













無棧協程:用戶態的Linux進程調度
?協程(coroutine),是為了把epoll異步事件變成同步的一種編程模式。
它的出現也就近幾年的事,是隨著go語言而提出的一種編程模式。
因為異步事件編程的可讀性比較差,然后就有了協程。
協程,也被稱為用戶態的進程。
協程的調度,跟Linux內核對進程的調度是類似的。
1,不管是協程、進程、線程,它們都有一個要運行的函數,以及相關的上下文。
函數是它們要運行的代碼,上下文是它們的運行狀態。
pthread庫對線程函數的定義是void* (*run)(void*),它是一個參數和返回值都是void*的函數指針:
這么定義的線程函數,可以給它傳遞任何類型的參數,也可以從它獲取任何類型的返回值。
這個函數,就是線程要運行的函數。
如果是進程的話,main()函數就是它要運行的進程函數。
任何不使用fork()系統調用的進程,都是從main()函數開始運行的。
fork()系統調用之后的(父)子進程,會運行fork()返回之后的代碼,例如:
協程也跟進程、線程類似,也有一個要運行的函數。
另外,無論進程、線程、協程都有一個運行的狀態上下文:
這個上下文里最重要的數據,就是棧!?
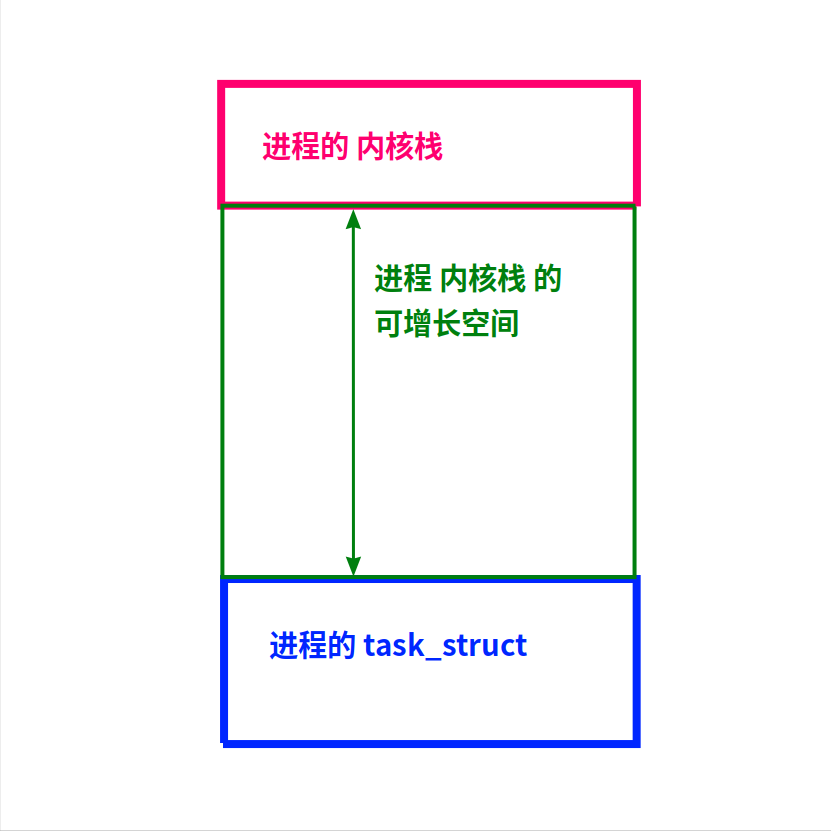
Linux內核的進程的內存布局
函數的局部變量是分配在棧上的,函數調用的返回地址也是在棧上的,各種寄存器也是保存在棧上的。
對于一個正在運行的函數來說,棧必須是獨立的,不能與其他函數共享:因為運行著的函數會隨時修改棧上的數據。
不管是線程、進程、協程,都是這樣。
同一個進程內的不同線程之間雖然會共享全局變量和堆內存,但棧是不能共享的。
在Linux上,線程和進程除了共享全局變量和堆之外,基本上是一回事。
在Linux內核里,它們都用上圖的數據結構描述:
1)最早是4096字節(1個內存頁),后來擴展到8k字節(2個頁)。
2)這8k內存的低地址是進程的描述結構,也就是main()函數運行時需要的信息。
這8k內存的高地址,是進程在內核里運行時(例如執行系統調用時)的(內核)棧。
這兩部分加起來,就是進程的上下文。
所以,在給Linux內核寫模塊時,代碼里不能使用很大的局部變量,以免把進程的描述結構給覆蓋了!
這樣的代碼是不能寫在內核里的,因為局部變量的內存是分配在棧上的,而內核給每個進程配備的棧都很小(8k)。
這一個buf數組就占了4k,那函數調用稍微復雜一點,就可能把低地址的進程結構給覆蓋了。
Linux內核在調度進程的時候,就是不斷地切換上圖的數據結構,從而讓多個進程可以交替運行。
因為調度間隔遠小于人眼能察覺的時間間隔,所以即使在單核CPU上,在人看來也是多進程同時運行的。
2,協程的實現
多個協程要想在用戶態交替運行,也必須為每個協程配備不同的棧。
多個協程都隸屬于同一個進程,而進程棧的位置是被操作系統提前分配好了的。
所以,為每個協程配備棧的時候,每個棧的內存范圍必須在進程棧的范圍內。
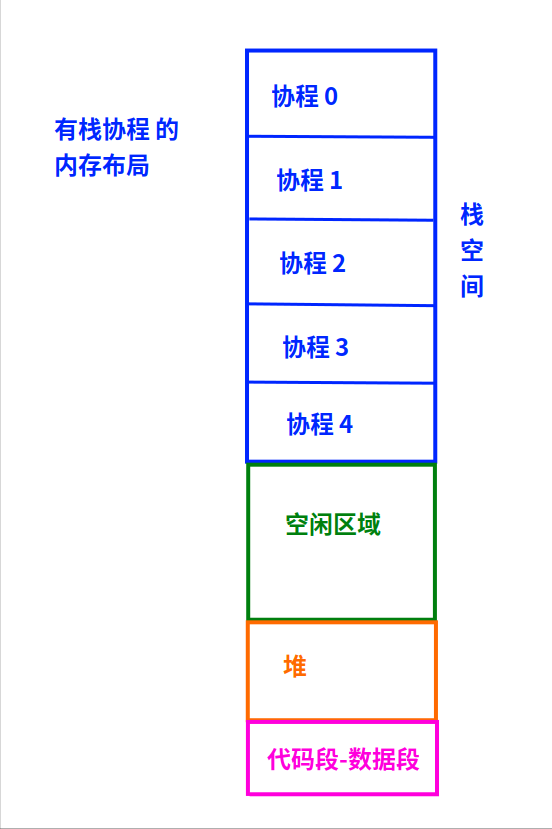
有棧協程的內存布局
如上圖:
你說要在“進程”的棧上給協程提前開多大的空間?
