Spring為什么使用三級緩存而不是兩級解決循環依賴問題?
?首先明確一點,Spring如果使用二級緩存也是完全能夠解決代理bean的循環依賴問題的。那Spring為什么要使用三級緩存的設計呢?在回答這個問題前我們先明確一些概念。
Spring Bean相關的知識
Spring Bean 的創建過程
- 掃描xml或者注解獲取BeanDefinition;
- 實例化bean:通過createBeanInstance方法創建bean的原始對象BeanWrapper;
- 注入bean的依賴:利用populateBean方法(本質是反射)注入bean的依賴屬性;
- 初始化bean:調用initializeBean方法最終形成完整的bean對象;
Spring Bean 的三級緩存定義
三級緩存的查找策略是,先從一級緩存獲取,若獲取不到就從二級緩存,仍然獲取不到則從三級緩存獲取,若還是獲取不到則通過bean對應的BeanDefinition信息實例化。
Tips:二、三級緩存會在DI的過程中被刪除,最終所有的Bean都會變成完整的bean并存入一級緩存中。
- 三級緩存singletonFactories:在注入bean的依賴前存入,所有bean都會存入,循環依賴時會使用,代碼如下:
- 二級緩存earlySingletonObjects:存放實例化的對象(可能是原始對象也可能是代理對象),代碼如下:
- 一級緩存singletonObjects:用于存放完整的bean,代碼如下:
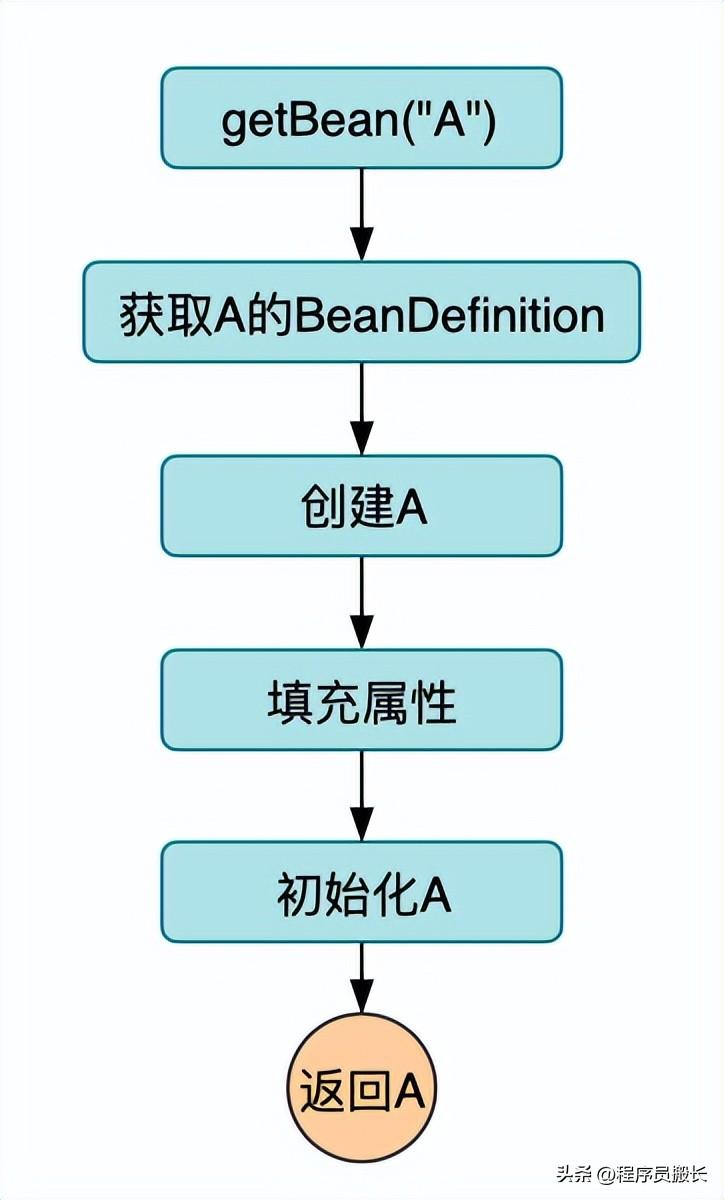
什么是循環依賴?
