使用OpenAI的Whisper 模型進行語音識別
語音識別是人工智能中的一個領域,它允許計算機理解人類語音并將其轉換為文本。該技術用于 Alexa 和各種聊天機器人應用程序等設備。而我們最常見的就是語音轉錄,語音轉錄可以語音轉換為文字記錄或字幕。

wav2vec2、Conformer 和 Hubert 等最先進模型的最新發展極大地推動了語音識別領域的發展。這些模型采用無需人工標記數據即可從原始音頻中學習的技術,從而使它們能夠有效地使用未標記語音的大型數據集。它們還被擴展為使用多達 1,000,000 小時的訓練數據,遠遠超過學術監督數據集中使用的傳統 1,000 小時,但是以監督方式跨多個數據集和領域預訓練的模型已被發現表現出更好的魯棒性和對持有數據集的泛化,所以執行語音識別等任務仍然需要微調,這限制了它們的全部潛力 。為了解決這個問題OpenAI 開發了 Whisper,一種利用弱監督方法的模型。
本文將解釋用于訓練的數據集的種類以及模型的訓練方法,以及如何使用Whisper
Whisper 模型介紹
使用數據集:
Whisper模型是在68萬小時標記音頻數據的數據集上訓練的,其中包括11.7萬小時96種不同語言的演講和12.5萬小時從”任意語言“到英語的翻譯數據。該模型利用了互聯網生成的文本,這些文本是由其他自動語音識別系統(ASR)生成而不是人類創建的。該數據集還包括一個在VoxLingua107上訓練的語言檢測器,這是從YouTube視頻中提取的短語音片段的集合,并根據視頻標題和描述的語言進行標記,并帶有額外的步驟來去除誤報。
模型:
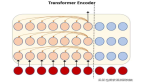
主要采用的結構是編碼器-解碼器結構。
重采樣:16000 Hz
特征提取方法:使用25毫秒的窗口和10毫秒的步幅計算80通道的log Mel譜圖表示。
特征歸一化:輸入在全局內縮放到-1到1之間,并且在預訓練數據集上具有近似為零的平均值。
編碼器/解碼器:該模型的編碼器和解碼器采用Transformers。
編碼器的過程:
編碼器首先使用一個包含兩個卷積層(濾波器寬度為3)的詞干處理輸入表示,使用GELU激活函數。
第二個卷積層的步幅為 2。
然后將正弦位置嵌入添加到詞干的輸出中,然后應用編碼器 Transformer 塊。
Transformers使用預激活殘差塊,編碼器的輸出使用歸一化層進行歸一化。
模型框圖:

解碼的過程:
在解碼器中,使用了學習位置嵌入和綁定輸入輸出標記表示。
編碼器和解碼器具有相同的寬度和數量的Transformers塊。
訓練
為了改進模型的縮放屬性,它在不同的輸入大小上進行了訓練。
通過 FP16、動態損失縮放,并采用數據并行來訓練模型。
使用AdamW和梯度范數裁剪,在對前 2048 次更新進行預熱后,線性學習率衰減為零。
使用 256 個批大小,并訓練模型進行 220次更新,這相當于對數據集進行兩到三次前向傳遞。
由于模型只訓練了幾個輪次,過擬合不是一個重要問題,并且沒有使用數據增強或正則化技術。這反而可以依靠大型數據集內的多樣性來促進泛化和魯棒性。
Whisper 在之前使用過的數據集上展示了良好的準確性,并且已經針對其他最先進的模型進行了測試。
優點:
- Whisper 已經在真實數據以及其他模型上使用的數據以及弱監督下進行了訓練。
- 模型的準確性針對人類聽眾進行了測試并評估其性能。
- 它能夠檢測清音區域并應用 NLP 技術在轉錄本中正確進行標點符號的輸入。
- 模型是可擴展的,允許從音頻信號中提取轉錄本,而無需將視頻分成塊或批次,從而降低了漏音的風險。
- 模型在各種數據集上取得了更高的準確率。
Whisper在不同數據集上的對比結果,相比wav2vec取得了目前最低的詞錯誤率

模型沒有在timit數據集上進行測試,所以為了檢查它的單詞錯誤率,我們將在這里演示如何使用Whisper來自行驗證timit數據集,也就是說使用Whisper來搭建我們自己的語音識別應用。
使用Whisper 模型進行語音識別
TIMIT 閱讀語音語料庫是語音數據的集合,它專門用于聲學語音研究以及自動語音識別系統的開發和評估。它包括來自美國英語八種主要方言的 630 位演講者的錄音,每人朗讀十個語音豐富的句子。語料庫包括時間對齊的拼字、語音和單詞轉錄以及每個語音的 16 位、16kHz 語音波形文件。該語料庫由麻省理工學院 (MIT)、SRI International (SRI) 和德州儀器 (TI) 共同開發。TIMIT 語料庫轉錄已經過手工驗證,并指定了測試和訓練子集,以平衡語音和方言覆蓋范圍。
安裝:
第一條命令將安裝whisper模型所需的所有依賴項。jiwer是用來下載文字錯誤率包的datasets是hugface提供的數據集包,可以下載timit數據集。
導入庫
加載timit數據集
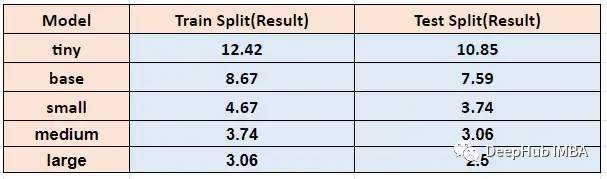
計算不同模型尺寸下的Word錯誤率
考慮到過濾英語數據和非英語數據的需求,我們這里選擇使用多語言模型,而不是專門為英語設計的模型。
但是TIMIT數據集是純英文的,所以我們要應用相同的語言檢測和識別過程。另外就是TIMIT數據集已經分割好訓練和驗證集,我們可以直接使用。
要使用Whisper,我們就要先了解不同模型的的參數,大小和速度。

加載模型
tiny可以替換為上面提到的模型名稱。
定義語言檢測器的函數
轉換語音到文本的函數
在不同模型大小下運行上面的函數,timit訓練和測試得到的單詞錯誤率如下:
從u2b上轉錄語音
與其他語音識別模型相比,Whisper 不僅能識別語音,還能解讀一個人語音中的標點語調,并插入適當的標點符號,我們下面使用u2b的視頻進行測試。
這里就需要一個包pytube,它可以輕松的幫助我們下載和提取音頻
獲得wav文件后,我們就可以應用上面的函數從中提取文本。
總結
本文的代碼在這里
https://drive.google.com/file/d/1FejhGseX_S1Ig_Y5nIPn1OcHN8DLFGIO/view
還有許多操作可以用Whisper完成,你可以根據本文的代碼自行嘗試。