分享一個c#寫的開源分布式消息隊列equeue
前言
本文想介紹一下前段時間在寫enode時,順便實現(xiàn)的一個分布式消息隊列equeue。這個消息隊列的思想不是我想出來的,而是通過學習阿里的rocketmq后,自己用c#實現(xiàn)了一個輕量級的簡單版本。一方面可以通過寫這個隊列讓自己更深入的掌握消息隊列的一些常見問題;另一方面也可以用來和enode集成,為enode中的command和domain event的消息傳遞提供支持。目前在.net平臺,比較好用的消息隊列,最常見的是微軟的MSMQ了吧,還有像rabbitmq也有.net的client端。這些消息隊列都很強大和成熟。但當我學習了kafka以及阿里的rocketmq(早期版本叫metaq,自metaq 3.0后改名為rocketmq)后,覺得rocketmq的設計思想深深吸引了我,因為我不僅能理解其思想,還有其完整的源代碼可以學習。但是rocketmq是java寫的,且目前還沒有.net的client端,所以不能直接使用(有興趣的朋友可以為其寫一個.net的client端),所以在學習了rocketmq的設計文檔以及大部分代碼后,決定自己用c#寫一個出來。
項目開源地址:https://github.com/tangxuehua/equeue,項目中包含了隊列的全部源代碼以及如何使用的示例。也可以在enode項目中看到如何使用。
equeue消息隊列中的專業(yè)術語
Topic
一個topic就是一個主題。一個系統(tǒng)中,我們可以對消息劃分為一些topic,這樣我們就能通過topic,將消息發(fā)送到不同的queue。
Queue
一個topic下,我們可以設置多個queue,每個queue就是我們平時所說的消息隊列;因為queue是完全從屬于某個特定的topic的,所以當我們要發(fā)送消息時,總是要指定該消息所屬的topic是什么。然后equeue就能知道該topic下有幾個queue了。但是到底發(fā)送到哪個queue呢?比如一個topic下有4個queue,那對于這個topic下的消息,發(fā)送時,到底該發(fā)送到哪個queue呢?那必定有個消息被路由的過程。目前equeue的做法是在發(fā)送一個消息時,需要用戶指定這個消息對應的topic以及一個用來路由的一個object類型的參數(shù)。equeue會根據(jù)topic得到所有的queue,然后根據(jù)該object參數(shù)通過hash code然后取模queue的個數(shù)***得到要發(fā)送的queue的編號,從而知道該發(fā)送到哪個queue。這個路由消息的過程是在發(fā)送消息的這一方做的,也就是下面要說的producer。之所以不在消息服務器上做是因為這樣可以讓用戶自己決定該如何路由消息,具有更大的靈活性。
Producer
就是消息隊列的生產(chǎn)者。我們知道,消息隊列的本質(zhì)就是實現(xiàn)了publish-subscribe的模式,即生產(chǎn)者-消費者模式。生產(chǎn)者生產(chǎn)消息,消費者消費消息。所以這里的Producer就是用來生產(chǎn)和發(fā)送消息的。
Consumer
就是消息隊列的消費者,一個消息可以有多個消費者。
Consumer Group
消費者分組,這可能對大家來說是一個新概念。之所以要搞出一個消費者分組,是為了實現(xiàn)下面要說的集群消費。一個消費者分組中包含了一些消費者,如果這些消費者是要集群消費,那這些消費者會平均消費該分組中的消息。
Broker
equeue中的broker負責消息的中轉,即接收producer發(fā)送過來的消息,然后持久化消息到磁盤,然后接收consumer發(fā)送過來的拉取消息的請求,然后根據(jù)請求拉取相應的消息給consumer。所以,broker可以理解為消息隊列服務器,提供消息的接收、存儲、拉取服務。可見,broker對于equeue來說是核心,它絕對不能掛,一旦掛了,那producer,consumer就無法實現(xiàn)publish-subscribe了。
集群消費
