













網(wǎng)絡(luò)性能總不好?專家?guī)湍銇怼翱纯础薄獣N騰AI黑科技 | 網(wǎng)絡(luò)調(diào)優(yōu)專家AOE,性能效率雙提升
隨著深度學(xué)習(xí)模型復(fù)雜度和數(shù)據(jù)集規(guī)模的增大,計算效率的提升成為不可忽視的問題。然而,算法網(wǎng)絡(luò)的多樣性、輸入數(shù)據(jù)的不確定性以及硬件之間的差異性,使得網(wǎng)絡(luò)調(diào)優(yōu)耗費巨大成本,即使是經(jīng)驗豐富的專家,也需要耗費數(shù)天的時間。
CANN(Compute Architecture for Neural Networks)是華為針對AI場景推出的異構(gòu)計算架構(gòu),對上支持多種AI框架,對下服務(wù)AI處理器與編程,發(fā)揮承上啟下的關(guān)鍵作用,是昇騰AI基礎(chǔ)軟硬件平臺的核心。為了在提升網(wǎng)絡(luò)性能的同時降低巨大的人工調(diào)優(yōu)成本,CANN推出了自動化網(wǎng)絡(luò)調(diào)優(yōu)工具AOE(Ascend Optimization Engine),通過構(gòu)建包含自動調(diào)優(yōu)策略生成、編譯、運行環(huán)境驗證的閉環(huán)反饋機制,不斷迭代,最終得到最優(yōu)調(diào)優(yōu)策略,從而在AI硬件上獲得最佳網(wǎng)絡(luò)性能。以ResNet50推理網(wǎng)絡(luò)為例,經(jīng)AOE調(diào)優(yōu)后的網(wǎng)絡(luò)性能提升100%以上,調(diào)優(yōu)耗時不到30分鐘。
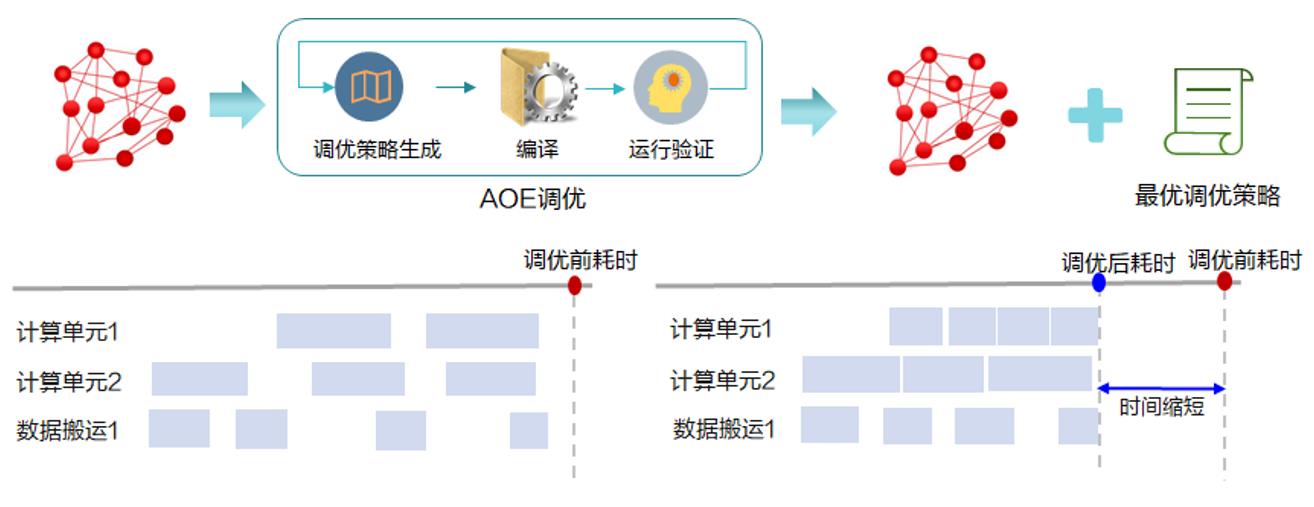
