我為什么要把退休前的這段時間都用在和運維知識自動化系統死磕上
?我的團隊做系統優化是從2003年開始的。應HP SERVICE的邀請,2003年我加入了他們的海爾系統優化組,負責Oracle數據庫的優化工作。這是我第一次參加大型系統的優化工作,甚至那時候我還不知道一個大型售后服務系統的優化該從何處入手。我是帶著李維斯的一本書出發去青島參加這個優化項目的,通過這個項目,我對Oracle數據庫的優化有了初步的認識。后來我又幫助HP完成了對華為SCM系統所采用的CAF平臺的性能評估,并對決策者建議及時中止這個項目,避免更大的資金浪費,因為這個項目已經無法優化了。后來HP采納了我的建議,關閉了基于CAF平臺的項目,華為也重新選擇了Oracle EBS作為SCM系統和ERP系統的基礎。從那以后,我們的團隊規模越來越大,做的優化項目也越來越多,也鍛煉出了一批做系統優化的專家。
2011年,我們開始幫助國家電網做系統優化,剛開始的幾個項目在專家的帶隊下,效果都特別好。客戶希望我們擴大優化范圍,制訂了一個需要近百名DBA的大型優化項目。我們從很多合作伙伴處招募了數十名DBA共同參與這個項目,為了確保項目的質量,我們對整個團隊進行了多次集中培訓。不過最后這個項目做下來效果很不理想,最主要的原因就是DBA的能力參差不齊,大多數沒有參加過大型優化項目。從那個項目開始,我也在思考傳統的依靠人和專家的運維模式存在的問題,希望找到一條道路,能夠讓專家的經驗發揮更大的作用。這是我開發D-SMART,一個運維知識自動化系統的初衷。要想構建一個知識自動化系統,必須提高運中的數字化程度。不過傳統行業IT運維的數字化程度很低。其主要原因有幾個方面。
資源有限:很多企業可能沒有足夠的資源去投入研發和實施智能化運維系統,或者可能認為將資源投入其他方面更有回報。
文化因素:一些企業可能更愿意依靠人工經驗而不是自動化系統,可能是因為他們缺乏對自動化系統的信任,或者他們可能認為在緊急情況下專家的判斷比機器更可靠。
技術限制:一些企業可能缺乏必要的技術基礎設施來支持智能化運維系統,這可能需要較高的成本投入來升級設備和系統。
意識不足:一些企業可能沒有意識到數字化運維的潛在優勢,或者可能沒有足夠的知識和了解數字化運維的實施方法。
雖然傳統行業在運維數字化上存在各種認知的不足,但隨著技術的發展和數字化的日益重要,智能化運維將成為未來信息系統運維的一個趨勢,也是一個必然的方向。
反思我們這些年做系統優化與運維的工作經歷,經驗不足的技術人員是導致優化工作效果不佳的重要因素。優化工作需要專業知識和技能,而不是僅僅依靠經驗。可能需要更加系統化的培訓來確保所有參與優化工作的人員具備必要的技能和知識。此外,優化工作的效果也受到多個因素的影響,如系統設計,數據質量和優化工作的過程等。
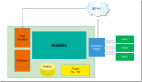
隨著技術的不斷發展,現在已經有許多智能化的算法與方法可供使用,可以大大提高運維效率和減少人為錯誤。通過運維知識自動化工具可以提供智能化分析和自動化操作,以幫助DBA更好地管理和優化系統。如果企業有足夠的資源,可以考慮引入這些工具和系統來改善運維效率。“運維知識自動化系統”結合了大數據分析、人工智能等技術,以及專家經驗和工作積累,構建了一個全面的運維知識體系,可以幫助提高運維工作的效率和質量。通過監控指標體系、健康模型、運維知識圖譜、異常檢測算法等技術,“運維知識自動化系統”可以自動化地分析和解決系統性能問題,同時還能提供智能化的優化建議和決策支持,為企業的運維工作提供了強有力的支持。
實際上D-SMART系統開發的最重要的目的是對我們這個團隊這二十多年在IT運維與系統優化上的經驗的總結,讓團隊中的專家把這些年積累的經驗變成可自動化執行的數字化知識庫。并通過不斷的迭代知識庫,讓運維知識不斷的能夠在平臺中沉淀與積累,從而不斷提升自動化分析的能力。
這個系統的研發不僅僅依賴于研發團隊,知識工具的研發完全由DBA完成,而沒有借助于普通的運維人員。這是因為普通的研發人員并不了解IT運維,不了解數據庫,不了解性能優化。只有做過運維工作的DBA才能夠更加準確的把專家的思路變成自動化的工具。
D-SMART系統的起點是指標體系,我認為指標是專家經驗的一部分,而且是十分重要的一部分,專家認知后的指標才是可以完全解讀的指標。而目前很多數據庫監控軟件提供的很多指標,運維人員無法正確解讀,哪怕這些指標出現了異常,可能也無法被發現,或者說發現了指標異常也無法感知到系統哪個地方出現了問題。而專家梳理出來的指標數據都是單一可被專家解讀的,因此每個指標都會被專家進行標注,打上特定的標簽。
D-SMART的第二步是完成指標的準確采集,準確的采集到每個指標的數據對于智能化運維系統來說十分關鍵。要確保每個數據都能夠準確的反映出數據庫的真實狀態十分關鍵。很多數據被采集回來后,需要經過加工才能變成可被使用的指標,這些加工算法里也體現了專家的經驗。通過這個步驟,D-SMART系統在不斷的獲取數據庫運行狀態的數字化模型。
第三步是對采集回來的指標、日志數據進行自動化的建模分析。我們通過健康模型判斷數據庫的運行狀態是否正常,是否存在風險;通過性能模型了解數據庫的總體性能狀態;通過負載模型了解數據庫當前的負載情況;通過故障模型發現數據庫可能存在的隱患,并及時報警。
第四步是利用這些被采集回來的數據自動完成各種巡檢工作。比如日檢,每天半夜系統會自動對前一天采集的數據做分析,發現其中的風險與隱患,并生成日檢報告。每個月或者每個星期,可以定制任務對最近采集的數據進行自動化分析,生成巡檢報告。這種巡檢能夠分析全面的數據,比傳統的靠人工采集數據,人工進行分析的方式擁有更為豐富的數據。通過自動化分析的算法也更加高效。
利用這些數據,還可以做很多有價值的分析工作,比如容量預測、性能優化、專項審計等。同時利用標準化的指標體系,我們還可以構建一線運維與二三線運維的數字化溝通,通過完善的指標集,可以盡可能全面的為三線運維提供數據庫運行的全景視圖,真正做到不用到現場,專家可以盡知天下事。
前陣子80多歲的母親一定要給我過個生日,這些年在外面跑,已經有十多年沒有過生日了。插蠟燭的時候才發現,過完生日已經54歲,離退休已經時日無多了。我想在現在還能做點事情的時候,盡可能的能夠把這些年積累的經驗都數字化了,能夠留下來,這樣也就沒有遺憾了。