集群消費是指,一個consumer group下的consumer,平均消費topic下的queue。具體如何平均可以看一下下面的架構圖,這里先用文字簡單描述一下。假如一個topic下有4個queue,然后當前有一個consumer group,該分組下有4個consumer,那每個consumer就被分配到該topic下的一個queue,這樣就達到了平均消費topic下的queue的目的。如果consumer group下只有兩個consumer,那每個consumer就消費2個queue。如果有3個consumer,則***個消費2個queue,后面兩個每個消費一個queue,從而達到盡量平均消費。所以,可以看出,我們應該盡量讓consumer group下的consumer的數(shù)目和topic的queue的數(shù)目一致或成倍數(shù)關系。這樣每個consumer消費的queue的數(shù)量總是一樣的,這樣每個consumer服務器的壓力才會差不多。當前前提是這個topic下的每個queue里的消息的數(shù)量總是差不多多的。這點我們可以對消息根據(jù)某個用戶自己定義的key來進行hash路由來保證。
廣播消費
廣播消費是指一個consumer只要訂閱了某個topic的消息,那它就會收到該topic下的所有queue里的消息,而不管這個consumer的group是什么。所以對于廣播消費來說,consumer group沒什么實際意義。consumer可以在實例化時,我們可以指定是集群消費還是廣播消費。
消費進度(offset)
消費進度是指,當一個consumer group里的consumer在消費某個queue里的消息時,equeue是通過記錄消費位置(offset)來知道當前消費到哪里了。以便該consumer重啟后繼續(xù)從該位置開始消費。比如一個topic有4個queue,一個consumer group有4個consumer,則每個consumer分配到一個queue,然后每個consumer分別消費自己的queue里的消息。equeue會分別記錄每個consumer對其queue的消費進度,從而保證每個consumer重啟后知道下次從哪里開始繼續(xù)消費。實際上,也許下次重啟后不是由該consumer消費該queue了,而是由group里的其他consumer消費了,這樣也沒關系,因為我們已經(jīng)記錄了這個queue的消費位置了。所以可以看出,消費位置和consumer其實無關,消費位置完全是queue的一個屬性,用來記錄當前被消費到哪里了。另外一點很重要的是,一個topic可以被多個consumer group里的consumer訂閱。不同consumer group里的consumer即便是消費同一個topic下的同一個queue,那消費進度也是分開存儲的。也就是說,不同的consumer group內(nèi)的consumer的消費完全隔離,彼此不受影響。還有一點就是,對于集群消費和廣播消費,消費進度持久化的地方是不同的,集群消費的消費進度是放在broker,也就是消息隊列服務器上的,而廣播消費的消費進度是存儲在consumer本地磁盤上的。之所以這樣設計是因為,對于集群消費,由于一個queue的消費者可能會更換,因為consumer group下的consumer數(shù)量可能會增加或減少,然后就會重新計算每個consumer該消費的queue是哪些,這個能理解的把?所以,當出現(xiàn)一個queue的consumer變動的時候,新的consumer如何知道該從哪里開始消費這個queue呢?如果這個queue的消費進度是存儲在前一個consumer服務器上的,那就很難拿到這個消費進度了,因為有可能那個服務器已經(jīng)掛了,或者下架了,都有可能。而因為broker對于所有的consumer總是在服務的,所以,在集群消費的情況下,被訂閱的topic的queue的消費位置是存儲在broker上的,存儲的時候按照不同的consumer group做隔離,以確保不同的consumer group下的consumer的消費進度互補影響。然后,對于廣播消費,由于不會出現(xiàn)一個queue的consumer會變動的情況,所以我們沒必要讓broker來保存消費位置,所以是保存在consumer自己的服務器上。
equeue是什么?
