三個用于時間序列數據整理的Pandas函數
本文將演示 3 個處理時間序列數據最常用的 pandas 操作

首先我們要導入需要的庫:
本文使用的數據集非常簡單。它只有 1 列,名為 VPact (mbar),表示氣候中的氣壓。該數據集的索引是日期時間類型:

我們也可以應用 pd.to_datetime(df.index) 來制作日期時間類型的索引。
本地化時區
- 本地化是什么意思?
本地化意味著將給定的時區更改為目標或所需的時區。這樣做不會改變數據集中的任何內容,只是日期和時間將顯示在所選擇的時區中。
- 為什么需要它?
如果你拿到的時間序列數據集是UTC格式的,而你的客戶要求你根據例如美洲時區來處理氣候數據。你就需要在將其提供給模型之前對其進行更改,因為如果您不這樣做模型將生成的結果將全部基于UTC。
- 如何修改
只需要更改數據集的索引部分
看看下面的結果:
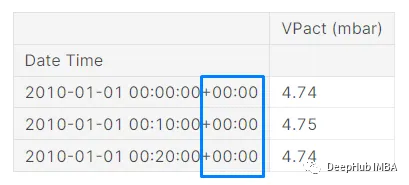
數據集的索引部分發生變化。日期和時間和以前一樣,但現在它在最后顯示+00:00。這意味著pandas現在將索引識別為UTC時區的時間實例。
現在我們可以專注于將UTC時區轉換為我們想要的時區。
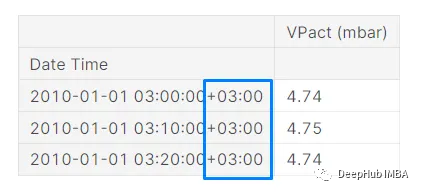
現在我們的時區已經改變到卡塔爾時區+03:00。
時間窗口重采樣
在本節中將研究如何根據時間間隔來預測時間序列數據。
- 這是什么意思?
這意味著收集一定范圍的目標值(在本例中為蒸氣壓讀數)并以某種方式概括它們,以便我們可以大致了解數據集中的趨勢。我們可以通過取平均值、最大值、最小值等來概括假設一次讀數的組。這里我們將5 個讀數分成一組,也就是我們所說的時間窗口
- 我們為什么需要它?
我將用一個例子來解釋這一點。假設客戶的問題是:
“我給你我的氣候傳感器讀數,每 10 分鐘獲取一次,我希望你告訴我每天對蒸氣壓的預測。也就是說,我想要對未來每一天的預測。”
現在你可能會說,這有什么大不了的?我們手上有一些讀數,每 10 分鐘讀取一次,我們只需要預測每天的氣壓。
在我們開始工作之前,讓我們先對器進行可視化:

- 如何重采樣
現在,我們重新采樣數據集,并使其成為匯總數據的單行/記錄。
這可能看起來很奇怪,但它返回的是一個對象而不是一個DF。如果我們試圖運行resampled_df.head(),它會拋出一個錯誤。這是因為雖然已經將它重新采樣為每行一天,但我們還沒有告訴它應該如何聚合一天窗口中出現的所有讀數。
聚合的操作包括:最大值、最小值、平均值、眾數?本文中我們取平均值。
我們還需要將其轉換為df。

時間索引從每分鐘讀數變為每天。我們再次可視化
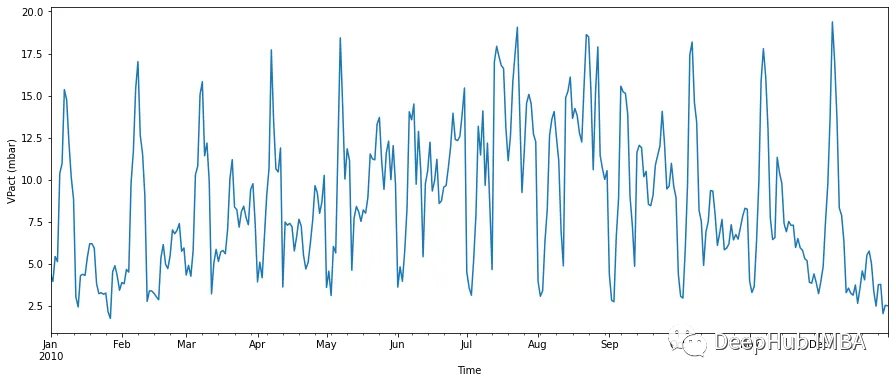
時間間隔小了很多,顯示的也是每天的數據
填補時間空白
本節中將介紹如何填充數據中的時間間隔。
- 這是什么意思?
時間序列數據由是一段連續的時間產生的數據組成。如果在數據集中有一些缺失的數據會就會在時間間隔上產生裂縫
- 為什么需要它?
如果給模型提供有空白的數據,模型會立即崩潰,這是我們不想看到的。
讓我們假設我們的數據集有一些空值序列。數據集看起來像這樣:

- 如何填充空白
我們嘗試各種各樣的值來填補這一空白。但是沒有一個是標準,因為所有的填充值都只是對實際值的廣義猜測。
在這個的例子中,我只展示其中一種填充方法,其他的方法都與其類似。這里將使用正向填充法。這個方法遍歷我數據集,并獲取它在遇到空白之前讀取的最后一個值,并用最后一個值填充整個空白。這個方法雖然簡單,但在很多情況下還是有用的。
我們還將它轉換成一個DF。
現在讓我們看看數據集。應該看一條完整的線,并且不包含空白的空間。

缺失的數據現在已經被補齊了。
總結
以上就是3個常用的時間數據處理的操作,希望對你有幫助。
本文源代碼
??https://www.kaggle.com/code/muhammadhammad02/wrangling-concepts-with-time-series-data??