圖數據導入技術性能優化實踐

1、背景介紹
圖數據是NoSQL非關系型數據類型的一種,通過應用圖形理論來存儲表示實體之間的關系信息,如社交網絡中人與人之間的關系、知識圖譜中實體間的連接關系等。圖數據庫的獨特設計,很好的彌補了關系數據庫不適用于存儲圖形數據、查詢邏輯復雜、查詢速度緩慢的缺點。因此,圖數據庫已廣泛應用于社交網絡、精準推薦、金融風控、知識圖譜等領域。
數據導入功能作為大批量圖數據應用的第一個且比較關鍵的環節,在開展圖應用過程中非常重要。經過調研,市場上比較主流的圖數據庫有Neo4j,NebulaGraph,TigerGraph,JanusGraph,HugeGraph,DGraph等多個國內外廠商。本文主要選取Neo4j,NebulaGraph,JanusGraph三種圖數據庫作為研究對象,深入對比分析各自在數據導入方面的特點,最后介紹下我們在數據導入技術方面的解決方案。
1.1 NebulaGraph圖數據庫
NebulaGraph是一款開源的分布式原生圖數據庫,采用shared-nothing分布式架構設計,擅長處理千億節點萬億條邊的超大規模數據集,并且提供毫秒級查詢。它采用計算和存儲分離的架構模式,基于RocksDB作為本地存儲引擎自研了高性能的KVStore,采用Raft協議保證分布式系統的多副本強一致性和高可用性。
NebulaGraph在數據導入方面提供了多種工具組件操作,如Importer、Console、Studio、Exchange等,其中Console是控制端使用命令行方式導入,適用于操作少量手工測試數據;Studio組件可以通過瀏覽器導入本地機器上多個csv文件,只限制使用csv類型;Importer工具可以導入單機多個csv文件,一般數據量限制在億級以內使用;Exchange組件基于Spark分布式集群,可以從csv、Hive、Neo4j、MySQL等多種數據源導入大批量數據集,支持十億級以上數據;Spark-connector組件使用需要有一定的軟件研發能力,撰寫少量代碼。
每種工具的使用復雜度和導入速度可從下面的坐標圖看出:

1.2 JanusGraph圖數據庫
JanusGraph是一款開源的分布式圖數據庫,基于Apache TinkerPop3框架開發,采用Gremlin查詢語言,具備完善的工具鏈組件,助力用戶輕松構建基于圖數據庫之上的應用和產品。JanusGraph在存儲層設計中,支持分布式存儲、數據多副本、橫向擴容,內置多種后端存儲引擎,并且可通過插件方式集成第三方存儲來擴展后端存儲引擎,如Cassandra、HBase、BerkeleyDB等數據中間件。
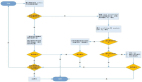
JanusGraph圖數據庫提供如下幾種數據導入方式:
? Api數據導入:該方案通過提交java api插入數據請求,可用于數據量較小的情況下使用;
? 基于Gremlin Server的批量數據導入:該方案通過gremlin語句提交插入請求,需搭建Gremlin Server服務,要有一定的研發能力;
? 基于Bulk Loader組件導入:官方提供批量導入方式,需要Hadoop/Spark集群環境,支持json、csv、xml、kryo等類型,可用于大批量數據導入。
JanusGraph數據導入流程如下圖所示:

1.3 Neo4jGraph圖數據庫
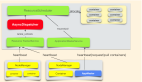
Neo4j是一款由Java開發的半開源圖數據庫,采用Cypher查詢語言,支持快速數據庫操作和直觀的圖數據展示,且操作速度不會隨數據量增大而明顯降低。Neo4J采用原生圖存儲設計,在存儲節點時使用了"index-free" adjacency模型,每個節點都有指向其鄰居節點的指針,可在O(1)的時間內找到鄰居節點,提供快速、高效的圖遍歷。
Neo4j支持以下幾種數據導入方式:
? 基于Cypher語法中的Load-csv方式:官方提供的ETL工具,僅支持csv文件,導入速度慢,需掌握 Cypher 語言,適用于小批量數據;
? Neo4j-import導入工具:官方自帶的大數據量導入工具,支持并行可擴展的大規模csv文件導入,適用于初始化數據在千萬級以上的數據;
? BatchInserter導入工具:一種API數據導入方案,只能在Java中使用,導入速度很快,適用于千萬級以上大批量數據操作。
Neo4j圖數據庫架構設計圖如下:

綜合比較以上多種圖數據庫的數據導入能力情況,我們選取NebulaGraph國產圖數據庫的Exchange組件作為重點研究對象,它是一款Apache Spark應用,基于Apache 2.0協議開放源代碼,支持多種不同格式、不同來源的數據,如:csv、json、hdfs、hive、MySQL、kafka、Neo4j等,我們將從代碼架構優化、依賴集群調優、存儲層結構優化等多個方面對組件的導入能力做優化。
2、數據導入優化技術點
經過調查對比研究,當前圖數據導入功能存在導入效率不高、數據源形式限制嚴格、工具操作復雜等問題,我們將以Exchange組件為基礎,從導入流程框架優化、Spark集群調優策略、存儲層RocksDb組件優化等不同維度研究提升數據導入效率,從而最大限度的縮短大批量數據導入時間,豐富導入數據源形式,節省使用人員的時間成本。
數據導入組件技術流程設計如下:

2.1 Exchange組件優化
Exchange是基于Spark組件編寫的一款應用,主要功能是將集群中多種不同格式的批式數據和流式數據批量導入到圖數據庫中。
我們通過設計并優化“Reader-Processor-Writer”三層數據導入模型,并引入并發編程模型多線程處理不同點和不同邊的數據處理過程,其中Reader層讀取不同來源的批數據并生成分布式數據集 DataFrame,Processor層負責讀取DataFrame中的批數據,通過提取圖數據的結構特點,根據配置文件中設定的映射關系按列名獲取對應值,在讀取到指定批處理的數據后,Writer層負責將獲取到的批數據一次性寫入到圖數據庫中。在整個處理流程中,部分參數設定對處理速率影響較大,如batch(指定單批次寫入圖數據庫的最大點邊數量)、partition(指定 Spark分片數量)、rate.limit(指定導入數據時令牌桶令牌數量限制)等,如何根據機器資源環境合理的設置相應的參數非常重要。
在數據導入流程中,以充分利用spark分布式引擎資源為目的,根據服務器資源使用情況、數據插入速率和響應時間等因素,通過設計集群動態參數自適應策略,動態調整batch單次批量插入數據量,以及spark集群partition分區數,合理的分區數能減少任務調度時間及數據傾斜問題,快速并行處理RDD數據集,最大程度利用集群性能,提升數據轉換效率。同時,設計RateLimiter限流機制,采用令牌桶算法控制圖數據庫單次gql數據插入量,保證在處理大批量數據時圖數據庫能正常平穩運行。另外,利用斷點續傳能力,把上一階段未轉換完的數據(網絡中斷等原因),通過保存斷點方式繼續轉換,提升數據轉換穩定性。
大批量圖數據導入流程架構圖設計如下:

2.2 Spark集群優化
Spark是一種基于內存的快速、通用、可擴展的大數據分析計算引擎,Exchange是基于Spark編寫的一款應用,它基于Spark的分布式環境將集群中的數據批量遷移到圖數據庫中,如何充分利用好分布式集群資源,是提高Exchange數據導入效率的一個關鍵點。
我們在編寫好Exchange組件代碼程序后,按照Spark約定使用spark-submit命令提交運行,Spark支持local、standalone、mesos、yarn四種運行模式,生產環境推薦使用yarn集群模式運行,我們使用此模式進行任務運行及調試。
通過一系列的調優對比測試,結合官網等資料說明,總體來講要充分壓榨使用集群資源,在資源限制內盡量多的調配內存消耗和增加并發。在應用運行調優過程中,需根據當前Spark集群配置來設置調優各個參數,以減少任務調度時間及數據傾斜問題,最大化提升數據運行效率。
? 個別重要參數簡要說明如下:num-executors 根據集群服務器臺數來參考設置,executor-cores根據每臺機器CPU核數來設置,driver-memory和execute-memeory根據總的內存來設置,其中num-executors * execute-memory不能超過集群可用內存等。
2.3 Storage存儲層優化
圖存儲的主要數據是點和邊,Nebula圖數據庫將點和邊的信息存儲為key,同時將點和邊的屬性信息存儲在value中,以便更高效地使用屬性過濾。Nebula在Storage層使用RocksDB作為存儲組件,RocksDB是一個可插拔式的持久化存儲系統,基于LSM架構,支持高效的讀寫吞吐,具備和分布式存儲系統類似的術語操作定義,如 WAL,Compact,Transaction等。
作為分布式存儲引擎的一個存儲媒介,在方案設計時為了保證數據一致性,RocksDB整個寫入鏈路會先寫WAL,再寫memtale,其中WAL保證了數據的高可用性,在宕機時可根據WAL恢復數據。
在存儲層的參數配置上,RocksDB中部分比較重要的參數介紹如下:rocksdb_block_cache,設置默認塊緩存大小,用來緩存解壓后的數據,建議設置為節點有效負載內存的1/3左右;max_background_jobs,設置后臺工作子線程數,加快壓縮效率,建議設置為節點機器的有效可用核數;max_subcompactions,設置壓縮線程數。
上述參數可結合數據導入配置中batch等參數一起調試使用,進而選擇與當前環境資源比較匹配的一個理想參數配置。
存儲層數據寫入流程圖如下:

3、總結
上面是我們在大批量圖數據導入功能總結的一些優化經驗,經過多種策略調優設計,測試報告顯示在同等資源下億級數據量優化前后導入性能提升了12.66%。軟件優化是一項無止境的系統工程,除了上面我們提到的這些調優策略之外,還有很多其它的處理手段我們沒有發現,希望大家能繼續探索研究,多多交流。