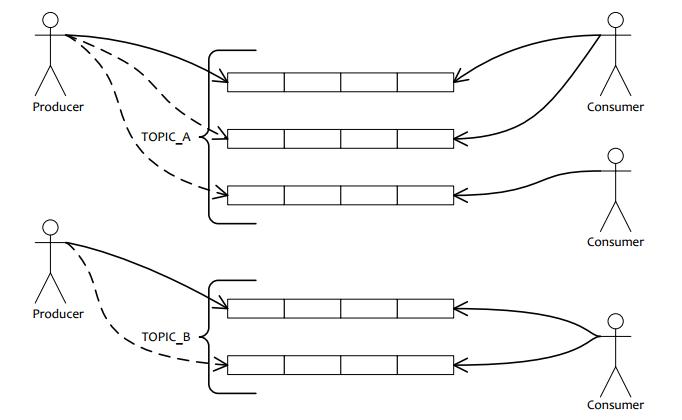
通過上圖,我們能直觀的理解equeue。這個圖是從rocketmq的設計文檔中拿來的,呵呵。由于equeue的設計思想完全和rocketmq一致,所以我就拿過來用了。每個producer可以向某個topic發(fā)消息,發(fā)送的時候根據(jù)某種路由策略(producer可自定義)將消息發(fā)送到某個特定的queue。然后consumer可以消費特定topic下的queue里的消息。上圖中,TOPIC_A有兩個消費者,這兩個消費者是在一個group里,所以應該平均消費TOPIC_A下的queue但由于有三個queue,所以***個consumer分到了2個queue,第二個consumer分到了1個。對于TOPIC_B,由于只有一個消費者,那TOPIC_B下的所有queue都由它消費。所有的topic信息、queue信息、還有消息本身,都存儲在broker服務器上。這點上圖中沒有體現(xiàn)出來。上圖主要關注producer,consumer,topic,queue這四個東西之間的關系,并不關注物理服務器的部署架構。
#p#
關鍵問題的思考
1.producer,broker,consumer三者之間如何通信
由于是用c#實現(xiàn),且因為一般是在局域網(wǎng)內(nèi)部署,為了實現(xiàn)高性能通信,我們可以利用異步socket來通信。.net本身提供了很好的異步socket通信的支持;我們也可以用zeromq來實現(xiàn)高性能的socket通信。本來想直接使用zeromq來實現(xiàn)通信模塊就好了,但后來自己學習了一下.net自帶的socket通信相關知識,發(fā)現(xiàn)也不難,所以就自己實現(xiàn)了一個,呵呵。自己實現(xiàn)的好處是我可以自己定義消息的協(xié)議,目前這部分實現(xiàn)代碼在ecommon基礎類庫中,是一個獨立的可服用的與業(yè)務場景無關的基礎類庫。有興趣的可以去下載下來看看代碼。經(jīng)過了自己的一些性能測試,發(fā)現(xiàn)通信模塊的性能還是不錯的。一臺broker,四臺producer同時向這個broker發(fā)送消息,每秒能發(fā)送的消息4W沒有問題,更多的producer還沒測試。
2.消息如何持久化
消息持久化方面主要考慮的是性能問題,還有就是消息如何快速的讀取。
1. 首先,一臺broker上的消息不需要一直保存在該broker服務器上,因為這些消息總會被消費掉。根據(jù)阿里rocketmq的設計,默認會1天刪除一次已經(jīng)被消費過的消息。所以,我們可以理解,broker上的消息應該不會無限制增長,因為會被定期刪除。所以不必考慮一臺broker上消息放不下的問題。
2. 如何快速的持久化消息?一般來說,我覺得有兩種方式:1)順序寫磁盤文件;2)用現(xiàn)成的key,value的nosql產(chǎn)品來存儲;rocketmq目前用的是自己寫文件的方式,這種方式的難點是寫文件比較復雜,因為所有消息都是順序append到文件末尾,雖然性能非常高,但復雜度也很高;比如所有消息不能全寫在一個文件里,一個文件到達一定大小后需要拆分,一旦拆分就會產(chǎn)生很多問題,呵呵。拆分后如何讀取也是比較復雜的問題。還有由于是順序寫入文件的,那我們還需要把每一個消息在文件中的起始位置和長度需要記錄下來,這樣consumer在消費消息時,才能根據(jù)offset從文件中拿到該消息。總之需要考慮的問題很多。如果是用nosql來持久化消息,那可以省去我們寫文件時遇到的各種問題,我們只需要關心如何把消息的key和該消息在queue中的offset對應起來即可。另外一點疑問是,queue里的信息要持久化嗎?先要想清楚queue里放的是什么東西。當broker接收到一個消息后,首先肯定是要先持久化,完成后需要把消息放入queue里。但由于內(nèi)存很有限,我們不可能把這個消息直接放入queue里,我們其實要放的只需要時該消息在nosql里的key即可,或者如果是用文件來持久化,那放的是該消息在文件中的偏移量offset,即存儲在文件的那個位置(比如是哪個行號)。所以,實際上,queue只是一個消息的索引。那有必要持久化queue嗎?可以持久化,這樣畢竟在broker重啟的時候,恢復queue的時間可以縮短。那需要和持久化消息同步持久化嗎?顯然不需要,我們可以異步定時持久化每個queue,然后恢復queue的時候,可以先從持久化的部分恢復,然后再把剩下的部分通過持久化的消息來補充以達到queue因為異步持久化而慢的部分可以追平。所以,經(jīng)過上面的分析,消息本身都是放在nosql中,queue全部在內(nèi)存中。