循環依賴是指:Spring在初始化A的時候需要注入B,而初始化B的時候需要注入A,在Spring啟動完成后這倆個對象都必須是完整的bean。
循環依賴的場景有三種:
- 構造器循環依賴:Spring無法解決,因為bean創建的第一步就是通過構造器實例化,也就是說解決循環依賴的前提就是對象可以實例化并緩存,與Java死鎖很像;
- prototype范圍的依賴:該循環依賴Spring不可解決,prototype作用域的bean Spring不緩存,因此在依賴注入時無法獲取到依賴的bean;
- setter循環依賴:該循環依賴是Spring推薦的方式,我們接下來就重點講解這種方式;
一個簡單setter循環依賴的代碼示例如下:
Spring 是如何利用多級緩存解決循環依賴的
我們先拋開Spring的實現來做一次解決循環依賴的設計推演。
在沒有緩存的情況下循環依賴的場景
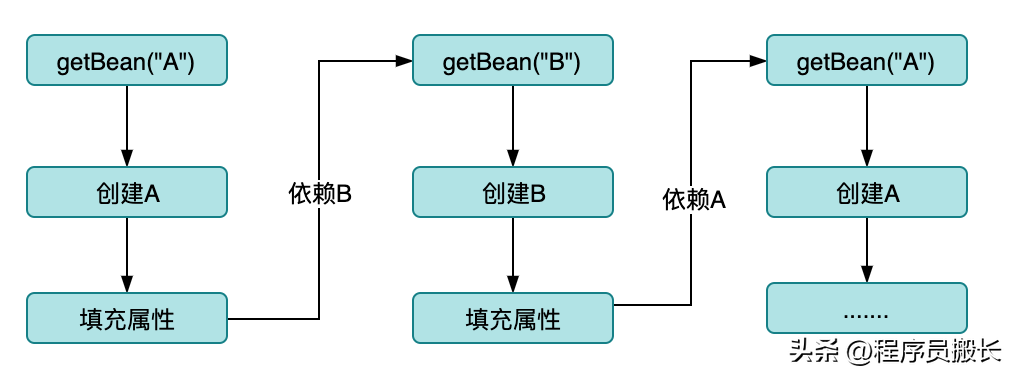
如圖可以直接觀察到,當沒有緩存時,當發生循環依賴時直接死循環了,最終的結局就是StackOverflow或者OOM。
增加一層緩存
為了解決上面循環依賴的問題,我們加入一層緩存,緩存可以使用Map結構,key為beanName,value為對象實例。如下如:
從上圖可以直觀的看出,循環依賴的問題已經得到了完美解決,但是又有了一個新問題,這個緩存中的bean可能有已經創建完成的、正在創建中還沒有注入依賴的,它們都摻雜在一起,我們如何保證Map里面的所有對象是完整的呢?一層緩存很顯然不符合設計規范,也缺乏安全性與擴展性。
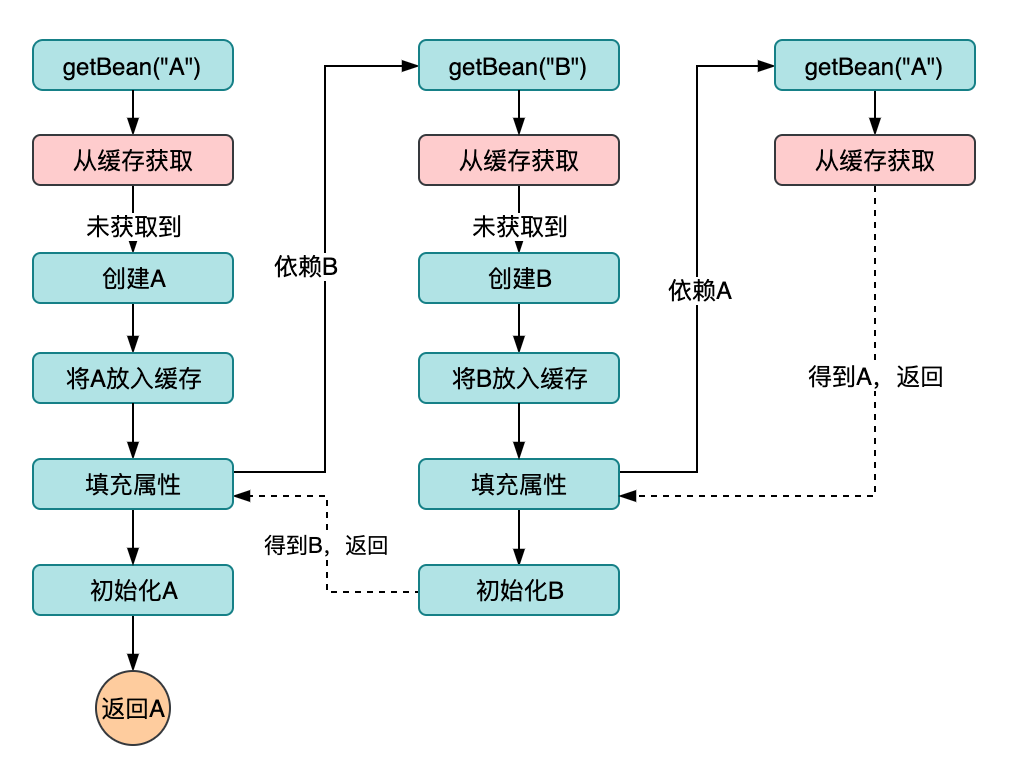
二級緩存設計
我們希望的是,明確已經構建完成的的Bean被放入到一個緩存中,創建中的bean在另外一個緩存中,于是就有了下面的結構:
與一級緩存架構設計的區別在于:
- 新增了二級緩存,用于存放剛實例化的bean;
- 當bean初始化完成后會放入一級緩存,同時將bean從二級緩存中的刪除(不需要一式兩份,保留一份最終完整的Bean即可)
從目前看這個設計完美解決了bean的完整性問題,但是在實際生產中問題總是疊著問題,沒有完美的架構設計。我們都知道Java中有代理,而且代理的應用非常廣泛,包括在Spring中就有非常多的代理,那問題就來了,我們如何區分代理對象與普通對象?如果循環依賴中存在代理對象的循環依賴會發生什么呢?
