阿里云ADB基于Hudi構建Lakehouse的實踐

導讀:大家好,我是來自阿里云數據庫的李少鋒,現在主要專注于 ADB Hudi & Spark 的研發以及產品化,今天非常高興能夠借這個機會和大家分享下阿里云 ADB 基于 Apache Hudi 構建 Lakehouse 的應用與實踐。
接下來我將分為 3 個部分給大家介紹今天的議題,首先我會介紹經過將近一年打磨推出的ADB 湖倉版的架構以及關鍵優勢,接著會介紹在支持客戶構建 Lakehouse 時,我們是如何克服基于 Hudi 構建千億數據入湖的挑戰;最后將介紹基于 ADB 構建 Lakehouse 的實踐。
1、ADB 湖倉版機構與關鍵優勢
首先先來介紹下 ADB 湖倉版架構及其關鍵優勢。

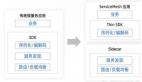
一體版本,我們稱為 ADB 湖倉版。湖倉版在數據全鏈路的「采存算管用」5 大方面都進行了全面升級。
在「采集」方面,我們推出了數據管道 APS 功能,可以一鍵低成本接入數據庫、日志、大數據中的數據。
在「存儲」方面,我們除了新增 Hudi 格式的外表能力,也對內部存儲進行了升級改造。通過只存一份數據,同時滿足離線、在線 2 類場景。
在「計算」方面,我們對自研的 XIHE BSP SQL 引擎進行容錯性、運維能力等方面的提升,同時引入開源 Spark 引擎滿足更復雜的離線處理場景和機器學習場景。
在「管理」方面,我們推出了統一的元數據管理服務,統一湖倉元數據及權限,讓湖倉數據的流通更順暢。
在「應用」方面,除了通過SQL方式的BI分析應用外,還支持基于 Spark 的 AI 應用。
我們希望通過資源一體化和體驗一體化,2 個一體化能力,幫助客戶實現降本增效。資源一體化是指一份數據、極致彈性和融合引擎。體驗一體化是指統一的計費單位、數據管道、數據管理和數據訪問。

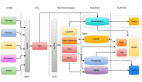
在 ADB 湖倉版中,首先將一份全量數據存在低成本高吞吐存儲介質上,低成本離線處理場景直接讀寫低成本存儲介質,降低數據存儲和數據 IO 成本,保證高吞吐。其次將實時數據存在單獨的存儲 IO 節點(EIU)上,保證「行級」的數據實時性,同時對全量數據構建索引,并通過 Cache 能力對數據進行加速,滿足百 ms 級高性能在線分析場景。因此,數據湖中的數據可以在數倉中加速訪問;而數倉中的數據,也可以利用離線資源進行計算。

極致彈性通過彈得好、彈得起、彈得快三個特點,貼合業務負載,保證查詢性能,降低資源成本。
彈得好是指提供了適合在線分析業務的分時彈性和適合離線處理、機器學習的按需彈性,完美貼合業務負載,滿足業務需求。
彈得起是指基于神龍 + ECS + ECI構建了三級資源庫存供給能力,保障彈性資源交付率超過 95%。
彈得快是指資源池化后通過緩存加速等技術,彈性啟動效率可以達到 10s 內。

支撐離線、在線兩類場景的背后,除了剛才提到的一份數據。還有自研的XIHE融合計算引擎,同時提供 MPP 模式和 BSP 模式,并提供自動切換能力。
自動切換能力是指當查詢使用 MPP 模式無法在一定耗時內完成時,系統會自動切換為 BSP模式進行執行。未來,我們還將在一個查詢中,根據算子特點部分算子采用 MPP 模式,部分算子采用 BSP 模式,兼顧高性能和高吞吐,提供更智能的查詢體驗。
同時融合引擎為提供資源利用率提供了可能,通常離線處理發生在晚上,在線分析發生在白天,一份資源可以同時支持 2 類場景,通過錯峰提升資源利用率。

最后再介紹一下統一數據管道APS。數據快速接入,是數據分析的第一步,也是最容易流失客戶的一步。但我們發現數據接入面臨體驗差、成本高、門檻高等痛點。
所以,我們決定跟其它接入工具做好深度優化的同時,面向中小客戶,構建一個統一數據管道 APS,底層基于 Flink 實時引擎,提供易用性好、低延時、低成本的數據接入體驗。