每個協程的棧又要預留多大?
預留小了,協程函數的局部變量把協程的描述結構覆蓋了的事,也會發生的。
預留大了,同一個進程所能支持的總協程數就會減少。
而且,程序員的用戶態代碼一般都比內核代碼更粗放。
寫個用戶態代碼,還不讓我這么開緩沖區 char buf[1024*1024],能行嗎??
沒有哪個程序員愿意,寫個用戶代碼還像寫內核驅動一樣戰戰兢兢的。
所以,有棧協程的劣勢非常明顯!
1)首先,每個進程支持的協程個數是有限的,而不是無限的。
大多數情況下,雖然用戶代碼要開的協程個數也不至于突破上限,但畢竟它是個有限集,不是個可數集。
這對用戶代碼的限制還是比較大的。
有這么個限制,在創建協程的時候就要每次都檢查是否成功。
代碼就是這樣的:
而不是這樣的:
否則代碼就不完善,因為沒有處理異常情況。
2)萬一協程函數里有復雜的遞歸,協程的棧溢出了,那么就可能覆蓋多個協程的數據,導致程序掛了。
可以預見,這種掛的位置幾乎肯定不是第一現場!
這種BUG查起來,還是非常麻煩的。
不掛在第一現場的內存BUG,都是C語言里很難查的BUG,它很大可能是隨機的?
然后,就有了無棧協程。
3,無棧協程
無棧協程的實現也很簡單,只要在切換協程之前,把當前協程的棧數據保存到堆上就可以了。
每個協程的上下文都是用malloc()申請的堆內存,在上下文里預留一個空間,在切換協程時把(當前協程的)棧數據保存到這個預留空間里。
當協程再次被調度運行時,把上次的棧數據從(協程的)上下文里復制到進程棧上,協程就可以再次運行了。
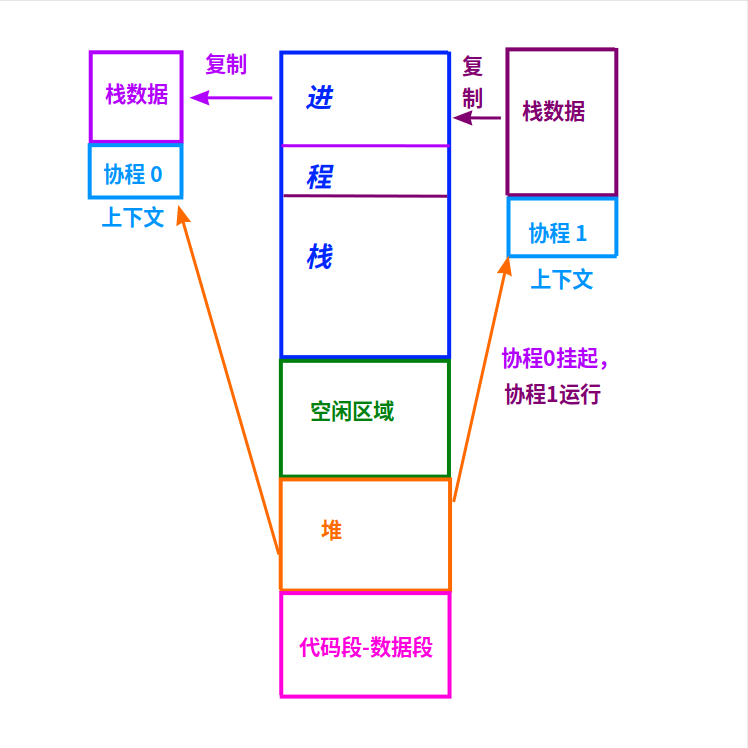
無棧協程的內存布局
如上圖,協程0掛起,協程1被調度運行:
1)先把進程棧上的數據復制到協程0的上下文里。
這時進程棧上的數據,全是協程0的棧數據。
協程的上下文是malloc()申請的堆內存,如果棧數據太大的話,是可以用realloc()再次分配更大的內存的。
這就打破了協程棧的大小固定的缺陷。
每個協程可以使用的棧大小,只受制于進程的棧的大小。
2)當協程的棧不再受到限制之后,可以創建的協程數量也只受制于進程的堆的大小。
只有整個進程的堆內存被耗盡之后,協程的創建和運行才會沒法進行。
我在scf編譯器框架里附帶的那個協程的實現,就是無棧協程?
它在scf/coroutine目錄。
2021年的5月份我就想到了這些問題,并且給了解決的代碼,在github和gitee的scf代碼都有。
2022年以來,我沒往github上更新代碼,目前gitee上的scf是最新的。