針對網(wǎng)絡(luò)模型,AOE分別提供了算子調(diào)優(yōu)、子圖調(diào)優(yōu)與梯度調(diào)優(yōu)的功能。其中算子調(diào)優(yōu),主要針對算子的調(diào)度(Schedule)進行優(yōu)化,從而使得昇騰AI處理器的多級Buffer與計算單元形成高效的流水并發(fā)作業(yè)流,充分釋放硬件算力;子圖調(diào)優(yōu),通過智能化的數(shù)據(jù)切分策略提升緩存利用率,從而大幅提升計算效率;梯度調(diào)優(yōu)主要應(yīng)用于集群訓(xùn)練場景下,通過自動化尋找最優(yōu)梯度切分策略、降低通信拖尾時間,從而提升集群訓(xùn)練性能。同時,AOE能夠支持多種主流開源框架,在訓(xùn)練和推理場景下全方位滿足不同開發(fā)者的網(wǎng)絡(luò)性能調(diào)優(yōu)訴求。

算子調(diào)優(yōu),提升計算節(jié)點執(zhí)行效率
1. 強化學(xué)習(xí),生成Vector算子最優(yōu)調(diào)度策略
AI處理器在計算過程中需要精心排布才能充分發(fā)揮算力,計算組件間的流水排布很大一部分由調(diào)度來承載,一個很小的調(diào)度操作映射到硬件行為上都可能產(chǎn)生巨大的差異。想要提升網(wǎng)絡(luò)性能,勢必需要為給定網(wǎng)絡(luò)在指定設(shè)備上開發(fā)一套專屬的調(diào)度邏輯。
網(wǎng)絡(luò)的組成單元是算子,為算子執(zhí)行尋找最優(yōu)的調(diào)度策略是提升網(wǎng)絡(luò)性能的關(guān)鍵。昇騰AI處理器的核心計算單元是AI Core,針對運行在AI Core上的算子,可以分為Vector與Cube兩類,其中Vector算子主要負責執(zhí)行向量運算,Cube算子主要負責執(zhí)行矩陣運算。
針對Vector算子,CANN采用了RL強化學(xué)習(xí)(Reinforcement Learning)搜索框架,將算子調(diào)度過程抽象成了基于MCTS蒙特卡洛樹搜索(Monte Carlo Tree Search)的決策鏈,并模擬人工進行決策,再通過和環(huán)境不斷交互得到性能數(shù)據(jù),作為反饋值指導(dǎo)下一步?jīng)Q策。通過此方法一步步改善自身行為,最終獲取算子執(zhí)行對應(yīng)的完整最優(yōu)調(diào)度策略。
