Halodoc的數據平臺轉型之Lakehouse架構
在 Halodoc,我們始終致力于為最終用戶簡化醫療保健服務,隨著公司的發展,我們不斷構建和提供新功能。我們兩年前建立的可能無法支持我們今天管理的數據量,以解決我們決定改進數據平臺架構的問題。在這篇文章中,我們將討論我們的新架構、涉及的組件和不同的策略,以擁有一個可擴展的數據平臺。

一、新架構
讓我們首先看一下經過改進的新數據平臺 2.0 的高級架構。
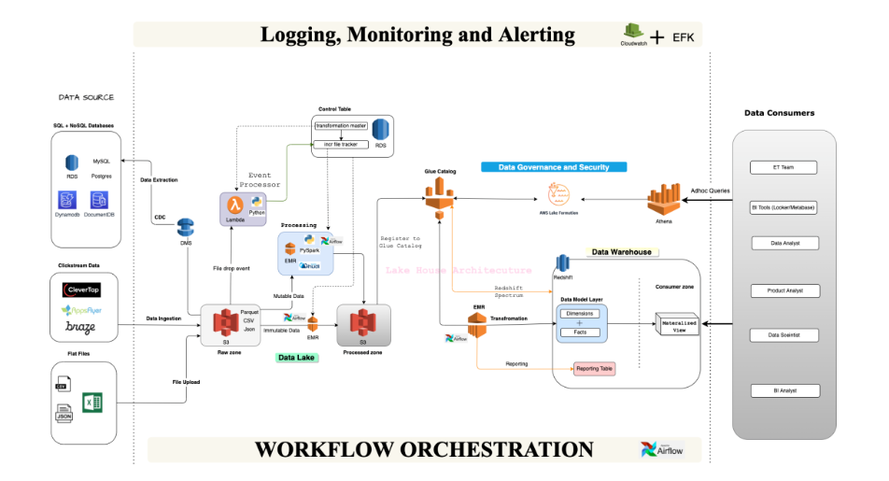
我們將架構分為 4 層:
1. 數據攝取/提取層
該層更關心在原始區域層中攝取數據,這些數據可以稍后在已處理區域中使用和卸載。大多數點擊流捕獲工具都支持來自其產品的內部數據攝取服務,從而可以輕松獲取或加入原始區域以進行進一步處理。對于 MySQL、Postgres 等事務性數據源,我們開始利用基于 CDC 的方法進行數據提取。由于我們的基礎設施主要托管在 AWS 中,因此我們選擇了數據遷移服務 (DMS) 來執行基于 CDC 的遷移。
2. 處理層
這里我們沒有執行任何繁重的轉換,而是將原始數據轉換為 HUDI 數據集。源數據以不同的格式(CSV、JSON)攝取,需要將其轉換為列格式(例如parquet),以將它們存儲在 Data Lake 中以進行高效的數據處理。數據類型基于數據湖兼容性進行類型轉換,時區調整為 WIB 時間戳。
3. 轉換層
數據工程的一大挑戰是有效地處理大量數據并保持成本不變。我們選擇 Apache Spark 進行處理,因為它支持分布式數據處理,并且可以輕松地從千兆字節擴展到 TB 級數據處理。轉換層在數據倉庫中生成數據模型,并成為報表使用數據并支持儀表板或報表用例的基礎。
4. 報告層
報告層主要從維度和事實表中聚合數據,并在這些數據庫之上提供視圖供下游用戶使用。大多數儀表板將建立在這些報告表和物化視圖之上,從而減少為重復性任務和報告用例連接不同表的計算成本。一旦我們將平臺實現為不同的層,下一個挑戰就是選擇能夠支持我們大多數下游用例的組件。當我們調研市場上的數據工程工具/產品時,我們可以輕松找到大量工具。我們計劃利用 AWS 云和開源項目構建內部解決方案,而不是購買第三方許可工具。
讓我們更深入地了解上述平臺中使用的組件。
涉及的組件:
(1) 管理系統
DMS 代表數據遷移服務。這是一項 AWS 服務,可幫助在 MySQL、Postgres 等數據庫上執行 CDC(更改數據捕獲)。我們利用 DMS 從 MySQL DB 讀取二進制日志并將原始數據存儲在 S3 中。我們已經自動化了在 Flask 服務器和 boto3 實現的幫助下創建的 DMS 資源。我們可以輕松地在控制表中配置的原始區域參數中加入新表。
(2) S3 - 原始區域
DMS 捕獲的所有 CDC 數據都存儲在 S3 中適當分區的原始區域中。該層不執行數據清洗。只要源系統中發生插入或更新,數據就會附加到新文件中。原始區域對于在需要時執行數據集的任何回填非常重要。這還存儲從點擊流工具或任何其他數據源攝取的數據。原始區域充當處理區域使用數據的基礎層。
(3) EMR - HUDI + PySpark
Apache HUDI 用于對位于 Data Lake 中的數據利用 UPSERT 操作。我們正在運行 PySpark 作業,這些作業按預定的時間間隔運行,從原始區域讀取數據,處理并存儲在已處理區域中。已處理區域復制源系統的行為。這里只是發生了一個 UPSERT 操作并轉換為 HUDI 數據集。
(4) S3 - 處理區
S3 處理層是 Halodoc 的數據湖。我們存儲可變和不可變數據集。HUDI 被用于維護可變數據集。CSV 或 JSON 數據等不可變數據集也被轉換為列格式(parquet)并存儲在該區域中。該層還維護或糾正分區以有效地查詢數據集。