那消息如何持久化呢?我覺得***的辦法是讓每個消息有一個全局的順序號,一旦消息被寫入nosql后,該消息的全局順序號就確定了,然后我們在更新對應的queue的信息時,把該消息的全局順序號傳給queue,這樣queue就能把queue自己對該消息的本地順序號和該消息的全局順序號建立映射關系。相關代碼如下:
- public MessageStoreResult StoreMessage(Message message, int queueId)
- {
- var queues = GetQueues(message.Topic);
- var queueCount = queues.Count;
- if (queueId >= queueCount || queueId < 0)
- {
- throw new InvalidQueueIdException(message.Topic, queueCount, queueId);
- }
- var queue = queues[queueId];
- var queueOffset = queue.IncrementCurrentOffset();
- var storeResult = _messageStore.StoreMessage(message, queue.QueueId, queueOffset);
- queue.SetMessageOffset(queueOffset, storeResult.MessageOffset);
- return storeResult;
- }
沒什么比代碼更能說明問題了,呵呵。上的代碼的思路是,接收一個消息對象和一個queueId,queueId表示當前消息要放到第幾個queue里。然后內(nèi)部邏輯是,先獲取該消息的topic的所有queue,由于queue和topic都在內(nèi)存,所以這里沒性能問題。然后檢查一下當前傳遞進來的queueId是否合法。如果合法,那就定位到該queue,然后通過IncrementCurrentOffset方法,將queue的內(nèi)部序號加1并返回,然后持久化消息,持久化的時候把queueId以及queueOffset一起持久化,完成后返回一個消息的全局序列號。由于messageStore內(nèi)部會把消息內(nèi)容、queueId、queueOffset,以及消息的全局順序號一起作為一個整體保存到nosql中,key就是消息的全局序列號,value就是前面說的整體(被序列化為二進制)。然后,在調(diào)用queue的SetMessageOffset方法,把queueOffset和message的全局offset建立映射關系即可。***返回一個結果。messageStore.StoreMessage的內(nèi)存實現(xiàn)大致如下:
- public MessageStoreResult StoreMessage(Message message, int queueId, long queueOffset)
- {
- var offset = GetNextOffset();
- _queueCurrentOffsetDict[offset] = new QueueMessage(message.Topic, message.Body, offset, queueId, queueOffset, DateTime.Now);
- return new MessageStoreResult(offset, queueId, queueOffset);
- }
GetNextOffset就是獲取下一個全局的消息序列號,QueueMessage就是上面所說的“整體”,因為是內(nèi)存實現(xiàn),所以就用了一個ConcurrentDictionary來保存一下queueMessage對象。如果是用nosql來實現(xiàn)messageStore,則這里需要寫入nosql,key就是消息的全局序列號,value就是queueMessage的二進制序列化數(shù)據(jù)。通過上面的分析我們可以知道我們會將消息的全局序列號+queueId+queueOffset一起整體作為一條記錄持久化起來。這樣做有兩個非常好的特性:1)實現(xiàn)了消息持久化和消息在queue中的位置的持久化的原子事務;2)我們總是可以根據(jù)這些持久化的queueMessage還原出所有的queue的信息,因為queueMessage里包含了消息和消息在queue的中的位置信息;