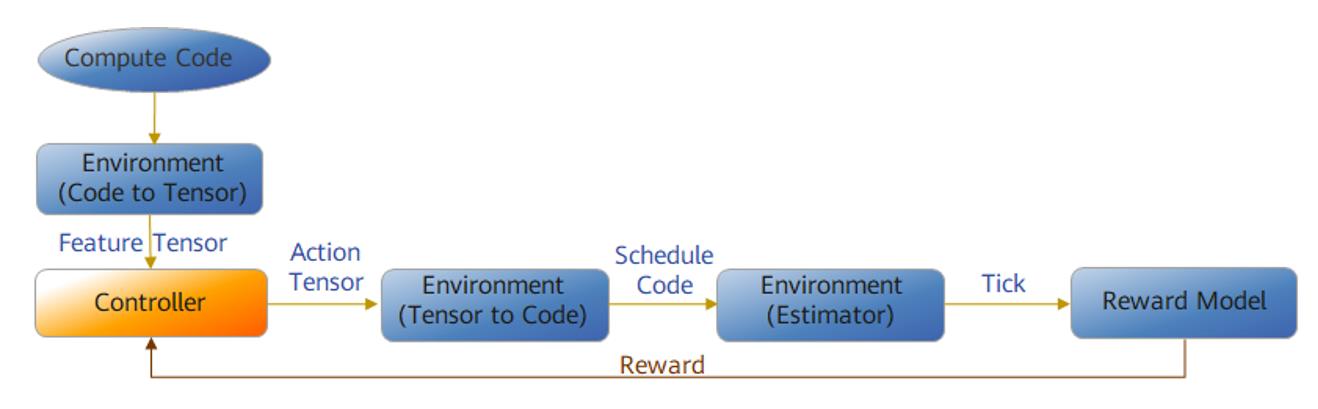
經(jīng)過AOE調(diào)優(yōu)后的Vector算子,平均性能較調(diào)優(yōu)前可提升10%以上,平均調(diào)優(yōu)時間僅需200s,效率與性能都有較大提升。
2. 遺傳算法,提高Cube算子搜索效率
我們知道在深度學(xué)習(xí)網(wǎng)絡(luò)中包含了大量的矩陣乘計算,而這部分計算在昇騰AI處理器中均通過Cube算力來承擔,因此Cube算子作為重型算子,在網(wǎng)絡(luò)中的影響權(quán)重較大,所以針對Cube算子的性能提升會給整個網(wǎng)絡(luò)的性能帶來較大的收益。
通過強化學(xué)習(xí)模式的搜索,我們已經(jīng)可以做到解放人力進行Vector類型的算子優(yōu)化,因為Vector算子的計算Buffer單一,調(diào)度算法可以基于各種Schedule原語為算子構(gòu)建完整的調(diào)度策略。而Cube算子涉及多塊片上Buffer之間的數(shù)據(jù)交互,如果按照和Vector算子相同的調(diào)優(yōu)方式,可能最終會因為搜索空間過大導(dǎo)致搜索效率低下和搜索策略不佳的結(jié)果。
針對Cube算子,AOE以Schedule模板為基礎(chǔ),利用GA遺傳算法(Genetic Algorithm),通過選擇、交叉、變異等方式對影響最大的Schedule原語參數(shù)進行多輪調(diào)優(yōu),從而得到候選Tiling集,再根據(jù)在真實環(huán)境編譯執(zhí)行的性能反饋數(shù)據(jù)將候選策略進行排序,得到最優(yōu)策略。
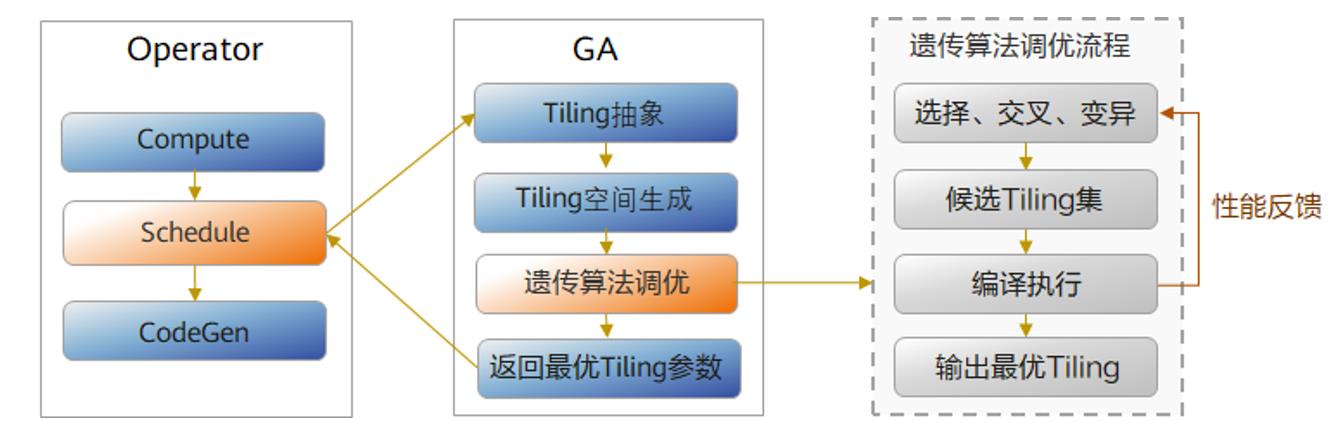
以卷積算子為例,若人工調(diào)優(yōu),需要消耗一個算子優(yōu)化專家兩天的時間;若使用AOE智能調(diào)優(yōu),平均僅需3分鐘即可達到相同甚至更優(yōu)的性能優(yōu)化效果,極大的節(jié)省了人力成本!