對于湖倉中的表元數據,ADB 做了統一元數據服務,湖倉中的元數據/權限可互通,可通過不同引擎自由訪問湖倉數據;而對于湖倉數據,為了屏蔽底層數據存儲格式的差異,便于第三方引擎集成,ADB 提供了面向內存列存格式 Arrow,滿足對吞吐的要求,對于內部存儲,已經通過 Arrow 格式完成 Spark 對接,提供高吞吐能力。

自研是打造技術深度的基礎,但同時我們積極擁抱開源,滿足已經生長在開源生態上的客戶可以更平滑地使用湖倉版。外表類型,在 Parquet/ORC/JSON/CSV 等 Append 類型數據格式的基礎上,為支持在對象存儲上低成本 Lakehouse,支持了Apache Hudi,提供近實時的更新、刪除能力,滿足客戶對低成本的訴求。
2、基于 Hudi 構建千億數據入湖的挑戰
以上就是 ADB 湖倉版的架構與關鍵優勢,接著介紹基于 Hudi 構建千億數據入湖的挑戰以及如何我們是如何克服這些挑戰的。

首先我們看下典型的業務場景,業務源端數據通過數據采集進入阿里云 SLS,然后通過 APS數據管道服務進入ADB 湖倉版,基于 ADB 湖倉版之上構建日志查詢、日志導出、日志分析等功能。
該業務場景有如下典型的特點:
1.高吞吐,單鏈路最高 4GB/s 吞吐,日增數據量 350TB,總存儲量超 20PB。
2.數據傾斜/熱點嚴重:源端數據傾斜非常嚴重,從百萬到幾十條數據不等。
3.掃描量大:日志查詢的掃描量 50GB ~ 500GB 不等,查詢并發在 100+。
如果使用數倉的話會面臨成本高的問題,另外是數倉缺少熱點打散能力,只能不斷加資源,瓶頸明顯;最后是數倉系統資源是固化的,沒有動態彈性能力,或者彈性能力較弱,承載不同客戶查詢需求時,容易互相干擾,尤其是大客戶的數據掃描。

先來看下日志數據入湖的技術架構,數據從 SLS 讀取,然后通過 Flink 寫入 Hudi,整個架構非常簡單,其中對于 SLS 和 Flink 的狀態存儲說明如下:
1.SLS 多 Shard 存儲,由 Flink 的多個 Source 算子并行消費。
2.消費后通過 Sink 算子調用 Hudi Worker/Writer 寫出到 Hudi(實際鏈路還存在 Repartition,熱點打散等邏輯)。
3.Flink Checkpoint 后端存儲以及 Hudi 數據存儲在OSS。

接著來看下 Flink 寫入 Hudi 的主流程,首先明確 Flink 寫 Hudi 時會存在兩種角色,Coordinator 負責處理元數據,如對 Hudi Instant 的相關操作,Worker/Writer 負責處理數據,如寫入數據為 parquet 格式,寫入步驟如下:
1.Coordinator 開啟一個 Hudi Instant。
2.Filnk Sink 發送數據給 Hudi Worker 寫出。
3.觸發 Flink Checkpoint 時,則通過 Sink 算子通知 Worker Flush 數據,同時持久化operator-state。
4.當 Flink 完成 Checkpoint 持久化時,通知 Coordinator 提交該 Instant,Coordinator 完成最終提交,寫 commit 文件,數據對外可見。
5.提交后會立即開啟一個新的 Instant,繼續上述循環。

如果把 Flink 寫 Hudi 保證端到端一致性分成兩部分,一部分是 Flink 框架內部的,另外一個部分是與 Hudi 交互的部分。
1.其中步驟 1 到 3 之間是 Flink Checkpoint 邏輯,如果異常在這些步驟上發生,則認為 Checkpoint失敗,觸發 Job 重啟,從上一次 Checkpoint 恢復,相當于兩階段提交的 Precommit 階段失敗,事務回滾,如果有 Hudi 的 inflight commit,等待 Hudi Rollback 即可,無數據不一致問題。
2.當 3 到 4 之間發生異常,則出現 Flink 和 Hudi 狀態不一致。此時 Flink 認為 Checkpoint 已結束,而 Hudi 實際尚未提交。如果對此情況不做處理,則發生了數據丟失,因為Flink Checkpoint 完畢后,SLS 位點已經前移,而這部分數據在 Hudi 上并未完成提交,因此容錯的重點是如何處理此階段引起的數據一致性問題。
3.我們拿一個例子舉例分析在步驟 3 和 4 之前發生異常時,如果保證數據一致性。
4.否則認為上一次 Instant 執行失敗,等待 Rollback 即可,臟數據對用戶不可見。