基于這樣的消息存儲,當某個consumer要消費某個位置的消息時,我們可以通過先通過queueId找到queue,然后通過消息在queueOffset(由consumer傳遞過來的)獲取消息的全局offset,然后根據(jù)該全局的offset作為key從nosql拿到消息。實際上現(xiàn)在的equeue是批量拉取消息的,也就是一次socket請求不是拉一個消息,而是拉一批,默認是32個消息。這樣consumer可以用更少的網(wǎng)絡請求拿到更多的消息,可以加快消息消費的速度。
3.producer發(fā)送消息時的消息路由的細節(jié)
producer在發(fā)送消息時,如何知道當前topic下有多少個queue呢?每次發(fā)送消息時都要去broker上查一下嗎?顯然不行,這樣發(fā)送消息的性能就上不去了。那怎么辦呢?就是異步,呵呵。producer可以定時向broker發(fā)送請求,獲取topic下的queue數(shù)量,然后保存起來。這樣每次producer在發(fā)送消息時,就只要從本地緩存里拿即可。因為broker上topic的queue的數(shù)量一般不會變化,所以這樣的緩存很有意義。那還有一個問題,當前producer***次對某個topic發(fā)送消息時,queue哪里來呢?因為定時線程不知道要向broker拿哪個topic下的queue數(shù)量,因為此時producer端還沒有一個topic呢,因為一個消息都還沒發(fā)送過。那就是需要判斷一下,如果當前topic沒有queue的count信息,則直接從broker上獲取queue的count信息。然后再緩存起來,在發(fā)送當前消息。然后第二次發(fā)送時,因為緩存里已經(jīng)有了該消息,所以就不必再從broker拿了,且后續(xù)定時線程也會自動去更新該topic下的queue的count了。好,producer有了topic的queue的count,那用戶在發(fā)送消息時,框架就能把這個topic的queueCount傳遞給用戶,然后用戶就能根據(jù)自己的需要將消息路由到第幾個queue了。
4.consumer負載均衡如何實現(xiàn)
consumer負載均衡的意思是指,在消費者集群消費的情況下,如何讓同一個consumer group里的消費者平均消費同一個topic下的queue。所以這個負載均衡本質(zhì)上是一個將queue平均分配給consumer的過程。那么怎么實現(xiàn)呢?通過上面負載均衡的定義,我們只要,要做負載均衡,必須要確定consumer group和topic;然后拿到consumer group下的所有consumer,以及topic下的所有queue;然后對于當前的consumer,就能計算出來當前consumer應該被分配到哪些queue了。我們可以通過如下的函數(shù)來得到當前的consumer應該被分配到哪幾個queue。
- public class AverageAllocateMessageQueueStrategy : IAllocateMessageQueueStrategy
- {
- public IEnumerable<MessageQueue> Allocate(string currentConsumerId, IList<MessageQueue> totalMessageQueues, IList<string> totalConsumerIds)
- {
- var result = new List<MessageQueue>();
- if (!totalConsumerIds.Contains(currentConsumerId))
- {
- return result;
- }
- var index = totalConsumerIds.IndexOf(currentConsumerId);
- var totalMessageQueueCount = totalMessageQueues.Count;
- var totalConsumerCount = totalConsumerIds.Count;
- var mod = totalMessageQueues.Count() % totalConsumerCount;
- var size = mod > 0 && index < mod ? totalMessageQueueCount / totalConsumerCount + 1 : totalMessageQueueCount / totalConsumerCount;
- var averageSize = totalMessageQueueCount <= totalConsumerCount ? 1 : size;