子圖調(diào)優(yōu),獲得更智能的數(shù)據(jù)切分
算子調(diào)優(yōu)已經(jīng)使得網(wǎng)絡(luò)性能有了可觀的提升,但AOE并沒有止步于此。AOE在更宏觀的粒度上加入了子圖調(diào)優(yōu),從而實現(xiàn)更智能的數(shù)據(jù)切分。
深度學(xué)習(xí)模型的計算往往有較大的數(shù)據(jù)吞吐,數(shù)據(jù)讀寫往往成為網(wǎng)絡(luò)性能的瓶頸,因此對于高速緩存利用率的提升成為計算效率優(yōu)化的關(guān)鍵手段。
昇騰AI處理器中包含了高速緩存以降低外部訪存的帶寬壓力,然而由于特征圖(Feature Map)和模型參數(shù)的數(shù)據(jù)量巨大,會導(dǎo)致算子計算過程中的Cache命中率較低,影響整網(wǎng)計算效率。為了更好的提升高速緩存Cache命中率,AOE引入了子圖調(diào)優(yōu)的概念。
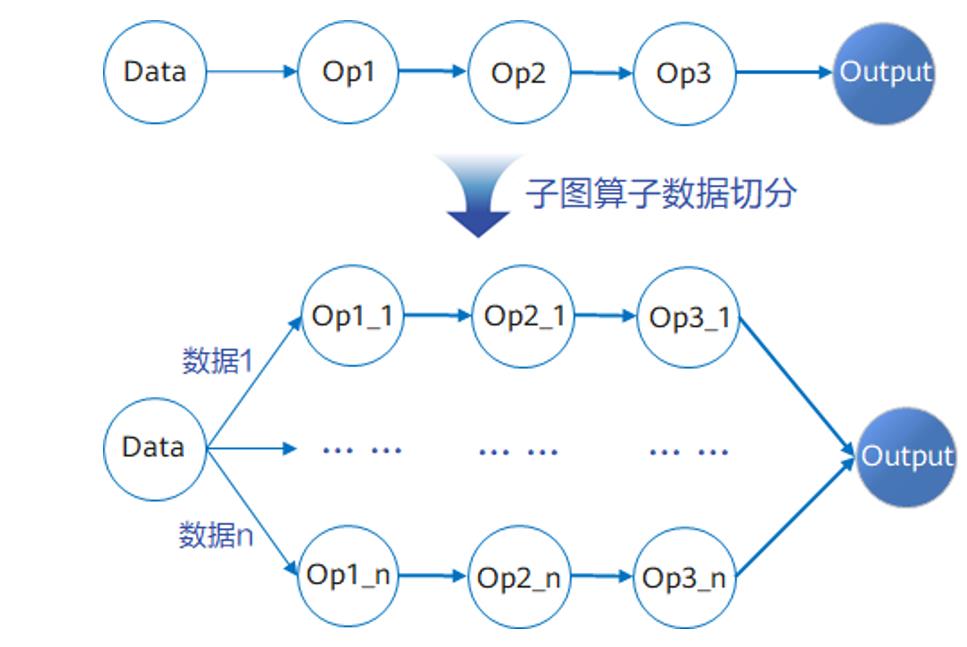
子圖調(diào)優(yōu),基于算子切分數(shù)學(xué)等價原則,根據(jù)硬件Cache大小、算子shape等信息,將網(wǎng)絡(luò)模型中的算子切分成多個算子,然后編排切分后算子的執(zhí)行順序,通過獲取最佳的性能反饋,確定計算圖切分策略和執(zhí)行順序。這樣,就可以將一次性的數(shù)據(jù)流計算分解成多次進行執(zhí)行,在分解后的數(shù)據(jù)流分支上,數(shù)據(jù)大小相比之前成倍遞減,進而實現(xiàn)了Cache命中率的顯著提升。
最終,在算子調(diào)優(yōu)和子圖調(diào)優(yōu)的共同作用下,使用AOE進行性能調(diào)優(yōu)后,主流推理網(wǎng)絡(luò)的平均性能提升30%以上。以ResNet50推理網(wǎng)絡(luò)為例,性能較調(diào)優(yōu)前提升超過100%,整網(wǎng)調(diào)優(yōu)耗時30分鐘以內(nèi)。
梯度調(diào)優(yōu),提升集群訓(xùn)練性能
