分布式消息隊列:順序消息的基礎邏輯
分布式消息隊列是分布式系統架構中的關鍵組件,主要用于解決應用耦合、異步消息、流量削峰的問題。隨著業務邏輯的拆分和業務系統的微服務改造,不僅要求消息隊列在性能和可靠性上有充分保障,也對其在一些特殊業務場景的功能支持上提出了需求。本文就分布式消息隊列順序消息的基礎邏輯及使用過程中的問題進行了簡單總結。
分布式消息隊列的消息順序問題
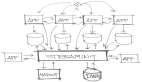
在分布式架構中,消息隊列為實現其高性能、高可用以及彈性伸縮等特點,其存儲數據的邏輯結構大都選擇了多分區的模式,即將一個Topic劃分為多個Partition。多分區的設計大幅提高了架構的并發性和可用性,但消息隊列本身僅能保證每個Partition內部消息的有序性,整個Topic內、多個Partition之間消息的順序性無法得到保障。

圖1 普通消息的收發樣例
在圖1中,a1-a4四條按順序生產的消息在消費的時候已經被徹底打亂,在一般的業務場景中該消費結果是可接受的,但在部分有特殊需求的場景中則不能滿足業務需求。如在給用戶發送銀行卡余額變更的場景中,必須保證同一賬戶的余額變更通知是順序的,對于業務端順序生成的余額變更消息a1,a2,a3,a4,必須保證用戶接收消息的順序也是a1,a2,a3,a4,如圖2所示。

圖2 順序消息的業務需求
在此類有順序需求的場景里,就需要業務系統端和消息隊列服務端“共同努力”,保障業務邏輯的實現。
順序消息的基礎實現邏輯
順序消息是指生產者將需要保證順序的一批消息嚴格按照先進先出(FIFO)的原則發送到消息隊列中,在消費的時候消費者對這一批消息按相同的先后順序進行消費。根據業務場景,一般將順序消息劃分為局部順序和全局順序兩種,但全局順序是局部順序的一種特殊實現,因此本文后續的討論中均圍繞局部順序展開。
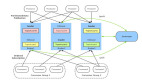
局部順序:對于指定的一個Topic,只需要保證具有相同標識的一批消息嚴格按照先進先出的原則進行發布和消費即可,不同標識的消息之間不做順序要求,上文中提到的在給用戶發送余額變更短信的場景中,只需要保證相同賬戶ID的通知消息具有順序性即可,不同賬戶之間的短信通知順序無需保證。在實現上,大部分消息隊列都是通過在投放時對Message設置ShardingKey,將具有相同ShardingKey的Message投放到相同的Partition的方式保障消息順序存儲,如圖3所示。

圖3 通過ShardingKey實現局部順序
全局順序:對于指定的一個Topic,所有消息按照嚴格的先入先出(FIFO)的順序來發布和消費。全局順序消息實際上是一種特殊的局部順序消息,或者是將該Topic所有的消息打上相同的ShardingKey實現,或者是在消息隊列服務端只為該Topic提供1個Partition,因此其并發度和性能都將嚴重受損。
分區變動帶來的順序錯亂
在正常場景下,通過ShardingKey的方式可以保證消息的有序性,但分布式隊列在使用過程中經常會遇到分區故障或分區擴縮容的情況,此時很難保障消息的嚴格順序。
如在Rocket MQ的主從架構中,主Broker的故障必然會帶來分區數量的變化,此時通過ShardingKey計算出的分區ID也將變化,從而導致消息順序的錯亂。

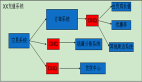
圖4 Partition故障導致消息順序錯亂
如圖4所示,正常場景下a1,a2投遞到Partition2,此時Partition3發生故障,消息隊列服務端的Partition數量發生變化,同一ShardingKey的Hash算法結果會出現變動,因此a3、a4兩條消息被投遞到Partition1,此時兩個隊列之間的消費順序無法得到保障。
在Kafka的架構設計中,盡管Partition副本會在Leader故障后重新選主,故障前后分區的數量未發生變化,但要注意分區選主的過程中整個Partition處于不可用的狀態,此時如果有順序消息生成也將導致順序錯亂。
實踐場景中必須注意的兩個問題
概括來說,順序消息的實現只需要Producer給Message打上ShardingKey即可,但在實際使用過程中仍然需要在使用時結合不同消息隊列產品的特性做針對性的優化,下面針對Kafka和RocketMQ兩款產品順序消息的使用過程中需要注意的問題做簡單介紹。
1. 同步發送保障消息投遞的有序
要保證消息在發送階段的有序性,就要在同一個Producer線程中,使用同步發送的方法對消息進行發送,同時要注意對于發送失敗的情況下要在Producer端做好重試控制,避免因投遞失敗帶來的順序錯誤。
在RocketMQ中,Producer提供的send()方法默認為同步發送,應用可以根據返回的SendResult判斷當前消息是否投遞成功。但在Kafka中,所有的發送本質上都是異步發送,用戶編碼的Producer線程調用的send()方法僅是將消息暫存到客戶端本地的RecordAccumulator中,實際將消息從本地發送到Broker的是后臺的Kafka Sender線程。

圖5 Kafka發送消息的實際邏輯
因此在Kafka中,要實現同步發送的效果要首先獲取send()方法返回的Future對象,而后調用Future對象的get()方法進行阻塞,等待Kafka Broker的響應。
2. 多worker線程消費的問題
在分布式消息隊列的消費模型中,為了保障同一Partition內消息的順序消費,一個Partition在同一個消費組中只能被一個consumer實例消費,因此該消費組的消費能力與Partition的數量密切相關,為解決這一問題很多應用在消費時將consumer僅作為拉取消息的實例,在內部實現多worker線程提高并發度,此時盡管consumer實例拉取到的消息是有序的,但消息在不同的worker線程中處理,也會出現順序錯亂的問題。

圖6 多worker線程消費導致消息順序錯亂
要保障消息的消費順序,必須保障同一ShardingKey的消息在同一線程中處理。客戶端在消費時采用了多worker的邏輯,可以為每一個worker線程引入一個阻塞隊列,consumer分發消息時將相同ShardingKey的消息放入同一個阻塞隊列消費,worker線程不斷輪詢從阻塞隊列中獲取消息處理即可。
總結
在系統的微服務改造過程中,順序消息的使用是不可避免的,用戶要對消息隊列的實現邏輯有清晰的認識,并對其在故障場景下可能造成的影響有提前的預估。本文對順序消息的基礎實現邏輯、服務端故障導致的消息順序錯亂以及應用設計在producer端和consumer端需要注意的問題進行了總結性說明,應當充分認識到順序消息相關業務場景的實現不能僅僅靠消息隊列本身去保障,需要業務端一起共同努力去實現。