代理對象的循環依賴
在現實開發過程中,我們往往會產生很多的代理對象,當存在代理對象加入到循環依賴流程會是什么樣的場景,我們來推演一下,我們仍然使用二級緩存的設計來做推演。
如果我們在bean初始化完成之后再創建代理對象,整個流程是這樣的:
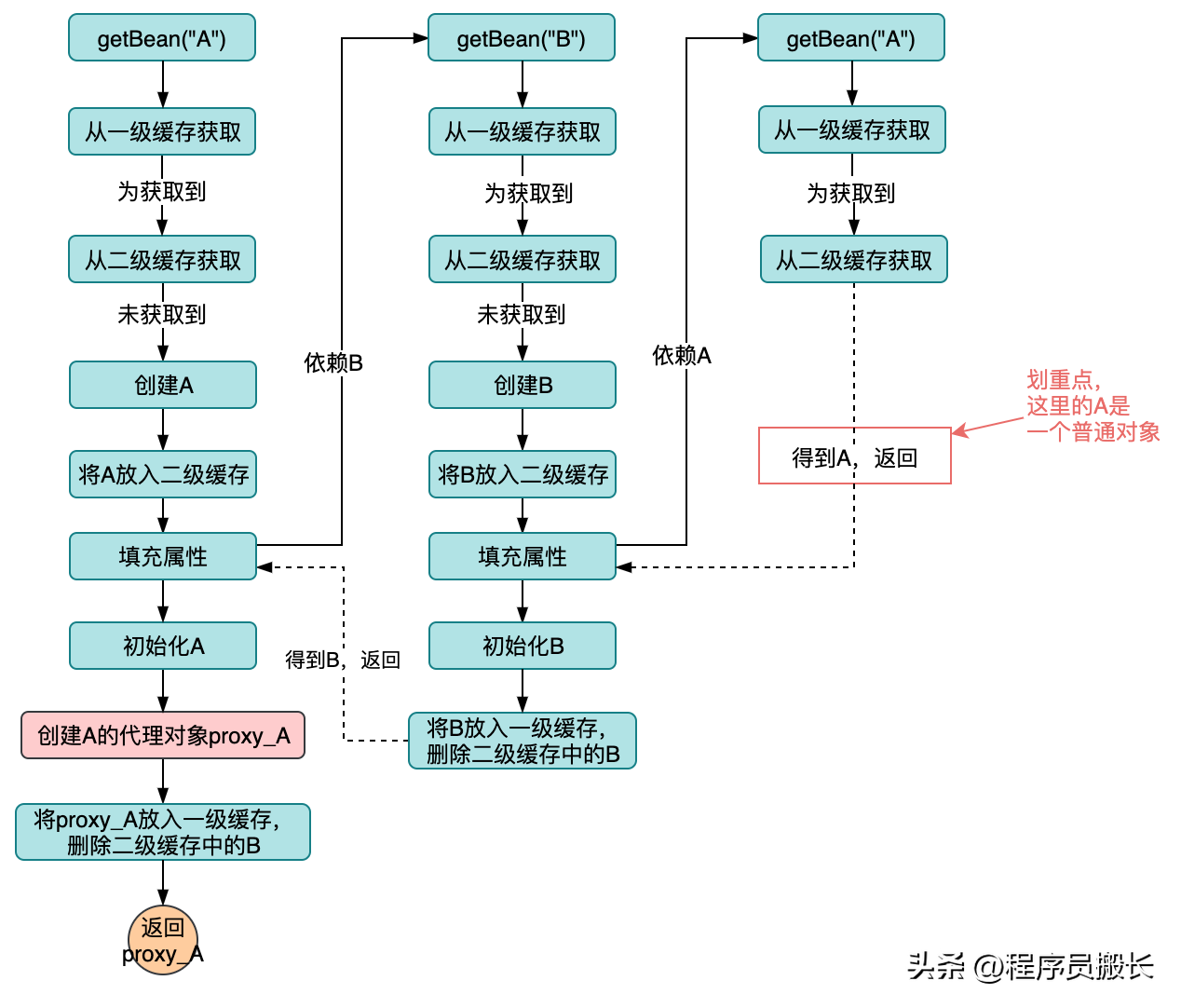
從上圖可以非常直觀的看出,最終在一級緩存中的對象A是一個proxy_A,但是對象B依賴的對象A卻是一個普通A!很明顯現有的設計不能夠滿足代理對象的循環依賴問題。