大規(guī)模集群訓(xùn)練場景中,存在著計算節(jié)點多、梯度聚合過程復(fù)雜、通信開銷大的痛點。梯度聚合過程和計算過程怎么更好的一定程度上相互掩蓋,讓整個過程保證較好的線性度,也是性能提升的關(guān)鍵問題。為此,AOE引入了梯度調(diào)優(yōu)的功能,通過智能梯度切分算法,自動搜索出最優(yōu)梯度參數(shù)切分方式,為梯度傳輸選擇合適的通信時機和通信量,最大限度讓計算和通信并行,從而將通信拖尾時間降至最低,促使集群訓(xùn)練達到最優(yōu)性能。
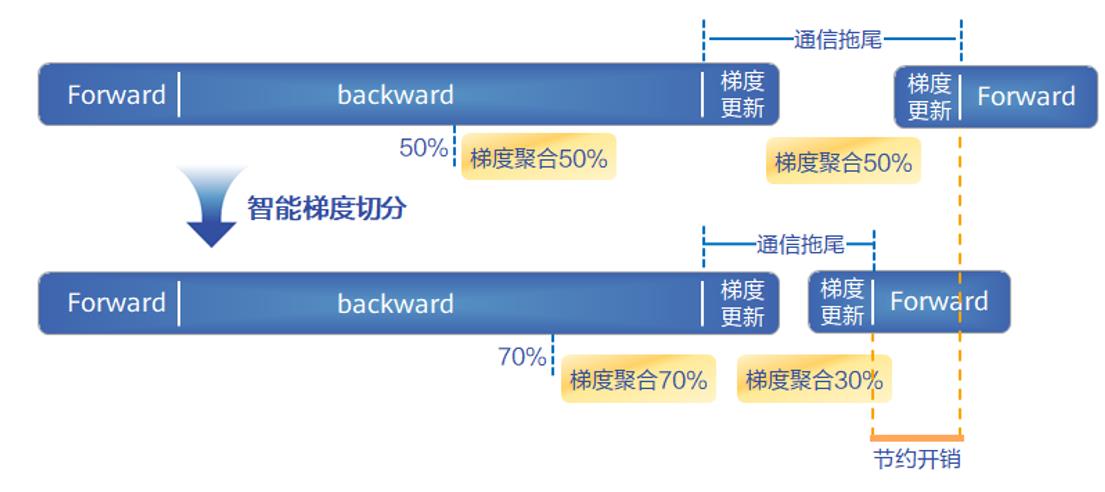
相對人工調(diào)整梯度聚合數(shù)據(jù)量,自動梯度調(diào)優(yōu)可以將梯度聚合數(shù)據(jù)量調(diào)參時間從數(shù)人天縮短至數(shù)十分鐘,一舉獲得最優(yōu)聚合策略,降低人工調(diào)參的不確定性。AOE通過調(diào)優(yōu)知識庫記錄模型調(diào)優(yōu)經(jīng)驗,使得模型聚合策略能夠動態(tài)適應(yīng)不同集群規(guī)模。
經(jīng)過AOE調(diào)優(yōu)后,主流訓(xùn)練網(wǎng)絡(luò)在昇騰AI處理器上執(zhí)行性能較調(diào)優(yōu)前平均提升了20%以上。以ResNet50訓(xùn)練網(wǎng)絡(luò)為例,性能較調(diào)優(yōu)前提升了23%,整網(wǎng)調(diào)優(yōu)耗時2H以內(nèi)。
寫在最后
昇騰異構(gòu)計算架構(gòu)CANN始終致力于提供“開放易用、極致性能”的AI開發(fā)體驗,不斷降低AI開發(fā)的門檻與成本。CANN提供的昇騰調(diào)優(yōu)引擎AOE克服了傳統(tǒng)調(diào)優(yōu)方法耗時長、泛化性差、維護成本高等影響開發(fā)效率和可用性的弊端,為AI開發(fā)者提供了更智能化的性能優(yōu)化手段。
以夢為馬,未來可期,相信通過CANN的持續(xù)創(chuàng)新與不斷演進,定將進一步釋放AI硬件的澎湃算力,加速AI應(yīng)用場景落地,共建智慧世界。













