對 Pulsar 集群的壓測與優(yōu)化

前言
這段時(shí)間在做 MQ(Pulsar)相關(guān)的治理工作,其中一個(gè)部分內(nèi)容關(guān)于消息隊(duì)列的升級,比如:
- 一鍵創(chuàng)建一個(gè)測試集群。
- 運(yùn)行一批測試用例,覆蓋我們線上使用到的功能,并輸出測試報(bào)告。
- 模擬壓測,輸出測試結(jié)果。
本質(zhì)目的就是想直到新版本升級過程中和升級后對現(xiàn)有業(yè)務(wù)是否存在影響。
一鍵創(chuàng)建集群和執(zhí)行測試用例比較簡單,利用了 helm 和 k8s client 的 SDK 把整個(gè)流程串起來即可。
壓測
其實(shí)稍微麻煩一點(diǎn)的是壓測,Pulsar 官方本身是有提供一個(gè)壓測工具;只是功能相對比較單一,只能對某批 topic 極限壓測,最后輸出測試報(bào)告。最后參考了官方的壓測流程,加入了一些實(shí)時(shí)監(jiān)控?cái)?shù)據(jù),方便分析整個(gè)壓測過程中性能的變化。
客戶端 timeout
隨著壓測過程中的壓力增大,比如壓測時(shí)間和線程數(shù)的提高,客戶端會拋出發(fā)送消息 timeout 異常。
而這個(gè)異常在生產(chǎn)業(yè)務(wù)環(huán)境的高峰期偶爾也出現(xiàn)過,這會導(dǎo)致業(yè)務(wù)數(shù)據(jù)的丟失;所以正好這次被我復(fù)現(xiàn)出來后想著分析下產(chǎn)生的原因以及解決辦法。
源碼分析客戶端
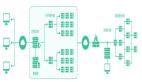
既然是客戶端拋出的異常所以就先看從異常點(diǎn)開始看起,其實(shí)整個(gè)過程和產(chǎn)生的原因并不復(fù)雜,如下圖:

客戶端流程:
- 客戶端 producer 發(fā)送消息時(shí)先將消息發(fā)往本地的一個(gè) pending 隊(duì)列。
- 待 broker 處理完(寫入 bookkeeper) 返回 ACK 時(shí)刪除該 pending 隊(duì)列頭的消息。
- 后臺啟動一個(gè)定時(shí)任務(wù),定期掃描隊(duì)列頭(頭部的消息是最后寫入的)的消息是否已經(jīng)過期(過期時(shí)間可配置,默認(rèn)30s)。
- 如果已經(jīng)過期(頭部消息過期,說明所有消息都已過期)則遍歷隊(duì)列內(nèi)的消息依次拋出PulsarClientException$TimeoutException 異常,最后清空該隊(duì)列。
服務(wù)端 broker 流程:
- 收到消息后調(diào)用 bookkeeper API 寫入消息。
- 寫入消息時(shí)同時(shí)寫入回調(diào)函數(shù)。
- 寫入成功后執(zhí)行回調(diào)函數(shù),這時(shí)會記錄一條消息的寫入延遲,并通知客戶端 ACK。
- 通過 broker metric 指標(biāo)pulsar_broker_publish_latency 可以獲取寫入延遲。
從以上流程可以看出,如果客戶端不做兜底措施則在第四步會出現(xiàn)消息丟失,這類本質(zhì)上不算是 broker 丟消息,而是客戶端認(rèn)為當(dāng)時(shí) broker 的處理能力達(dá)到上限,考慮到消息的實(shí)時(shí)性從而丟棄了還未發(fā)送的消息。
性能分析
通過上述分析,特別是 broker 的寫入流程得知,整個(gè)寫入的主要操作便是寫入 bookkeeper,所以 bookkeeper 的寫入性能便關(guān)系到整個(gè)集群的寫入性能。
極端情況下,假設(shè)不考慮網(wǎng)絡(luò)的損耗,如果 bookkeeper 的寫入延遲是 0ms,那整個(gè)集群的寫入性能幾乎就是無上限;所以我們重點(diǎn)看看在壓測過程中 bookkeeper 的各項(xiàng)指標(biāo)。
CPU
首先是 CPU:

從圖中可以看到壓測過程中 CPU 是有明顯增高的,所以我們需要找到壓測過程中 bookkeeper 的 CPU 大部分損耗在哪里?
這里不得不吹一波阿里的 arthas 工具,可以非常方便的幫我們生成火焰圖。

分析火焰圖最簡單的一個(gè)方法便是查看頂部最寬的函數(shù)是哪個(gè),它大概率就是性能的瓶頸。
在這個(gè)圖中的頂部并沒有明顯很寬的函數(shù),大家都差不多,所以并沒有明顯損耗 CPU 的函數(shù)。
此時(shí)在借助云廠商的監(jiān)控得知并沒有得到 CPU 的上限(limit 限制為 8核)。

使用 arthas 過程中也有個(gè)小坑,在 k8s 環(huán)境中有可能應(yīng)用啟動后沒有成功在磁盤寫入 pid ,導(dǎo)致查詢不到 Java 進(jìn)程。
此時(shí)可以直接 ps 拿到進(jìn)程 ID,然后在啟動的時(shí)候直接傳入 pid 即可。
通常情況下這個(gè) pid 是 1。
磁盤
既然 CPU 沒有問題,那就再看看磁盤是不是瓶頸。

可以看到壓測時(shí)的 IO 等待時(shí)間明顯是比日常請求高許多,為了最終確認(rèn)是否是磁盤的問題,再將磁盤類型換為 SSD 進(jìn)行測試。

果然即便是壓測,SSD磁盤的 IO 也比普通硬盤的正常請求期間延遲更低。
既然磁盤 IO 延遲降低了,根據(jù)前文的分析理論上整個(gè)集群的性能應(yīng)該會有明顯的上升,因此對比了升級前后的消息 TPS 寫入指標(biāo):

升級后每秒的寫入速率由 40k 漲到 80k 左右,幾乎是翻了一倍(果然用錢是最快解決問題的方式);
但即便是這樣,極限壓測后依然會出現(xiàn)客戶端 timeout,這是因?yàn)闊o論怎么提高服務(wù)端的處理性能,依然沒法做到?jīng)]有延遲的寫入,各個(gè)環(huán)節(jié)都會有損耗。
升級過程中的 timeout
還有一個(gè)關(guān)鍵的步驟必須要覆蓋:模擬生產(chǎn)現(xiàn)場有著大量的生產(chǎn)者和消費(fèi)者接入收發(fā)消息時(shí)進(jìn)行集群升級,對客戶端業(yè)務(wù)的影響。
根據(jù)官方推薦的升級步驟,流程如下:
- Upgrade Zookeeper.
- Disable autorecovery.
- Upgrade Bookkeeper.
- Upgrade Broker.
- Upgrade Proxy.
- Enable autorecovery.
其中最關(guān)鍵的是升級 Broker 和 Proxy,因?yàn)檫@兩個(gè)是客戶端直接交互的組件。
本質(zhì)上升級的過程就是優(yōu)雅停機(jī),然后使用新版本的 docker 啟動;所以客戶端一定會感知到 Broker 下線后進(jìn)行重連,如果能快速自動重連那對客戶端幾乎沒有影響。

在我的測試過程中,2000左右的 producer 以 1k 的發(fā)送速率進(jìn)行消息發(fā)送,在 30min 內(nèi)完成所有組件升級,整個(gè)過程客戶端會自動快速重連,并不會出現(xiàn)異常以及消息丟失。
而一旦發(fā)送頻率增加時(shí),在重啟 Broker 的過程中便會出現(xiàn)上文提到的 timeout 異常;初步看起來是在默認(rèn)的 30s 時(shí)間內(nèi)沒有重連成功,導(dǎo)致積壓的消息已經(jīng)超時(shí)。
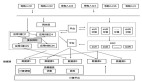
經(jīng)過分析源碼發(fā)現(xiàn)關(guān)鍵的步驟如下:

客戶端在與 Broker 的長連接狀態(tài)斷開后會自動重連,而重連到具體哪臺 Broker 節(jié)點(diǎn)是由 LookUpService 處理的,它會根據(jù)使用的 topic 獲取到它的元數(shù)據(jù)。
理論上這個(gè)過程如果足夠快,對客戶端就會越無感。
在元數(shù)據(jù)中包含有該 topic 所屬的 bundle 所綁定的 Broker 的具體 IP+端口,這樣才能重新連接然后發(fā)送消息。
bundle 是一批 topic 的抽象,用來將一批 topic 與 Broker 綁定。
而在一個(gè) Broker 停機(jī)的時(shí)會自動卸載它所有的 bundle,并由負(fù)載均衡器自動劃分到在線的 Broker 中,交由他們處理。
這里會有兩種情況降低 LookUpSerive 獲取元數(shù)據(jù)的速度:
因?yàn)樗械?Broker 都是 stateful 有狀態(tài)節(jié)點(diǎn),所以升級時(shí)是從新的節(jié)點(diǎn)開始升級,假設(shè)是broker-5,假設(shè)升級的那個(gè)節(jié)點(diǎn)的 bundle 切好被轉(zhuǎn)移 broker-4中,客戶端此時(shí)便會自動重連到 4 這個(gè)Broker 中。
此時(shí)客戶端正在講堆積的消息進(jìn)行重發(fā),而下一個(gè)升級的節(jié)點(diǎn)正好是 4,那客戶端又得等待 bundle 成功 unload 到新的節(jié)點(diǎn),如果恰好是 3 的話那又得套娃了,這樣整個(gè)消息的重發(fā)流程就會被拉長,直到超過等待時(shí)間便會超時(shí)。
還有一種情況是 bundle 的數(shù)量比較多,導(dǎo)致上面講到的 unload 時(shí)更新元數(shù)據(jù)到 zookeeper 的時(shí)間也會增加。
所以我在考慮 Broker 在升級過程中時(shí),是否可以將 unload 的 bundle 優(yōu)先與 Broker-0進(jìn)行綁定,最后全部升級成功后再做一次負(fù)載均衡,盡量減少客戶端重連的機(jī)會。
解決方案
如果我們想要解決這個(gè) timeout 的異常,也有以下幾個(gè)方案:
- 將 bookkeeper 的磁盤換為寫入時(shí)延更低的 SSD,提高單節(jié)點(diǎn)性能。
- 增加 bookkeeper 節(jié)點(diǎn),不過由于 bookkeeper 是有狀態(tài)的,水平擴(kuò)容起來比較麻煩,而且一旦擴(kuò)容再想縮容也比較困難。
- 增加客戶端寫入的超時(shí)時(shí)間,這個(gè)可以配置。
- 客戶端做好兜底措施,捕獲異常、記錄日志、或者入庫都可以,后續(xù)進(jìn)行消息重發(fā)。
- 為 bookkeeper 的寫入延遲增加報(bào)警。
- Spring 官方剛出爐的 Pulsar-starter 已經(jīng)內(nèi)置了 producer 相關(guān)的 metrics,客戶端也可以對這個(gè)進(jìn)行監(jiān)控報(bào)警。
以上最好實(shí)現(xiàn)的就是第四步了,效果好成本低,推薦還沒有實(shí)現(xiàn)的都盡快 try catch 起來。
整個(gè)測試流程耗費(fèi)了我一兩周的時(shí)間,也是第一次全方位的對一款中間件進(jìn)行測試,其中也學(xué)到了不少東西;不管是源碼還是架構(gòu)都對 Pulsar 有了更深入的理解。