我們舉例分析下在步驟 3 和 4 之間發生異常時,是如何保證數據一致性的,可以看到對于1615 的 commit 在 Flink 完成 Checkpoint 時會將其 instant 信息持久化至 Flink 后端存儲。
從 checkpoint 恢復時有如下步驟:
1.Checkpoint 時 Sink 算子 Flush 數據及持久化 Instant 的 state。
2.Worker 請求處于 pending 的 Instant,與從 state 恢復的 Instant 做對比并匯報給 Coordinator。
3.Coordinator 從 Instant Timeline 中獲取最新的 Instant 信息,并接收所有 Worker 的匯報。
4.如果 Worker 匯報 Instant 相同,并且不在 Timeline 中已完成的 Instant 中,則表示該 Instant 尚未提交,觸發 Recommit。
經過上述步驟可以保證在 Flink 完成 Checkpoint 時,但對于 Hudi Commit 失敗時的場景會進行 recommit,從而保證數據的一致性。

?接著介紹我們在處理 4GB/s 的高吞吐時面臨的挑戰,一個非常大的挑戰就是熱點數據處理,我們統計了 5 分鐘內各 Task 處理數據的大小,發現各 Task 處理數據從 200W 條到幾十條不等,熱點問題明顯。
而在寫入鏈路中會根據分區字段做 shuffle,同一個分區由一個 Task 寫入,對于上述存在的熱點問題會導致部分TM上的分區寫入非常慢,導致數據延遲/作業掛掉。
面對寫入熱點問題,我們開發了熱點打散功能,通過配置指定規則打散熱點數據,同時可以根據數據流量自動更新熱點打散規則,確保系統的健壯性,可以看到經過熱點打散后個 TM 處理的數據量/CPU占用/內存占用基本相同并且比較平穩,作業穩定性也得到了提升。?

?另外一個挑戰是 OOM,其實和熱點打散也有很大關系,我們發現作業運行時會出現OOM,導致作業掛掉,數據延遲上漲,因此我們對堆外/堆內內存的使用做了比較細致的梳理,使用內存的部分主要集中在:
1.寫 Parquet 文件占用堆外內存?。
2.OSS Flush 占用堆外內存。
3.單 TM 的 Slot 數、寫并發都影響內存占用,如每個寫并發處理 30-50 Handle,TM 16 并發,8M row group size 最多占用 6400 M 內存。
4.堆內內存負載過高導致頻繁Full GC。
我們針對上述分內存使用做了優化,如:
1.row group size 配置為 4M,減少堆外內存占用,同時將堆外內存調大。
2.close 時及時釋放 compressor 占用的內存,這部分對 parquet 源碼做了改造。
3.透出堆外內存指標,增加堆外內存監控,這部分也是對 parquet 源碼做了改造。
4.源端 source 算子與 Shard 分配更均衡,以此保證各 TM 消費的 shard 數基本均等。

最后一個比較大的挑戰就是 OSS 限流,云對象存儲(如OSS)對 List 操作不友好,list objects 對 OSS 服務器壓力較大,如在我們場景下,1500 寫并發,會產生 1W QPS list object,OSS 側目前限流 1K QPS,限流明顯,限流會導致作業處理變慢,延遲變高,為解決該問題,我們也梳理了寫入鏈路對 OSS 的請求,在元數據鏈路對 OSS 的請求如下:
1.Timeline 構建需要 list .hoodie 目錄 。
2.Flink CkpMetaData 基于 OSS 傳遞給 Worker。
3.Hadoop-OSS SDK create/exists/mkdir 函數依賴 getStatus 接口,getStatus 接口現有實現導致大量 list 請求,其中 getStatus 接口對于不存在的文件,會額外進行一次 list objects 請求確認 Path 是不是目錄,對 Marker File、partitionMetadata、數據文件都會產生大量的 list objects 請求。
在數據鏈路對 OSS 請求如下:先臨時寫到本地磁盤,再上傳至 OSS,導致本地磁盤寫滿。
針對上述對 OSS 的請求,我們做了如下優化,在元數據側:
1.Timeline Based CkpMetaData,將TM請求打到 JM,避免大量 TM 掃描 OSS 文件。
2.Hadoop-OSS SDK,透出直接創建文件的接口,不進行目錄檢查。
3.PartitionMetaData 緩存處理,在內存中對每個分區的元數據文件做了緩存處理,盡量減少與 OSS 的交互。
4.Create Marker File 異步處理,異步化處理不阻塞對 Handle 的創建,減少創建 Handle 的成本。
5.開啟 Timeline Based Marker File,這個是社區已經有的能力,直接開啟即可。
這里額外補充下可能有小伙伴比較好奇為什么開啟 hudi metadata table 來解決云對象存儲的限流問題,我們內部做過測試,發現開啟 metadata table 時,寫入會越來越慢,無法滿足高吞吐的場景。
以上就是我們在處理日志數據入湖時面臨的典型挑戰以及我們如何克服這些挑戰,接著講講我們在處理數據入湖時為滿足業務要求做的關鍵特性開發。