- var startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
- var range = Math.Min(averageSize, totalMessageQueueCount - startIndex);
- for (var i = 0; i < range; i++)
- {
- result.Add(totalMessageQueues[(startIndex + i) % totalMessageQueueCount]);
- }
- return result;
- }
- }
函數(shù)里的實現(xiàn)就不多分析了。這個函數(shù)的目的就是根據(jù)給定的輸入,返回當前consumer該分配到的queue。分配的原則就是平均分配。好了,有了這個函數(shù),我們就能很方便的實現(xiàn)負載均衡了。我們可以對每一個正在運行的consumer內(nèi)部開一個定時job,該job每隔一段時間進行一次負載均衡,也就是執(zhí)行一次上面的函數(shù),得到當前consumer該綁定的***queue。因為每個consumer都有一個groupName屬性,用于表示當前consumer屬于哪個group。所以,我們就可以在負載均衡時到broker獲取當前group下的所有consumer;另一方面,因為每個consumer都知道它自己訂閱了哪些topic,所以有了topic信息,就能獲取topic下的所有queue的信息了,有了這兩樣信息,每個consumer就能自己做負載均衡了。先看一下下面的代碼:
- _scheduleService.ScheduleTask(Rebalance, Setting.RebalanceInterval, Setting.RebalanceInterval);
- _scheduleService.ScheduleTask(UpdateAllTopicQueues, Setting.UpdateTopicQueueCountInterval, Setting.UpdateTopicQueueCountInterval);
- _scheduleService.ScheduleTask(SendHeartbeat, Setting.HeartbeatBrokerInterval, Setting.HeartbeatBrokerInterval);
每個consumer內(nèi)部都會啟動三個定時的task,***個task表示要定時做一次負載均衡;第二個task表示要定時更新當前consumer訂閱的所有topic的queueCount信息,并把***的queueCount信息都保存在本地;第三個task表示當前consumer會向broker定時發(fā)送心跳,這樣broker就能通過心跳知道某個consumer是否還活著,broker上維護了所有的consumer信息。一旦有新增或者發(fā)現(xiàn)沒有及時發(fā)送心跳過來的consumer,就會認為有新增或者死掉的consumer。因為broker上維護了所有的consumer信息,所以他就能提供查詢服務,比如根據(jù)某個consumer group查詢該group下的consumer。
通過這三個定時任務,就能完成消費者的負載均衡了。先看一下Rebalance方法:
- private void Rebalance()
- {
- foreach (var subscriptionTopic in _subscriptionTopics)
- {
- try
- {
- RebalanceClustering(subscriptionTopic);
- }
- catch (Exception ex)
- {
- _logger.Error(string.Format("[{0}]: rebalanceClustering for topic [{1}] has exception", Id, subscriptionTopic), ex);
- }
- }
- }
代碼很簡單,就是對每個訂閱的topic做負載均衡處理。再看一下RebalanceClustering方法:
上面的代碼不多分析了,就是先根據(jù)consumer group和topic獲取所有的consumer,然后對consumer做排序處理。之所以要做排序處理是為了確保負載均衡時對已有的分配情況盡量不發(fā)生改變。接下來就是從本地獲取topic下的所有queue,同樣根據(jù)queueId做一下排序。然后就是調(diào)用上面的分配算法計算出當前consumer應該分配到哪些queue。***調(diào)用UpdatePullRequestDict方法,用來對新增或刪除的queue做處理。對于新增的queue,要創(chuàng)建一個獨立的worker線程,開始從broker拉取消息;對于刪除的queue,要停止其對應的work,停止拉取消息。
