













我們一起聊聊分布式架構中的可觀測性,看你了解幾分?
架構
隨著分布式架構逐漸成為主流,“可觀測性”一詞也日益頻繁地被人提起,它涉及的范圍比較廣泛,主要概括為如下三類:
- 聚合度量(metrics)
- 事件日志(logging)
- 鏈路追蹤(tracing)
這三個方向雖然各有千秋,各有側重,但是又不完全獨立。在Peter Bourgon 的文章《Metrics, Tracing, and Logging》系統地闡述了這三者的定義、特征,以及它們之間的關系與差異,受到了業界的廣泛認可。

在實際的工作中,大家或多或少對上面三種都有一定的了解,只是沒有機會或者沒有需求去深入研究。
聚合度量(Metrics)
度量是一種計量單位,它是指對系統中某一指標的統計聚合,然后通過聚合信息來揭示系統整體的運行狀況。
度量總體上可分為客戶端的指標收集、服務端的存儲查詢以及終端的監控預警三個相對獨立的過程,每個過程一般都是不同的組件來完成,以Prometheus為例:

指標可以通過直接抓取各種exporters,也可以從pushgateway抓取,然后存儲在TSDB(時序數據庫)中,查詢指標可以通過grafana,也可以通過prometheus web,報警則是通過altermanager實現。
可以看到,一個度量工具的內部實現是很復雜的,在使用的時候也會損耗一定的資源。
目前來說,在云原生領域中,Prometheus占據了很大的主導地位,嚴格來說,它已經成云原生監控的標配,下面我主要以Prometheus為例進行介紹。
指標收集
指標收集主要包括兩部分:
- 指標定義
- 指標收集
相比于收集,指標定義尤為重要,良好的指標定義可以更直觀的反應系統狀態。
最常用的黃金指標有:
- 延遲:延遲是信息的發送方和接收方之間的時間延遲,以毫秒(ms)為單位。其原因通常是由于數據包丟失、網絡擁塞和稱為 “數據包延遲差異” 的網絡抖動。延遲直接影響客戶體驗,轉化為成功請求的延遲和失敗請求的延遲。
- 流量:流量是系統上完成的工作量所帶來的壓力。它通過每秒查詢數 (QPS) 或每秒事務數 (TPS) 來衡量。企業通過數量來衡量這一點:關鍵績效指標 (KPI) 是在給定時間訪問網站的人數。這是與商業價值的直接關系。
- 錯誤:錯誤是根據整個系統中發生的錯誤來衡量的。什么被視為服務錯誤率的重要指標!有兩類錯誤,顯式錯誤,例如失敗的 HTTP 請求(例如,500 個錯誤代碼)。而一個隱含的錯誤將是一個成功的響應,但與錯誤的內容或響應時間長。
- 飽和度:飽和度定義了服務的過載程度。它衡量系統利用率,強調資源和服務的整體能力。這通常適用于 CPU 使用率、內存使用率、磁盤容量和每秒操作數等資源。儀表板和監控告警是幫助您密切關注這些資源并幫助您在容量變得飽和之前主動調整容量的理想工具。
- 利用率:雖然不是 “四大金信號” 的一部分,但值得一提;利用率告訴資源或系統有多忙。它以 %(百分比)表示,范圍為 0–100%。
所以在做指標定義的時候,可以結合以上的黃金指標進行分類,但是并不代表每一種類型的應用都需要滿足以上所有指標。以系統監控為例,如下表示是否需要監控該類指標:
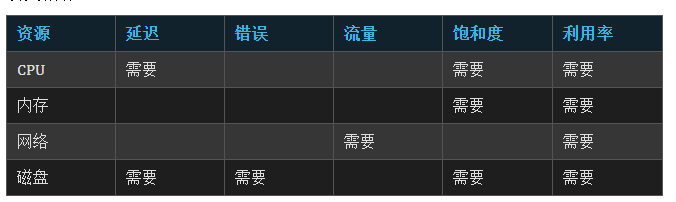
定義好資源指標后,再來定義指標具體的獲取方法。
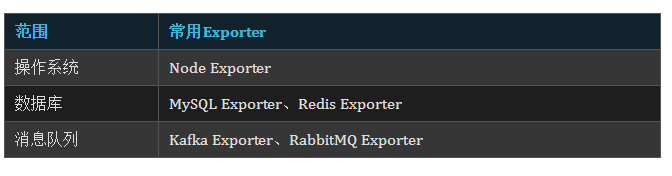
目前,基于Prometheus監控所實現的Exporter非常多,這些Exporter基本能夠拿到我們想要的指標,比如:
指標查詢
指標收集到Prometheus之后,會存儲到它的TSDB(時序數據庫)中,我們可以在Prometheus Web中查詢需要的指標,如下獲取不同時間節點kubelet的HTTP請求總數:

監控預警
指標度量是手段,最終目的是做分析和預警。
我們可以通過這些指標制作監控大屏,隨時觀察系統的狀態,如下可以實時監控Kubernetes中容器以及節點的狀態:

良好的可視化能力對于提升度量系統的產品力十分重要,長期趨勢分析(譬如根據對磁盤增長趨勢的觀察判斷什么時候需要擴容)、對照分析(譬如版本升級后對比新舊版本的性能、資源消耗等方面的差異)、故障分析(不僅從日志、追蹤自底向上可以分析故障,高維度的度量指標也可能自頂向下尋找到問題的端倪)等分析工作,既需要度量指標的持續收集、統計,往往還需要對數據進行可視化,才能讓人更容易地從數據中挖掘規律。
還可以對重要的指標進行告警,以便維護人員能夠及時地介入排查問題,如下是一個應用JVM使用過載的告警。