首先是支持并發寫,業務側要求鏈路有補數據能力,補數據場景涉及多 Flink Client 寫不同分區,實時寫鏈路,補數據鏈路,Table Service 鏈路并發操作表數據/元數據,這要求:
1.表數據不錯亂。
2.補數據/TableService 鏈路不影響實時寫鏈路。
因此我們對 Hudi 內核側做了部分修改來支持并發寫場景:
1.CkpMetadata 唯一標識,保證不同作業使用不同 ckp meta。
2.ViewStorage 唯一標識,保證不同作業 Timeline Server 隔離。
3.Lazy Table Service,保證并行作業不互相 rollback commit,避免數據錯亂。
4.Instant 生成重試策略,保證 Timeline Instant 的唯一性,避免數據錯亂。
5.獨立 Table Service 處理,使用單獨的作業運行 Table Service,與實時寫鏈路完全隔離。

另外一個關鍵特性是出于成本考慮,業務側要求 Hudi 中數據不能無限地保存,需要按照用戶設定的策略保留指定時間的數據,這要求:
1.Hudi 提供分區級別按照數據量,分區數和過期時間等不同維度進行生命周期管理的能力。
2.Hudi 支持并發設置生命周期管理策略,因為面向多租戶會涉及并發更新管理策略。
針對業務對生命周期管理的需求,我們開發 Hudi 的生命周期管理功能,具體實現如下:
1.對于生命周期管理使用,首先通過 call command 添加生命周期管理策略,并進行持久化,為支持并發更新,我們參考 Hudi MOR 表中 Base 文件和 Log 文件的設計,并發更新會寫入不同的 Log 文件。
2.對于生命周期管理的執行,在每一次 commit 結束后進行統計信息增量采集并更新至統計信息文件,然后按照分區策略進行過期分區的處理,對于過期分區會生成一個 replace commit,等待后續被 clean 即可,同時會合并前面的策略 Base 文件和 Log 文件,生成新的 Base 文件以及更新統計信息。
我們也提供了按照分區數、數據量、過期時間三種不同策略來管理 Hudi 表中的分區的生命周期,很好的滿足業務側的需求。

最后一個比較大的關鍵特性是獨立 TableService,業務側要求保證實時寫鏈路穩定,同時希望提高入湖數據的查詢性能,這要求:
1.在不影響主鏈路同步性能情況下,清理 Commits/文件版本,保證表狀態大小可控。
2.為提高查詢性能,提供異步 Clustering 能力,合并小文件,減少掃描量,提高查詢性能。
基于上述訴求我們開發了基于 ADB 湖倉版的獨立 Table Service 服務,在入湖鏈路寫入完成后會進行一次調度,然后將請求寫入調度組件,供調度組件后續拉起彈性的 Flink/Spark TableService 作業,可以做到對實時寫入鏈路無影響。
對于表狀態管理以及數據布局優化均是采用的獨立 TableService 作業執行,保證表的狀態大小可控,同時通過異步 Clustering 操作,端到端查詢性能提升 40% 以上。

在對日志入湖鏈路進行了深入打磨后,我們可以保證最高 4GB/s 的數據寫入,延遲在 5min內,滿足業務需求。
同時也建設了指標監控大盤與異常鏈路告警功能,便于快速定位問題以及出現問題后快速響應。
以上介紹便是我們是如何基于Hudi構建千億數據入湖以及如何克服入湖挑戰的。
3、基于 ADB 構建 Lakehouse 的實踐
最后介紹下基于 ADB 構建 Lakehouse 的實踐。

