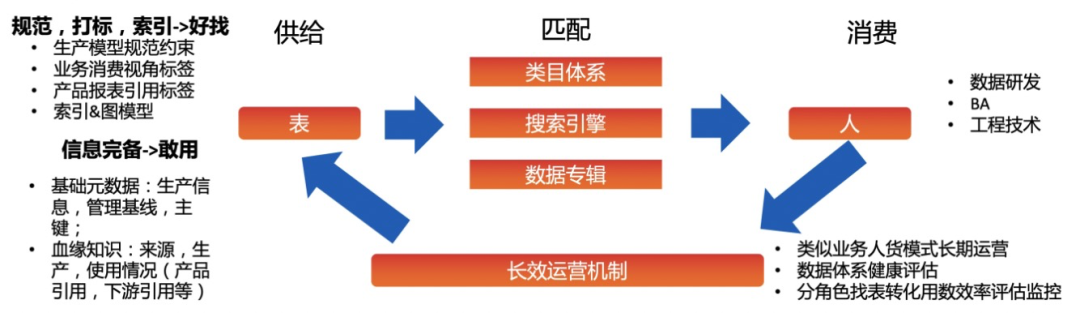
目前,數據地圖上線了團隊常用表、猜你會用、熱門瀏覽、熱門讀取、數據專輯、搜索優化、表說明升級等,表說明功能已完成升級;數據專輯的多人協作維護、展示和修改收藏備注發布、專輯增加使用說明功能。對于找數、用數、數據維護具有重要的意義。
【搜索&推薦】搜索結果過濾增強
- 搜索結果左側過濾條件透出高頻使用條件供用戶選擇,提高篩選效率和搜索CTR。
- 恢復字段搜索功能,搜索過濾支持按照環境過濾。
【內容&組織】表說明功能升級
- 升級表使用說明編輯器為語雀編輯器,支持導入語雀內容,來幫助解決口徑問題
【內容&組織】數據專輯
- 數據專輯提供管理員功能,支持多人協作維護。
- 加入專輯支持展示和修改收藏備注。
- 個人專輯詳情頁中,支持通過表的描述和收藏備注進行搜索。
- 專輯增加使用說明功能
【內容&組織】數據地圖與DataWorks數據打通
- 支持在地圖中標識表是模型表、展示出表的模型信息。
1)搜索推薦

2)數據專輯
數據專輯中將核心表集中展示,可以有效實現核心表的查找和使用。
3)專輯說明
將結構化的知識集中管理,支持語雀知識導入,更好的管理和維護數據。
4)數據百曉生
將數據知識進行算法處理,透過機器人問答實現找表、用表等。為此我們結合內部機器人產品構建了智能答疑機器人。
四、思考總結
經過FY22大淘系模型治理專項,通過大淘系內部開發、與DataWorks團隊&數據安全生產平臺共建,實現了以下重要能力:
模型評估體系:設計并定義了大淘系模型評估體系,從多個維度實現了數據健康度的評估和表級別的治理建議。
智能建模:與DataWorks智能建模團隊合作,上線了數倉規劃、維度建模等重磅產品,實現了維度表、明細表、輕度匯總表和應用層表的正逆向建模。
數據地圖升級:升級了搜索推薦、數據專輯、表說明等重要功能,極大的提高了找數、用數、管理數據的效率。
協作規章制度:定義了準通用層下沉規范、協作規章、交接流程、新人培養機制等清晰的制度,提供清晰的制度保障。
五、后續規劃
目前,大淘系模型治理已經取得了非常好的階段性成果,在產品共建、模型分評估、找數提效方面都有很好的效果產出。但仍然存在一些未解決問題:
- 統一架構和規范難保障:各業務對阿里大數據體系規范的理解程度不一致,集團數據架構和規范的統一難以保障;
- 業務通用層比較薄:歷史背景之下,各業務通用層建設比較薄弱,新架構下業務效率和口徑存在風險;
- ADS層持續增長,復雜度難管控:阿里大數據體系規范缺少對應用層的規范,ADS與通用層的邊界劃分不清晰,ADS的復雜度難以控制;
- 缺乏有效管控:在數據開發與運維層面,阿里巴巴沉淀了大數據體系規范不斷與數據平臺融合,但是部分標準無法強制執行與數據平臺進行集成。數據治理上,當前數據無法有效識別數據表是否無效,導致研發對數據表不敢下、沒精力下;
- 數據建設和使用尚未完全打通:當前數據開發和數據使用尚未完全實現數據打通,定義的模型、開發的數據未在數據地圖中有效的實現透出和管理。
下階段將針對尚未解決的問題進一步深入解決:
- 大淘系模型架構
我們會針對當前存在的架構問題進行升級,從架構原則、設計規范、開發規范、運維規范、治理規范、共建機制等方面進行方法論的升級,以更好的適應當前階段的數據研發現狀,切實的從架構層面為降本、提效提供有效保障。
- 智能建模
繼續與DataWorks團隊共建,進一步提高通用層、應用層開發效率,從產品層面提供保障。
- 數據地圖
官方專輯快速接入:當前官方專輯構建需要專人進行配置和維護,后續可以考慮降低接入成本,下放到各個團隊進行自主接入和維護,提升數據專輯的豐富度和易用性。
進一步打通數據開發和使用環節:將智能建模的數據與數據地圖進一步打通,實現核心模型的快速篩選和透出。
多角度提升表查詢和使用的能力:從表說明、表答疑、數據知識提取等方面實現對找表、用表、表答疑的簡易度提升,結合文本算法、機器人等技術和產品能力,實現數據知識的智能生成。
- 開發助手
開發助手在表推薦和表管控方面可以進一步升級。
- 大淘系通用層評估體系升級
針對當前的模型分加入模型血緣相關的信息,做厚大淘系通用層,為業務提供更好的通用層數據支撐。
表自動化下線:實現模型、表、服務的自動化下線&專家經驗下線,提高數據下線效率,降低人工介入成本。






