通過上面的介紹和分析,我們大家知道了equeue是如何實現(xiàn)消費者的負載均衡的。我們可以看出,因為每個topic下的queue的更新是異步的定時的,且負載均衡本身也是定時的,且broker上維護的consumer的信息也不是事實的,因為每個consumer發(fā)送心跳到broker不是實時發(fā)送的,而是比如每隔5s發(fā)送一次。所有這些因為都是異步的設計,所以可能會導致在負載均衡的過程中,同一個queue可能會被兩個消費者同時消費。這個就是所謂的,我們只能做到一個消息至少被消費一次,但equeue層面做不到一個消息只會被消費一次。實際上像rocketmq這種也是這樣的思路,放棄一個消息只會被消費一次的實現(xiàn)(因為代價太大,且過于復雜,實際上對于分布式的環(huán)境,不太可能做到一個消息只會被消費一次),而是采用確保一個消息至少會被消費一次(即at least once).所以使用equeue,應用方要自己做好對每個消息的冪等處理。
#p#
5.如何實現(xiàn)實時消息推送
消息的實時推送,一般有兩種做法:推模式(push)和拉模式(pull)。push的方式是指broker主動對所有訂閱了該topic的消費者推送消息;pull的方式是指消費者主動到broker上拉取消息;對于推模式,***的好處就是實時,因為一有新的消息,就會立即推送給消費者。但是有一個缺點就是如果消費者來不及消費,它也會給消費者推消息,這樣就會導致消費者端的消息會堵塞。而通過拉的方式,有兩種實現(xiàn):1)輪訓的方式拉,比如每隔5s輪訓一下是否有新消息,這種方式的缺點是消息不實時,但是消費進度完全由消費者自己把控了;2)開長連接的方式來拉,就是不輪訓,消費者和broker之間一直保持的連接通道,然后broker一有新消息,就會利用這個通道把消息發(fā)送給消費者。
equeue中目前采用的是通過長連接拉取消息的方式。長連接通過socket長連接實現(xiàn)。但是雖然叫長連接,也不是一直不斷開,而是也會設計一個超時的限制,比如一個長連接***不超過15s,超過15s,則broker發(fā)送回復給consumer,告訴consumer當前沒有新消息;然后consumer接受到這個回復后,就知道要繼續(xù)發(fā)起下一個長連接來拉取。然后假如在這15s中之內(nèi),broker上有新消息了,則broker就能立即主動利用這個長連接通知相應的消費者,把消息傳給消費者。所以,可以看出,broker上在處理消費者的拉取消息的請求時,如果當前沒有新消息,則會hold住這個socket連接,最多hold 15s,超過15s,則發(fā)送返回信息,告訴消費者當前無消息,然后消費者再次發(fā)送pull message request過來。通過這樣的基于長連接的拉取模式,我們可以實現(xiàn)兩個好處:1)消息實時推送;2)由消費者控制消息消費進度;
另外,equeue里還實現(xiàn)了消費者自身的自動限流功能。就是假如當前broker上消息很多,即生產(chǎn)者生產(chǎn)消息的速度大于消費者消費消息的速度,那broker上就會有消息被堆積。那此時消費者在拉取消息時,總是會有新消息拉取到,但是消費者又來不及處理這么多消息。所以equeue框架內(nèi)置了一個限流(流控,流量控制)的設計,就是可以允許用于配制一個消費者端堆積的消息的上限,比如3000,超過這個數(shù)目(可配置),則equeue會讓消費者以慢一點的頻率拉取消息。比如延遲個多少毫秒(延遲時間可配置)再拉取。這樣就簡單的實現(xiàn)了流控的目的。
6.如何處理消息消費失敗的情況
作為一個消息隊列,消費者總是可能會在消費消息時拋出異常,在equeue中這種情況就是消息消費失敗的情況。通過上面的消費進度的介紹,大家知道了每個queue對某個特定的consumer group,都有一個唯一的消費進度。實際上,消息被拉取到consumer本地后,可能會被以兩種方式消費,一種是并行消費,一種是線性消費。
并行消費的意思是,假如當前一次性拉取過來32個消息,那equeue會通過啟動task(即開多線程)的方式并行消費每個消息;
線性消費的意思是,消息是在一個獨立的單線程中順序消費,消費順序和拉取過來的順序相同。