(5) Glue數據目錄
AWS Glue 數據目錄用于注冊表,并可通過 Athena 進行查詢以進行臨時分析。
(6) Athena
Athena 是一個無服務器查詢引擎,支持查詢 S3 中的數據。用戶利用 Athena 對位于數據湖中的數據集進行任何臨時分析。
(7) Redshift
Redshift 用作數據倉庫來構建數據模型。所有報告/BI 用例均由 Redshift 提供服務。我們在 Redshift 中創建了 2 個圖層。一層負責存儲包含事實和維度的 PD、CD、Appointments、Insurance 和 Labs 的所有數據模型。我們已經構建了一個報告層框架來進行聚合和連接,以創建可通過 BI 工具訪問的報告表。我們還在這些層中維護物化視圖。我們還在我們的數據模型中實現了 SCD type1 和 SCD type2,以捕捉數據集中的歷史變化。
(8) MWAA
MWAA 用于編排工作流程。
(9) Cloud Watch和EFK
Cloud Watch 和 EFK 相結合,構建集中的日志記錄、監控和警報系統。
(10) Dynamicdb
平臺中使用 Dynamodb 將失敗的事件存儲在控制表中發布。開發了一個再處理框架來處理失敗的事件并按預定的頻率將它們推送到控制表。
二、為什么選擇基于 CDC 的方法?
在 Halodoc,當我們開始數據工程之旅時,我們采用了基于時間戳的數據遷移。我們依靠修改后的時間戳將數據從源遷移到目標。我們幾乎用這個管道服務了 2 年。隨著業務的增長,我們的數據集呈指數級增長,這要求我們將遷移實例增加到更大的集群以支持大量數據。
問題如下:
- 由于源處生成的大量數據導致遷移集群大小增加,因此成本高。
- 由于某些后端問題,未更新已修改列時的數據質量問題。
- 架構更改很難在目標中處理。
- 在基于 CDC 的情況下,我們通過在 MySQL 中啟用 binlog(二進制日志)和在 Postgres 中啟用 WAL(預寫日志)來開始讀取事務數據。提取每個事件更改的新文件是一項昂貴的操作,因為會有很多 S3 Put 操作。為了平衡成本,我們將 DMS 二進制日志設置為每 60 秒讀取和拉取一次。每 1 分鐘,通過 DMS 插入新文件。基于 CDC 還解決了數據量大增長的問題,因為我們開始以最大分鐘間隔遷移,而不是每小時間隔數據。
三、使用Apache Hudi
HUDI 提供內置功能來支持開放數據湖。在我們的平臺中加入或集成 HUDI 時,我們面臨以下一些挑戰并試圖解決它們。
1. 保留 HUDI 數據集中的最大提交
HUDI 根據配置集清理/刪除較舊的提交文件。默認情況下,它已將保留的提交設置為 10。必須根據一個工作負載正確設置這些提交。由于我們在 5 分鐘內運行了大部分事務表遷移,因此我們將 hoodie.cleaner.commits.retained 設置為 15,以便我們有 75 分鐘的時間來完成 ETL 作業。甚至壓縮和集群添加到提交,因此必須分析和設置更清潔的策略,以使增量查詢不間斷地運行。
2. 確定要分區的表
在數據湖中對數據進行分區總是可以減少掃描的數據量并提高查詢性能。同樣,在湖中擁有大分區會降低讀取查詢性能,因為它必須合并多個文件來進行數據處理。我們選擇我們的數據湖來進行最小的每日分區,并計劃將歷史數據歸檔到其他存儲層,如 Glacier 或低成本的 S3 存儲層。
3. 選擇正確的存儲類型
HUDI 目前支持 2 種類型的存儲,即。MoR(讀取時合并)和 CoW(寫入時復制)。必須根據用例和工作負載精確選擇存儲類型。我們為具有較低數據延遲訪問的表選擇了 MoR,為可能具有超過 2 小時數據延遲的表選擇了 CoW。
4. MoR 數據集的不同視圖
