全鏈路壓測:影子庫與影子表之爭
作者 | 葛天萌(智云)
一、業界盛傳的全鏈路壓測是什么
?全鏈路壓測誕生于阿里巴巴雙 11 備戰過程,如果說雙 11 大促是阿里業務的“期末考試”,全鏈路壓測就是大考前的“模擬考試”,誕生后被譽為雙 11 穩定性保障的“核武器”。全鏈路壓測通過在生產環境對業務大流量場景進行高仿真模擬,獲取最真實的線上實際承載能力、執行精準的容量規劃,確保系統可用性。分布式架構和業務快速發展給業務系統帶來了不確定性。分布式環境的任意節點都可能成為瓶頸/短板/問題,同時系統可用性隨著業務的快速增長,面臨更嚴峻的挑戰和不確定性。比如:
- 單鏈路壓測缺少外部干擾和各種資源競爭,單鏈路壓測的結果普遍比較樂觀,不能反映真實的系統承載能力。
- 某些問題只有在真正的大流量下才會暴露,比如網絡帶寬、系統間影響、基礎依賴等等。
- 全鏈路壓測不僅僅是做壓測,更多的是進行一次真實的大促預演,預案演練、限流驗證、破壞性演練等高可用方案的統一驗收。
其中全鏈路壓測的常見問題就是如何做到生產環境的數據隔離:在生產環境進行寫壓測時,需要保證在壓測進行的同時不影響線上業務的正常運行,那么就需要考慮將壓測產生的數據與生產的真實數據隔離存儲,避免臟數據對線上業務產生影響。阿里云的全鏈路壓測平臺除了提供了影子表方案之外,還提供了影子庫的數據隔離方案。在生產環境實施全鏈路壓測的過程中,針對上文談到的兩種方案,又面臨著數據隔離方案的選擇問題,本文首先針對影子庫、影子表兩種方案進行介紹和對比,然后針對常見的場景,給出方案的選擇建議。
二、全鏈路壓測數據隔離方案的選擇
目前全鏈路壓測平臺提供了影子庫、影子表等解決方案。應該如何選擇適合自己的方案呢?本文首先針對兩種方案的原理進行闡述,然后從性能、穩定性、成本三個考量指標進行對比。
1.方案一:影子庫
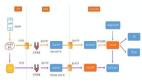
如圖 1 所示,針對影子庫方案,是在同一個實例上建立對應的影子庫。用戶服務掛載的全鏈路壓測探針獲取到流量標之后進行相應的旁路處理,如果是影子流量,那么會從影子連接池中獲取影子連接供業務側使用,從而將壓測流量產生的數據旁路到對應的影子庫中,以此達到數據和生產庫隔離的效果,從而避免了壓測流量產生的數據對生產庫造成污染。

圖 1:影子庫方案基本原理
2.方案二:影子表
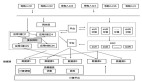
如圖 2 所示,類似影子庫方案,針對影子表方案,是在同一個實例上的同一個數據庫上建立對應的影子表。用戶服務掛載的全鏈路壓測探針獲取到流量標之后進行相應的旁路處理,如果是影子流量,那么,探針會針對本次的 DB 調用進行 SQL 解析和替換,從而將壓測流量產生的數據旁路到對應的影子表中。

圖 2:影子表方案基本原理
三、方案對比
本文主要從性能、穩定性、成本三個方面來闡述兩種方案的優缺點。

圖 3:方案對比
1.性能
機器規格:4c8g并發規格:需同時模擬正常和壓測流量兩種類型的流量,這里以 2:8 的比例進行劃分,以便于模擬業務流量低峰期進行生產環境全鏈路壓測。
- 正常流量:200 并發
- 壓測流量:800 并發
這里主要從服務所在的主機和所用的數據庫實例兩方面的監控去分析。其中,應用監控主要以 CPU、內存和平均 RT 三個指標分析。數據庫實例監控從連接數、QPS 兩個指標的維度進行分析。

?從以上兩種方案不同維度的指標對比可以看出,影子表方案對 CPU 的消耗略高,這和該方案的實現方式有關。
2.穩定性
談到穩定性,可以從數據源實例的連接數規格、容量規格、IOPS、網絡流量等方面進行分析。

?以上指標,這里以連接數為例進行說明,具體如下:針對影子庫方案。由于是在同一個實例上建立不同的數據庫,所以如果不考慮數據庫實例能夠達到最大連接數上限,理論上影子連接和正常連接時相互獨立的,執行時互不影響。針對影子表方案,由于是在同一個實例上的同一個數據庫上建立了不同的數據表,那么這里就要考慮業務側的連接池配置了,因為影子流量涉及到的 DB 操作和正常流量涉及到的 DB 操作,所用的數據庫連接,均來源于同一個連接池,所以如果壓測量級較大的時候,是比較容易出現連接池連接瓶頸的。
3.成本

根據表格中的內容,這里主要以冗余成本和數據遷移成本進行說明,具體如下:
- 冗余成本
針對影子庫方案,為了保證全鏈路壓測評估結果的精準度,我們需要在同一個實例上做全量的庫遷移操作,包括表結構和表數據,這會帶來一個比較明顯的問題,成本比較高,所有的基礎只讀表(此類型的表不會有寫操作)均要冗余一份,無法達到復用的目的,所以對于中大型企業來說,是難以接受的。針對影子表方案,是在同一個實例上的同一個數據庫上建立影子表。那么就可以復用生產庫中的基礎只讀表,只需對寫表進行建立影子表即可。影子表方案在一定程度上降低了數據冗余所帶來的成本消耗。
- 數據遷移成本?
從壓測的主流程來說,分為壓測前、壓測中、壓測后。其中,數據準備是處于壓測前這一階段的,壓測成功與否,和數據準備這一環節密切相關。數據遷移的過程需要將某張數據表所關聯的其他表字段同時做遷移,這一過程是比較復雜和耗費精力的。所以,具體選擇哪種方案,需要結合業務數據的復雜程度來評估。04?
總結
綜上,具體選擇以上兩種方案中的哪一種,其實僅靠一個指標判斷是不夠的,要結合以上多個指標以及具體的業務場景來進行綜合評估的。下面針對兩種典型的場景來說明應該如何選擇適合自己方案,以下意見僅供參考。
場景 1:在涉及到的讀表比例高于寫表、并且整庫遷移成本較高的情況下,推薦選擇影子表方案,在一定程度上可以減少復雜的數據遷移帶來的成本。場景 2:在涉及到的寫表比例高于讀表,同時生產庫實例容量較為充足的情況下,推薦選擇影子庫方案,在一定程度上降低了梳理、配置的成本。