













程序員別死背面試八股文了,這種面試題才是未來主流

1、面試官為啥要出這樣一個開放式問題
?這篇文章簡單給大家來聊一個互聯網大廠的Java面試題:如果讓你設計一個消息中間件,你會怎么做?
其實這個問題之前大致給大家聊過,本質就是面試官在考察一個高級以上的Java工程師的系統設計能力。
給你一個平時大家都常用的一個消息中間件作為命題,讓你現場開放式發揮,立馬開動腦筋說說如果讓你來設計這么一個消息中間件。
讓你從整體架構,核心流程,數據結構,等各個層面來考慮,你會如何完成這個設計?
其實任何一個面試官都應該知道,如果一個人沒有真的做過消息中間件開發的話,是不太可能在短時間內,瞬間給出一套特別靠譜的架構設計方案的。
但是用這個題目作為一個開放式命題,他最大的好處,就是可以盡可能的挖?掘出一個候選人的較為真實的系統設計的能力和功底。
為什么這么說呢?
因為如果面試的時候很多東西都是一些常見的技術問題,比如說:
- 消息中間件如何保證數據不丟失?
- 聊聊Elasticsearch的架構原理以及性能優化?
- 你們公司的微服務架構整體如何設計的?
這些問題相對來說都是比較固定的一些問題。
所謂固定的問題,就是只要你花費一些時間去學習了相關的技術,或者是在自己所在的公司確實有過一些落地的經驗,通常來說回答出這些問題就不是太大的問題了。
但是這些問題都不夠開放,如果兩個候選人都同樣具備常規問題的回答能力,那么此時通過一道有深度的開放式問題,就可以把幾個人里迅速拉開差距,找出來到底誰的技術功底更加深厚,誰的架構設計能力更加強。
那么本文就從各個角度來引導大家去思考一下,假如讓你回答這個問題,你可以從哪些方面入手來現場做一些考慮和回答?
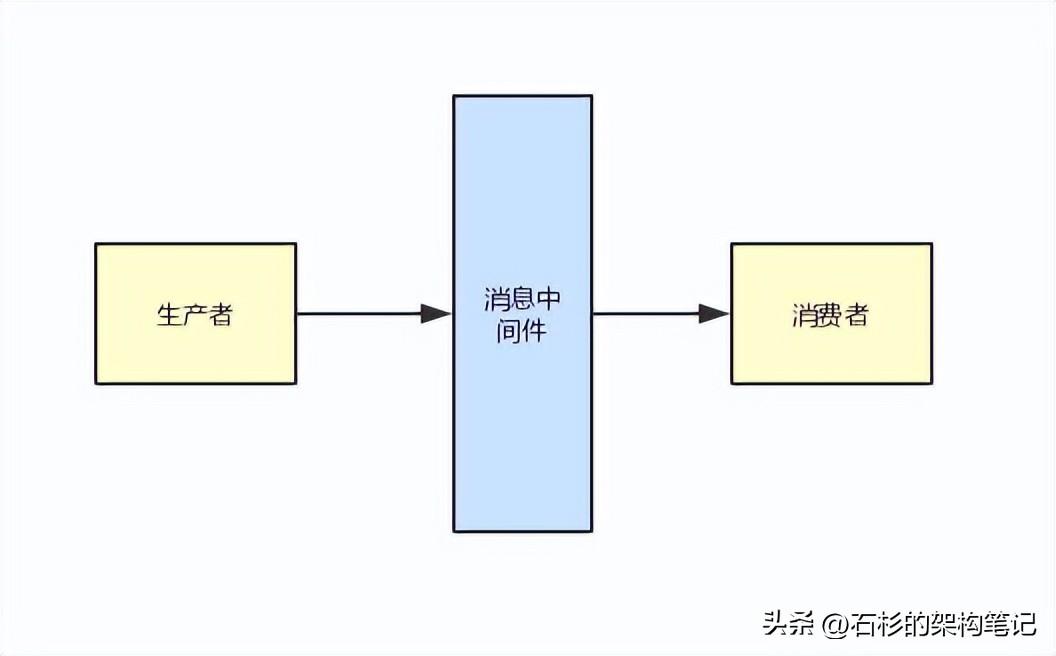
2、生產消費模型以及核心數據結構
首先第一個點,消息中間件本身要做的就是可以允許有人來生產消息,還可以允許有人來消費這個消息。
那么這里要考慮的第一個點,就是消息中間件自己本身的核心數據結構。
也就是說,如果有人生產了消息,你作為一個消息中間件,應該如何存儲這個數據?