MoR 支持 _ro 和 _rt 視圖。_ro 代表讀取優化視圖,_rt 代表實時視圖。根據用例,必須確定要查詢哪個表。我們為 ETL 工作負載選擇了 _ro 視圖,因為數據模型中的數據延遲約為 1 小時。建立在數據湖之上的報告正在查詢 _rt 表以獲取數據集的最新視圖。
5. HUDI 中的索引
索引在 HUDI 中對于維護 UPSERT 操作和讀取查詢性能非常有用。有全局索引和非全局索引。我們使用默認的bloom索引并為索引選擇了一個靜態列,即非全局索引。我們依靠 HUDI 提交時間來獲取增量數據。這也有助于將遲到的數據處理到要處理的數據湖,而無需任何人工干預。
五、為什么框架驅動
我們之前的大部分實施都是管道驅動的,這意味著我們為每個數據源手動構建管道以服務于業務用例。在 Platform 2.0 中,我們對實現模型進行了細微的更改,并采用了框架驅動的管道。我們開始在每一層上構建一個框架,例如數據攝取框架、數據處理框架和報告框架。每個框架都專用于使用預定義的輸入執行某些任務。采用框架驅動減少了冗余代碼,以維護和簡化數據湖中新表的載入過程。
1. 使用表格格式的控制平面的好處
在我們的平臺中,控制平面是一個關鍵組件,用于存儲元數據并幫助輕松載入數據湖和數據倉庫中的新表。它存儲啟用數據遷移所需的必要配置。對于構建任何產品,元數據在自動化和控制管道流程方面起著至關重要的作用。在 Yaml、DynamoDB 或 RDBMS 中,我們有不同的選項可供選擇。我們選擇 RDS 的原因如下:
- 輕松在元數據之上執行任何分析,例如活動管道的數量。
- 易于載入新表或數據模型。
- 借助 python flask API 輕松構建 API 層。
- 審計可以很容易地完成。
- 數據安全
在醫療保健領域,安全一直是我們數據平臺中啟用的重中之重。我們在私有子網中托管了幾乎所有基礎設施,并啟用 Lake Formation 來管理對 Data Lake 的訪問。我們還對靜態數據使用 AWS 加密。這提供了數據湖和整體數據平臺的安全存儲。
2. 自動化
自動化總是有助于減少構建和維護平臺的工程工作量。在 Platform 2.0 中,我們的大部分流水線都使用 Jenkins 和 API 實現自動化。我們通過部署燒瓶服務器并使用 boto3 創建資源來自動創建 DMS 資源。
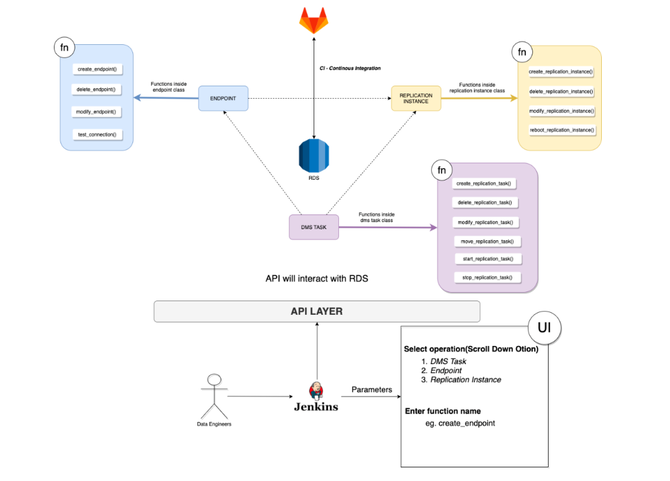
我們幾乎所有的基礎設施/資源都是通過 Terraform 創建的。SRE 在建立我們的大部分數據平臺基礎設施方面發揮了重要作用。
3. 記錄、監控和警報
盡管我們的基礎設施是健壯的、容錯的和高度可擴展的,但有時會出現可能導致基礎設施停機的意外錯誤。為了識別和解決這些問題,我們使用 Cloud watch 和 EFK(Elasticsearch、Fluentbit 和 Kibana)堆棧對我們數據平臺中涉及的每個組件啟用了監控和警報。
4. 工作流程編排
任何數據平臺都需要調度能力來運行批處理數據管道。由于我們已經在之前的平臺中使用 Airflow 進行工作流編排,因此我們繼續使用相同的編排工具。MWAA 已經在減少維護工作量和節省成本方面發揮了很大作用。我們在之前的博客中解釋了我們在 MWAA 中評估的內容。
五、概括
在這篇文章中,我們查看了 Lake House 架構、構建平臺 2.0 所涉及的所有組件,以及我們將 HUDI 用作數據湖的關鍵要點。由于我們現在已經構建了 Data Platform 2.0 的基礎部分,接下來我們計劃專注于平臺的以下方面:
- 數據質量 -> 維護整個數據存儲的數據檢查和數據一致性。
- 數據血緣 -> 提供數據轉換的端到端步驟。
- BI 團隊的自助服務平臺 -> 減少對 DE 團隊對入職報告表的依賴。
- 處理遲到的維度:保持我們的數據模型的一致性,并處理從湖到倉庫的遲到的維度鍵。