但是,在做告警的時候需要綜合考慮指標的重要程度,不是所有指標都需要告警,不然就容易造成告警風暴,最后就會真實演繹《狼來了》的故事。
事件日志(Logging)
日志用來記錄系統運行期間所發生的事件,每個系統都應該有日志。
日志是排查問題的重要手段,大部分系統問題最終都會追溯到日志上,所以良好的日志記錄有助于快速定位系統問題。
但是,目前基本都是微服務多節點的形式存在,沒辦法像單機時代那樣簡單使用命令就能獲取到日志內容。而是需要把日志收集到專門的日志系統,然后再進行查詢、分析等。
目前比較受歡迎的開源日志系統是ELK或者EFK,它在日志領域有著不可撼動的地位。

事件日志也涉及以下幾個方面:
- 日志輸出
- 日志收集
- 日志查詢
- 日志告警
日志輸出
一千個開發可能有一千個日志輸出方式,而且輸出的內容千奇百怪,不管重要的或者不重要的都輸出到日志里,這將會導致日志查看困難,干擾大。
所以,良好的日志記錄習慣是非常重要的,在企業中應該有專門的日志規范,這樣可以統一格式、統一標準,不僅有助于收集,也有助于查看。
打印日志應該盡量做到以下幾點:
- 記錄請求的TraceID
- 記錄關鍵事件,包括上下文
- 不要打印敏感信息
- 合理規劃日志級別
日志收集
對于分布式服務,為了能同時看到跨節點的全部日志,就需要把各種日志統一收集,比如使用Logstash或者Filebeat來收集日志,在日志收集的同時還可以對日志進行處理,比如同一個應用的日志可以建一條索引,同一個應用的索引可以按天進行創建等,這樣避免索引過大導致查詢困難等問題。
如果在日志收集的過程中發現日志比較大,可以在收集處理的過程中先把日志寫入緩存或者消息隊列,避免直接寫入Elasticsearch導致其壓力過載。
日志查詢
收集到的日志最終是存儲在Elasticsearch中,它通常搭配Kibana一起使用,方便用戶操作。
Kibana 盡管只負責圖形界面和展示,但它提供的能力遠不止讓你能在界面上執行 Elasticsearch 的查詢那么簡單。Kibana 宣傳的核心能力是“探索數據并可視化”,即把存儲在 Elasticsearch 中的數據被檢索、聚合、統計后,定制形成各種圖形、表格、指標、統計,以此觀察系統的運行狀態,找出日志事件中潛藏的規律和隱患。按 Kibana 官方的宣傳語來說就是“一張圖片勝過千萬行日志”。

日志告警
在做日志輸出的時候,對于一些有破壞性的日志需要特別標記,當遇到這類日志就需要及時的通知維護人員。我們可以使用ElastAlert來進行告警處理。
ElastAlert是三方插件,通過查詢 ElasticSearch 中的記錄進行比對,通過配置報警規則對匹配規則的日志進行警報。 ElastAlert 將Elasticsearch與兩種類型的組件(規則類型和警報)結合使用,定期查詢Elasticsearch,并將數據傳遞到規則類型,該規則類型確定何時找到匹配項。發生匹配時,將為該警報提供一個或多個警報,這些警報將根據匹配采取行動。
鏈路追蹤(Tracing)
有了度量和日志,在多數情況下已經能滿足日常使用,但是它們有一個弊端,就是沒辦法很直觀的查看上下文,也無法有效的追蹤某個請求。
所以,就引入了鏈路追蹤。
從目標來看,鏈路追蹤的目的是為排查故障和分析性能提供數據支持,系統對外提供服務的過程中,持續地接受請求并處理響應,同時持續地生成 Trace,按次序整理好 Trace 中每一個 Span 所記錄的調用關系,便能繪制出一幅系統的服務調用拓撲圖。根據拓撲圖中 Span 記錄的時間信息和響應結果(正常或異常返回)就可以定位到緩慢或者出錯的服務;將 Trace 與歷史記錄進行對比統計,就可以從系統整體層面分析服務性能,定位性能優化的目標。
從字面上看鏈路監控的實現方式比較簡單,然而在實際工作中卻比較復雜。主要在于企業業務系統可能采用不同的程序語言 ,每一種程序語言實現的方式都不一樣,這就導致工作量非常巨大,而且還要考慮以下幾點:
- 低損耗:如果接入鏈路監控不僅沒有解決問題,反而加大了性能開銷,這就得不償失。
- 透明:盡量在不加大開發工作量,最好能做到無侵入接入。
- 易用:傻瓜式的使用方式比較受歡迎。
目前最常用的是Zipkin、Skywalking、Pinpoint等,它們都是基于服務追蹤實現的。
服務追蹤的實現思路是通過某些手段給目標應用注入追蹤探針(Probe),針對 Java 應用一般就是通過 Java Agent 注入的。探針在結構上可視為一個寄生在目標服務身上的小型微服務系統,它一般會有自己專用的服務注冊、心跳檢測等功能,有專門的數據收集協議,把從目標系統中監控得到的服務調用信息,通過另一次獨立的 HTTP 或者 RPC 請求發送給追蹤系統。
下面是使用Skywalking收集之后的查詢頁面。

最后
可觀測性平臺是一個很大很復雜的平臺,大部門公司都是用一些開源手段來堆疊,雖然能解決一些問題,但是它們各自是相互獨立的,沒辦法很友好的進行關聯。這也導致在排查問題的時候需要各個平臺來回切換,而且每個平臺都需要一定的學習成本,這也導致許多公司安裝部署了,但是實際很少去用,沒有發揮其要實現的效果。
鏈接
【1】https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
【2】https://skywalking.apache.org/
【3】https://www.elastic.co/cn/






