你會存儲在內存里呢?還是存儲在磁盤文件里呢?或者兩者都同時共存?
可以先允許數據寫入內存作為一個緩沖,然后每隔幾秒再把數據刷入磁盤文件中?數據刷入磁盤文件之后,這個磁盤文件有多少個?
你總不能一直搞一個磁盤文件來存放所有的數據吧?那么按照什么樣的規則對磁盤文件做一個拆分?
數據寫入磁盤文件之后,是不是要有相應的一些metadata來標識這個數據的具體信息?比如這個數據的offset偏移量,或者是一個內置的唯一id?
接著現在數據是被存儲在磁盤文件里了,那么此時你如何把數據投遞到下游的消費者里去呢?
你的消費模型是什么樣的?比如說一個queue里的數據,是會均勻分配給消費者的各個實例呢?還是會怎么做呢?
在這里給大家做一個提示,建議大家可以去研究研究比如kafka底層的文件存儲原理,那是非常經典的高性能高并發消息中間件存儲架構的實現。
另外就是可以參考一下rabbitmq和kafka的官網,研究一下不同中間件的消費模型是怎么做的。
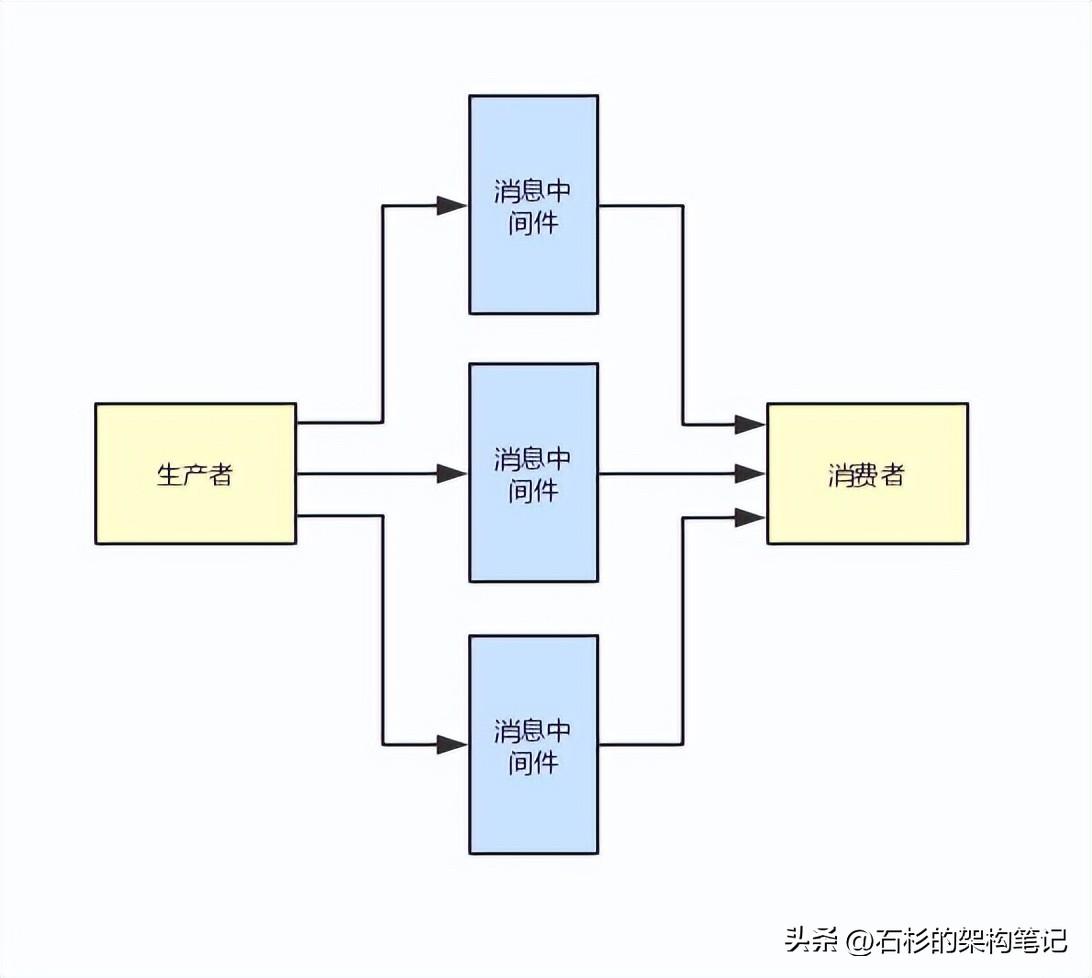
