MySQL批量導入數據時,為何表空間膨脹了N倍
問題緣起
同事在客戶現場利用DTS工具,從A實例將數據遷移到B實例過程中,發現幾乎稍大點的表在遷移完成后,目標端表空間大小差不多都是源端的3倍,也就是說表空間膨脹了2倍。
排查思路
對這篇文章 《葉問》第16期 有印象的話,應該還能記得,數據遷移(導入導出)過程中,也包括主從復制場景,導致表空間膨脹的原因有幾種:
- MySQL表默認是InnoDB引擎且目前索引只支持B+樹索引,在數據的增刪改過程中,會因為page分裂而導致表產生碎片,主從服務器上同張表的碎片率不同也會導致表空間相差很大。
- 主庫整理過碎片(相當于重建整表),從庫則是從原先的未整理的物理備份中恢復出來的。
- 兩端表結構不一致,如從庫可能比主庫多索引。
- 兩端表的行格式不一致,如主庫為dynamic,從庫為compressed。
- 兩端字符集不同,例如源端是latin1,目標端是utf8mb4。
- 個別云數據庫在從庫上可能采用特殊的并行復制技術,導致在從庫上有更高的碎片率(有個極端的案例,同一個表在主庫只有6G,從庫上則有將近150G)。
- 數據表上沒有自增ID作為主鍵,數據寫入隨機離散,page頻繁分裂造成碎片率很高。
問題發現
順著上面的思路,逐一排查,看能否定位問題原因。
- 因素1,不存在,這是全量遷移場景,不是在日常隨機增刪改的過程中導致膨脹的。
- 因素2,不存在,這是利用DTS工具遷移數據的場景。
- 因素3、4、5,不存在,兩邊表結構一致。
- 因素6,不存在,原因同2。
- 因素7,不存在,每個表都有自增ID作為主鍵。
排查到這里,就顯得有點詭異了,似乎遇到了玄學問題。不過沒關系,我們還需要先了解DTS工具的工作方式,大致如下:
- 計算數據表總行數。
- 根據batch size,分成多段并行讀取數據;例如總共10000行數據,batch size是1000,則總共分為10次讀取數據。
- 將讀取出來的數據拼接成INSERT...VALUES...ON DUPLICATE KEY UPDATE?,因為DTS工具要支持增量遷移數據,所以才加上 ON DUPLICATE KEY UPDATE 子句。
- 將拼接后的SQL并行寫入到目標端。
初看上述工作過程,似乎也沒什么特別之處會導致數據寫入后產生大量碎片,從而表空間文件急劇膨脹。
首先,讀取數據階段只涉及到源端,可以先排除了。所以,疑點集中在第3、4兩步。
了解InnoDB引擎特點的話應該知道,當InnoDB表有自增ID作為主鍵時,如果寫入的數據總是順序遞增的話,那么產生碎片的概率就會很低。但是,如果寫入的數據是離散化的(比如插入的順序是隨機離散的,或者比如插入順序為1、10000、2、3000、3、5000...這種完全離散無序的),則有極大可能會造成碎片率很高。
按照上述疑點,我們需要確認DTS工具構造的SQL是什么樣的,這就需要修改選項 binlog_format = statement,這是為了獲取其原生的SQL,row模式下可能就相對不好排查了。然后再次運行DTS工具,查看生成的SQL。
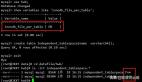
經過排查,終于發現問題所在,原來是DTS工具在拼接SQL時,雖然是分段讀取數據,但沒有將讀取出來的結果集先行排序,造成了拼接后的SQL大概像下面這樣的:
這種方式寫入的話,而且還是并發寫入,就會極大概率造成InnoDB data page頻繁分裂,所以表空間文件才膨脹到原來的3倍之巨。原因不難理解,就好比排隊機制,本來我們是按照身高順序排,但現在有幾位高個子的先排在前面了,那么后來的每次都要讓這幾個人頻繁往后移動才行,這就造成了data page分裂,產生大量碎片。
我用幾萬條sysbench標準表做測試,采用這種方式寫入的話,大概會造成約20%的表空間膨脹率。
問題已然明確,只需要在讀取數據拼接插入SQL這個階段,先行對結果集進行排序,就可以完美解決這個問題了。
并順手給負責SQL優化器的同學提了個feature request(MySQL bug#109087),希望能在遇到上述倒序INSERT的情況下,自動完成SQL改寫,改倒序為正序(或者說,INSERT的順序和表主鍵定義的順序一致,通常都是正序的INT),也就可以完美避開這類風險了。