對于線性消費,假如前一個消息消費的時候失敗了,也就是拋異常了,那該怎么辦呢?可能想到的辦法是重試個3次,但是要是重試后還是失敗呢?總不能因為這個消息而導致后面的消息無法把消費吧?呵呵!對于這種情況,先說一下rocketmq里的處理方式吧:它的做法是,當遇到消費失敗的情況,沒有立馬重試,而是直接把這個消息發(fā)送到broker上的某個重試隊列,發(fā)送成功后,就可以往下消費下一個消息了。因為一旦發(fā)送到重試隊列,那意味著這個消息就***總是會被消費了,因為該消息不會丟了。但是要是發(fā)送到broker的重試隊列也不成功呢?這個?!其實這種情況不大應該出現(xiàn),如果出現(xiàn),那基本就是broker掛了,呵呵。
rocketmq中,對于這種情況,那會把這個失敗的消息放入本地內(nèi)存隊列,慢慢消費它。然后繼續(xù)往后消費后面的消息。現(xiàn)在你一定很關心queue的offset是如何更新的?這里涉及到一個滑動門的概念。當一批消息從broker拉取到消費者本地后,并不是馬上消費的,而是先放入一個本地的SortedDictionary,key就是消息在queue里的位置,value就是消息本身。因為是一個排序的dictionary,所以key最小的消息意味著是最前面的消息,***的消息就是***面的消息。然后不管是并行消費還是線性消費,只要某個消息被消費了,那就從這個SortedDictionary里移除掉。每次被移除一個消息時,總是會返回當前這個SortedDictionary里的最小的key,然后我們就能判斷這個key是否和上次比是否前移了,如果是,則更新queue的這個***的offset。因為每次移除一個消息的時候,總是返回當前SortedDictionary里的最小的key,所以,假如當前offset是3,然后offset為4的這個消息一直消費失敗,所以不會被移除,但是offset為5,6,7,8的這些消息雖然都消費成功了,但是只要offset為4的這個消息沒有被移除,那最小的key就不會往前移動。這個就是所謂的滑動門的概念了。就好比是在鐵軌上一輛在跑的動車,offset的往前移動就好比是動車在不斷往前移動。因為我們希望offset總是會不斷往前移動,所以不希望前面的某個消費失敗的消息讓這個滑動門停止移動(即我們總是希望這個最小的key能不斷變大),所以我們會想方設法讓消費失敗的消息能不阻礙滑動門的往前移動。所以才把消費失敗的消息放入重試隊列。
另外一點需要注意一下:并不是每次成功消費完一個消息,就會立馬告訴broker更新offset,因為這樣那性能肯定很低,broker也會忙死,更好的辦法是先只是在本地內(nèi)存更新queue的offset,然后定時比如5s一次,將***的offset更新到broker。所以,因為這個異步的存在,同樣也會導致某個消息被重復消費的可能性,因為broker上的offset肯定比實際的消費進度要慢,有5s的時間差。所以,再次強調(diào),應用方必須要處理好對消息的冪等處理!比如enode框架中,對每個command消息,框架內(nèi)部都做了command的冪等處理。所以使用enode框架的應用,自身無需對command做冪等處理方面的考慮。
上面提到了并行消費和線性消費,其實對于offset的更新來說是一樣的,因為并行消費無非是多線程同時從SortedDictionary中移除消費成功的消息,而單線程只是單個線程去移除SortedDictionary中的消息。所以我們要通過鎖的機制,保證對SortedDictionary的操作是線程安全的。目前用了ReaderWriterLockSlim來實現(xiàn)對方法調(diào)用的線層安全。有興趣的朋友可以去看一下代碼。
***,也是重點,呵呵。equeue目前還沒有實現(xiàn)將失敗的消息發(fā)回到broker的重試隊列。這個功能以后會考慮加進去。
7.如何解決broker的單點問題
這個問題比較復雜,目前equeue不支持broker的master-salve或master-master,而是單點的。我覺得一個成熟的消息隊列,為了確保在一個broker掛了的時候,要盡量能確保有其他broker可以接替它,這樣才能讓消息隊列服務器的可靠性。但是這個問題實在太復雜。rocketmq目前實現(xiàn)的也只是master-slave的方式。也就是只要主的master掛了,那producer就無法向broker發(fā)送消息了,因為slave的broker是只讀的,不能直接接受新消息,slave的broker只能允許被consumer拉取消息。
這個問題,要討論清楚,需要很多分布式方面的知識。由于篇幅的原因,這里就不做討論了,實際上我自己也搞不清楚到底該如何設計。希望大牛們多多指點,如何實現(xiàn)broker的高可用哈!