Golang數據結構性能優化實踐
如果你有Golang開發經驗,一定定義過struct類型。
但可能你不知道,通過簡單的重新排序struct字段,可以極大提高Go程序的速度和內存使用效率!
是不是難以置信?我們一起來看一下吧!

簡單Demo
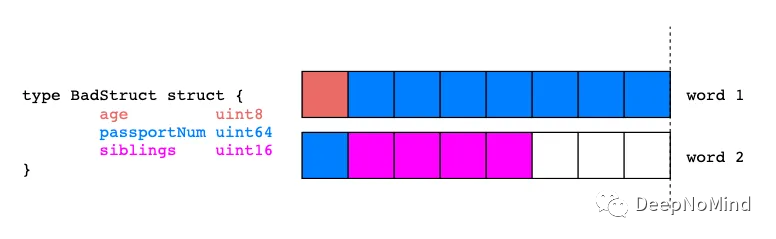
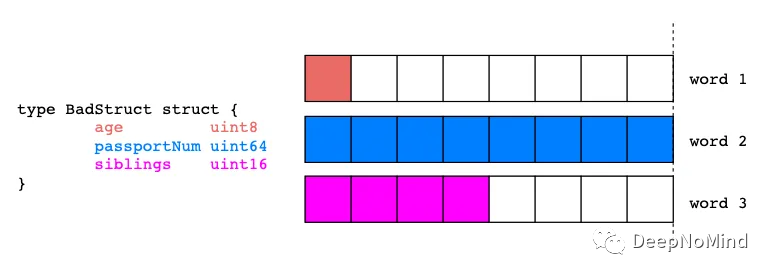
type BadStruct struct {
age uint8
passportNum uint64
siblings uint16
}
type GoodStruct struct {
age uint8
siblings uint16
passportNum uint64
}在上面的代碼片段中,我們創建了兩個具有相同字段的結構體。然后編寫一個簡單程序分別輸出其內存使用情況。
// Output
Bad struct is 24 bytes long
Good struct is 16 bytes long如你所見,它們在內存使用方面并不一樣。
是什么原因導致兩個完全相似的struct消耗的內存不同?
答案在于數據在計算機內存中的排列方式。
簡而言之,數據結構對齊。
數據結構對齊
CPU以字(word)為單位讀取數據,而不是字節(byte)。
64位系統中,一個word是8個字節,而32位系統中,一個word是4個字節。
簡而言之,CPU以其字長的倍數讀取內存地址。
想象一下,在64位系統中,為了獲取變量passportNum,CPU需要兩個周期來訪問數據。
第一個周期將獲取內存的0到7字節,下一個周期獲取其余內存字節。
把它想象成一個筆記本,每頁只能存儲一個字大小的數據(在本例中為8字節)。如果passportNum分散在兩個頁,則需要兩次讀取才能檢索到完整的數據。
非常低效。
因此需要數據結構對齊,讓計算機將數據存儲在等于數據大小倍數的地址上。
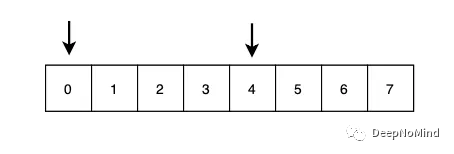
4字節數據只能從內存地址0或4開始
例如,2字節數據可以存儲在內存0、2或4中,而4字節數據可以存儲在內存0、4或8中。
通過簡單的對齊數據,計算機確保可以在一個CPU周期內檢索到變量passportNum。
數據結構填充
填充是實現數據對齊的關鍵。
計算機通過在數據結構之間填充額外的字節,從而對齊字段。
這就是額外內存的來源!
我們來回顧一下BadStruct和GoodStruct。
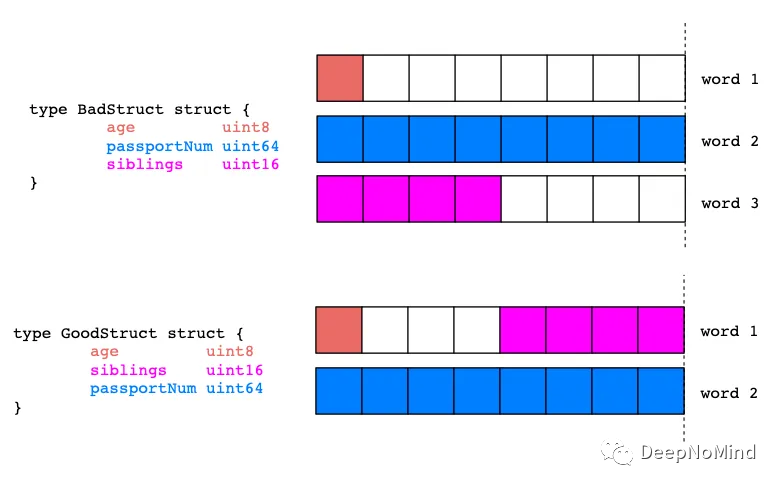
GoodStruct消耗更少的內存,僅僅因為與BadStruct相比,其struct字段順序更合理。
由于填充,兩個13字節的數據結構分別變成了16字節和24字節。
因此,可以僅僅通過對struct字段重新排序來節省額外的內存!
這種優化為什么重要?
問題來了,你為什么要關心這個?
兩個方面,速度和內存使用。
我們做一個簡單的基準測試來證明!
func traverseGoodStruct() uint16 {
var arbitraryNum uint16
for _, goodStruct := range GoodStructArr {
arbitraryNum += goodStruct.siblings
}
return arbitraryNum
}
func traverseBadStruct() uint16 {
var arbitraryNum uint16
for _, badStruct := range BadStructArr {
arbitraryNum += badStruct.siblings
}
return arbitraryNum
}
func BenchmarkTraverseGoodStruct(b *testing.B) {
for n := 0; n < b.N; n++ {
traverseGoodStruct()
}
}
func BenchmarkTraverseBadStruct(b *testing.B) {
for n := 0; n < b.N; n++ {
traverseBadStruct()
}
}對GoodStruct和BadStruct進行基準測試的方法是循環遍歷數組,并將struct字段累加到變量中。
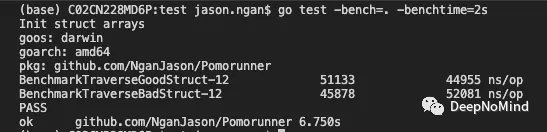
從結果中可以看出,遍歷GoodStruct確實比BadStruct花費時間更少。
對struct字段重排序可以優化應用程序的內存使用和速度。
想象一下,維護一個具有大量結構體的大型應用程序,改變將會更為明顯。
結語
好了,全文到此為止,我們以一個簡單的行動呼吁來結束:一定要對struct結構字段進行重排序!