前面也提到 ADB 湖倉版擁抱開源技術,ADB 集成了流式處理引擎 Flink,并在此基礎上推出了 APS 數據管道服務,APS 具備如下優勢:
1.低成本,低延遲:作業級別彈性資源,按量付費;按流量自由設定作業資源;充分享受 Flink 流式處理性能紅利。
2.多數據源快速集成:得益于 Flink 成熟的 Connectors 機制,可以方便對接如 SLS、Kafka 等數據源,同時可以保證數據入湖的精確一致性。
3.低使用門檻:支持白屏化操作快速構建 Lakehouse,基于統一元數據服務,Lakehouse 數據可通過 Spark/ADB 引擎無縫訪問。

而為了滿足客戶對于批處理以及機器學習能力的訴求,ADB 集成了 Spark 引擎,并在此技術上推出了 Servlersss Spark,其具備如下優勢:
1.一份數據存儲,在離線共享:無縫對接 ADB 已有元數據和數據;支持大吞吐讀寫 ADB 數據;Spark 批量寫入的數據,在線分析查詢可直接訪問。
2.數據庫體系&體驗:使用 ADB 統一的賬號、權限和鑒權體系;支持通過 ADB Workflow、DMS 以及 DataWorks 調度編排 SparkSQL 作業。
3.完全兼容 Spark 生態:基于最新的 Apache Spark 3.X 版本,充分享受開源社區紅利;支持 SparkSQL、DataFrame API 主流編程接口以及 Thrift Server;支持 Spark UDF,支持 Hive UDF/UDTF/UDAF。
4.按量計費,秒級彈性:開箱即用,按量計費無任何持有成本;基于神龍、ECS/ECI 的管控底座以及資源池化,緩存加速等技術,支持 Spark Pod 秒級拉起。

對于實時性有訴求的場景,可以基于 ADB APS 服務可以非常方便的構建準實時 Lakehouse,白屏化操作快速配置入湖通道,多種數據源支持,滿足不同數據源接入訴求,更多數據源也在持續集成中。

而對于實時性沒有訴求的場景,可以基于 Spark + Hudi + ADB 工作編排構建離線 Lakehouse,如想對 RDS 數據構建離線Lakehouse進行分析,可使用ADB工作編排,利用 Spark 將 RDS 數據離線導入 Lakehouse,并做數據的清洗和加工,有需要最后可通過一條簡單的 Spark SQL將數據從 Hudi 導入 ADB 做查詢分析加速。
另外 ADB Spark 與 Hudi 和 ADB 表都做了深度集成,便于客戶使用,如對于 Hudi 表的使用,免去了很多 Hudi 額外的配置,開箱即用;對于 ADB 表,可通過 Spark 創建、刪除 ADB 表元數據,也支持讀寫 ADB 表數據。

另外最后介紹下 Spark 與 ADB 集成提供的 Zero-ETL 解決方案,這也與 2022 AWS reinvent 推出的數據集成服務 Zero-ETL 類似,我們通過一個場景了解 Zero-ETL 的應用及其優勢。
客戶如果對于 ADB 表有分析挖掘的需求,受限于 JDBC 方式吞吐的限制,需要先將 ADB內表數據以 parquet 格式導出到 OSS,利用 OSS 的帶寬,再通過 Spark 進行分析挖掘,最后輸出挖掘結果,可以看到這種方案中存在ETL操作,從而引入數據一致性差、時效性低的問題。
在 ADB 湖倉版中 Spark 與 ADB 做了深度集成,通過 Lakehouse API直接訪問 ADB 內表數據,吞吐高,所以面對同樣的場景,可以使用下面的鏈路,即直接通過 Spark 分析 ADB 數據,無需 ETL,數據一致性好,時效性也很高;另外對于 Lakehouse API 層的訪問也支持列投影、謂詞下推、分區裁剪等能力,更多下推能力也在持續建設中。

前面介紹了很多關于 ADB 湖倉版的功能以及優勢,包括 Serverless Spark、APS 服務、融合引擎、工作流編排等等。而對于 ADB 湖倉版的定位總結成一句話就是從湖到倉,打造云原生一站式數據分析平臺。
讓客戶通過 ADB 湖倉版平臺就可以輕松玩轉數據分析。