3、支撐TB級數據寫入的分布式架構
接著你應該考慮第二個大的問題,就是你的消息中間件肯定會遇到每天TB級海量數據高并發高吞吐寫入的場景。
此時,你的消息中間件的架構如何支撐呢?
所以這里你就要考慮一下,你的數據是不是要分布式的存儲?
比如說假如你一天寫入幾百TB的數據,那不可能都放在一臺機器上吧?所以數據的分布式存儲是不是你要考慮的另外一個很重要的問題?
你是不是要考慮把一個大的數據集合做分片存儲,比如說分成N片數據,每個數據分片放在一臺機器上,這樣就可以充分利用多臺機器的資源來承載TB級的大量數據了。
此外你還需要考慮,你的數據分片是不是要可以支撐擴容?
比如你一開始設置的分片數量是10個,存在10臺機器上。結果現在發現10臺機器都扛不住了,需要擴容到20個分片,放在20臺機器上才可以。
那你是不是要支持數據分片的擴容以及自動數據負載均衡遷移?也就是10個分片的數據自動均勻分配給擴容后的20個分片。
所以這種分布式以及可伸縮的架構,是另外一個非常核心的點。
我個人同樣比較建議大家研究一下kafka在這塊的架構設計,非常的優秀,采用了partition的概念實現數據分片,支持分布式的數據存儲,而且還支持動態擴容。
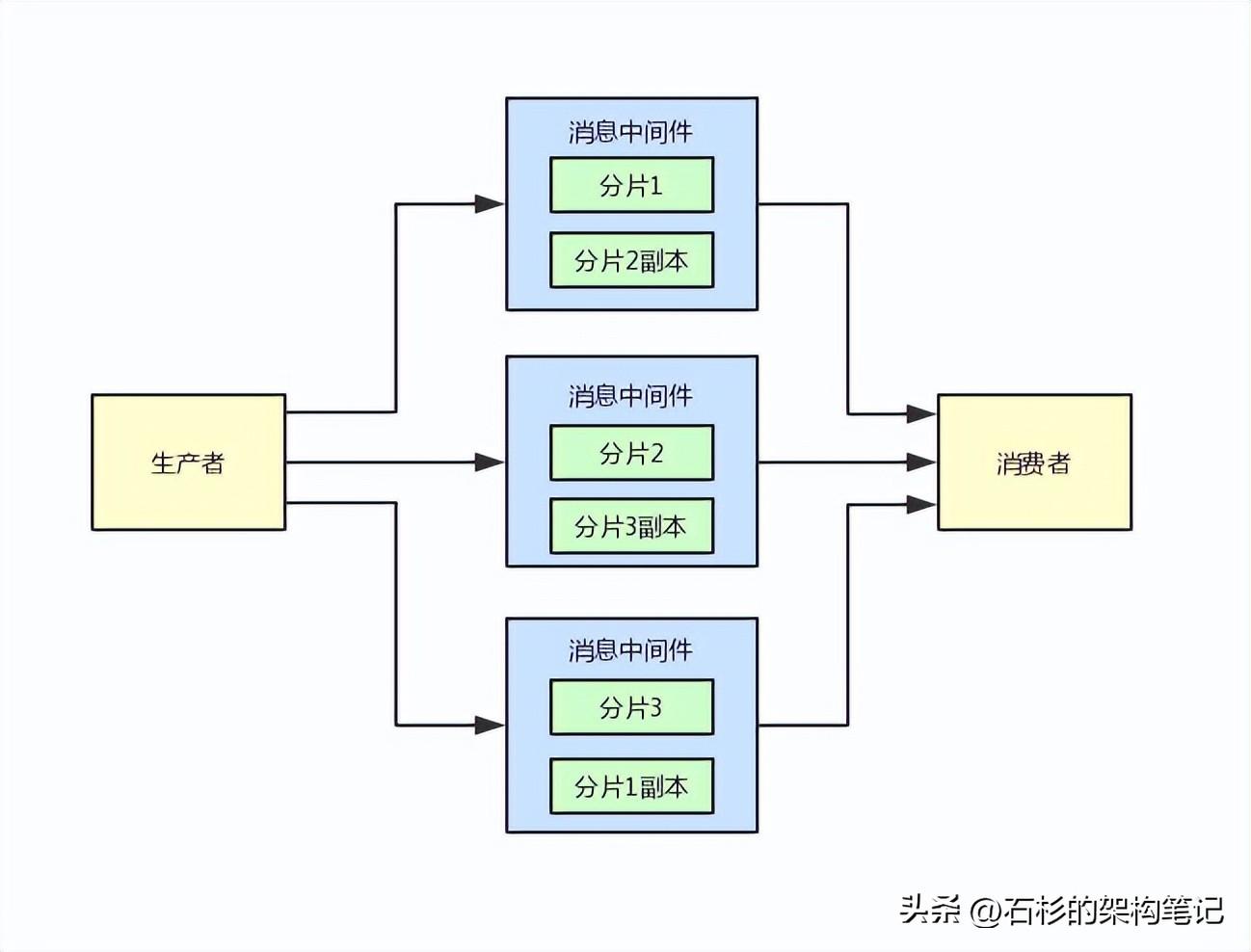
4、數據宕機場景下的高可用架構
大家此時就要考慮另外一個問題了,就是一旦數據分布式存儲之后,那么每臺機器上都有一部分數據。
萬一這臺機器宕機了呢?那么數據是不是就丟失了?
是的!所以高可用的架構在這里就必須考慮到了。
一般分布式系統實現高可用架構,都是采用多副本冗余機制
也就是說一份數據在多臺機器上都搞一個副本,這樣任何一臺機器宕機了,數據肯定不會丟失,你還可以繼續使用其他機器上的副本數據來支持生產和消費。
同樣建議大家,研究一下kafka的多副本冗余機制,他的每個partition數據分片都是有多個副本的,任何一臺機器宕機,丟失一個數據分片,還有其他機器上的副本分片在,可以支持數據不丟失。
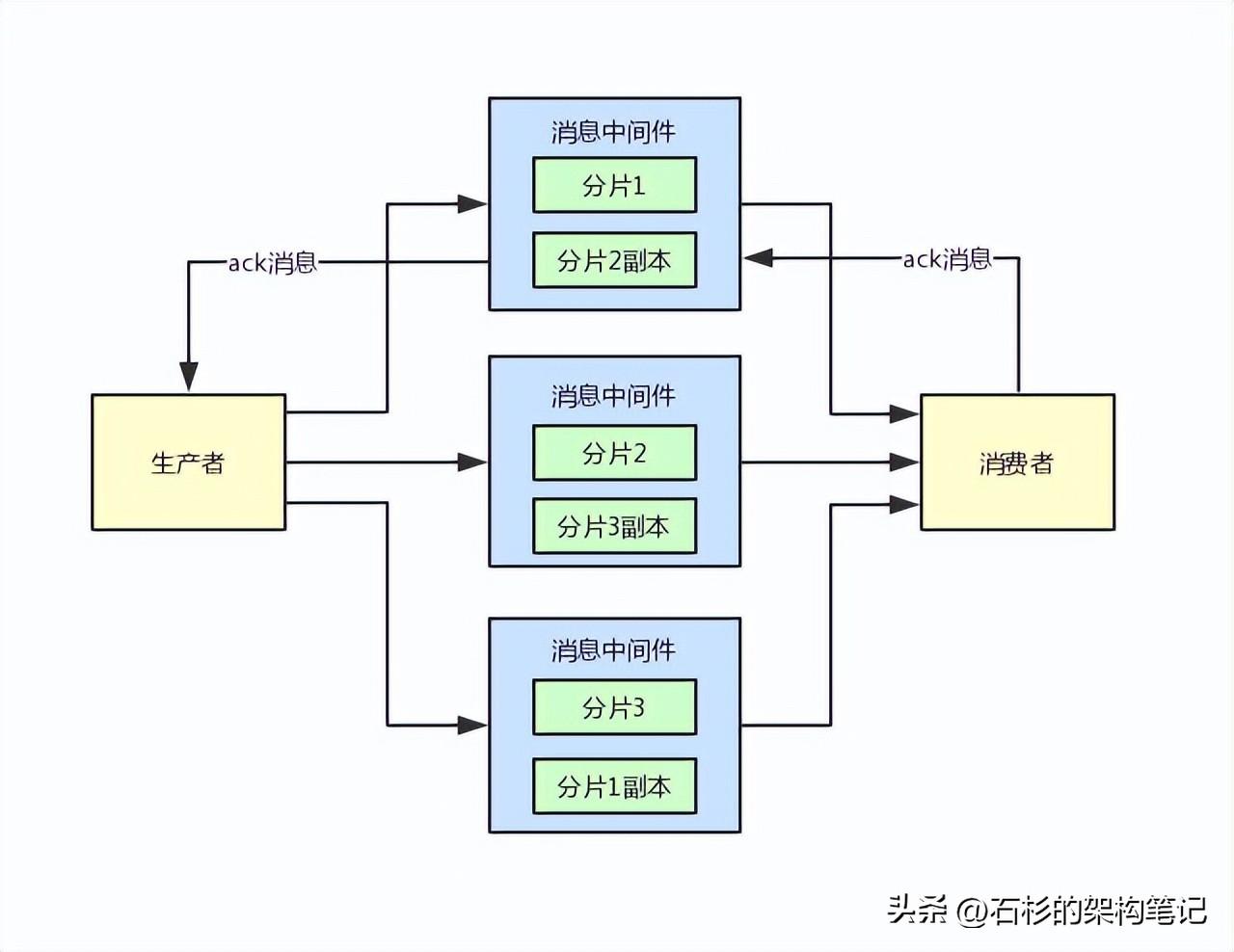
5、支持數據不丟失的ack機制
最后再考慮一個問題,你的消息中間件肯定是要支持數據絕對不丟失的吧?
在這里你必須考慮兩塊ack機制,一個是生產端,一旦投遞了消息,必須要求他將數據比如寫入多個副本之后,才返回一個ack回調響應。
否則要是一直沒收到ack的話,就需要重發一條消息過去,保證生產投遞成功。
另外一個是消費端,一旦消費處理成功一條消息了,必須返回一個ack給消息中間件,然后消息中間件才能刪除這條消息。
否則一旦消費者宕機,就必須重發這條消息給其他的消費者實例,保證消息一定會被處理成功。
這塊如果大家不清楚,建議一定重看之前的系列文章,我們基于rabbitmq來闡述的這個數據不丟失的全鏈路ack機制。
6、最后的總結
這種開放式面試題,牽扯了大量的底層細節和架構思想,非常區分不同人的技術水平。如果你往簡單了回答,就本文涉及到的一些東西簡單說一說,基本也能過關。
但是如果你想技壓群雄,就必須要根據本文每個部分提示的東西,真的去對各種MQ中間件的底層源碼進行深入的研究,然后才能在回答這個問題的時候,展現出“碾壓其他人”的技術功底和架構實力。


