如何解決這個問題呢?我們還是在上一個設計上做修改:
- 方案一:在獲取到A時立即創建代理,如下圖(紅色部分)所示:
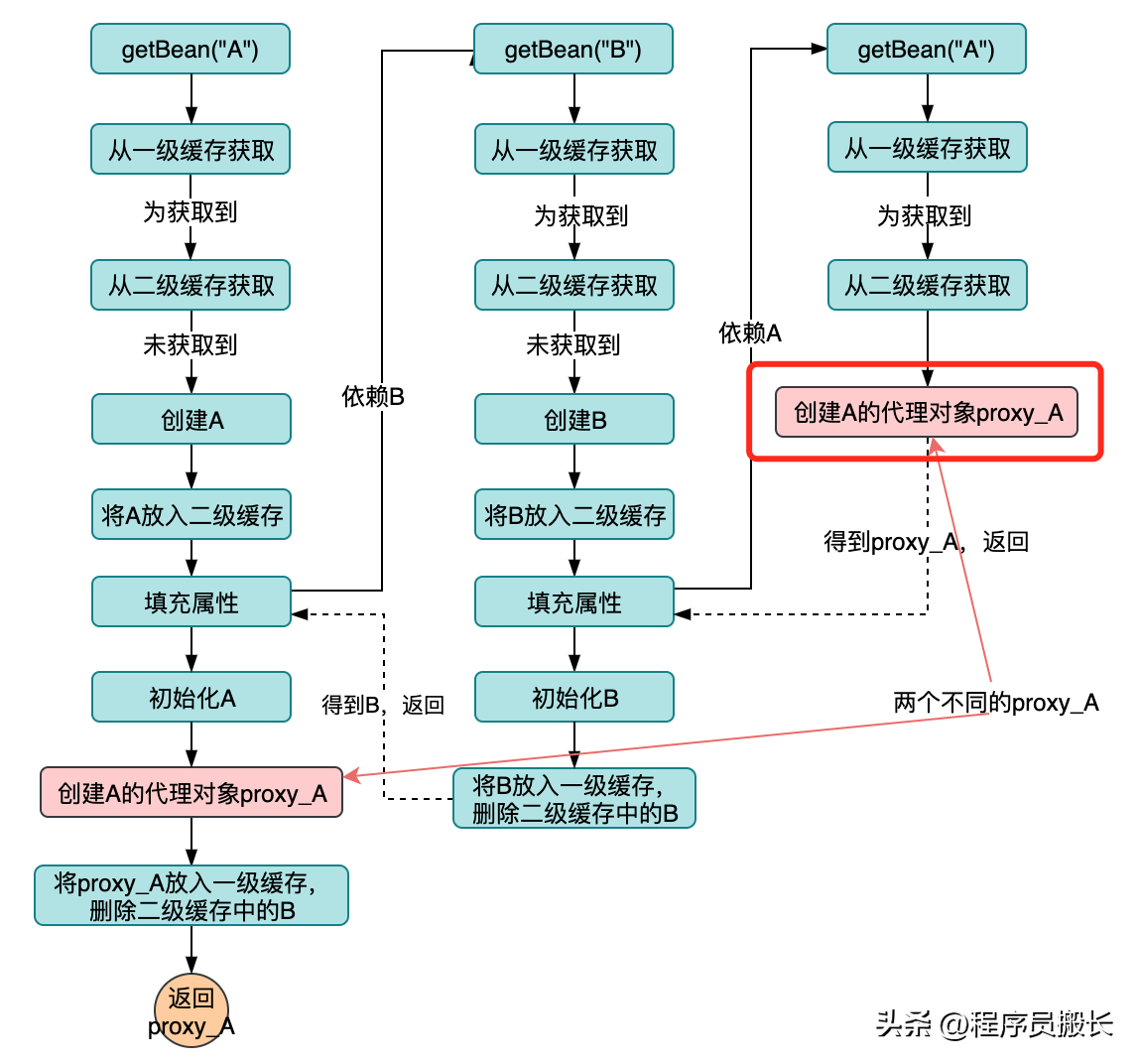
這個方案看起來解決了B對象依賴不到A的proxy對象問題,但是又引起了一個致命的問題,在A初始化完成之后還會創建一次代理對象,那么就創建了兩次代理對象,他們是完全不一樣的,這個代理對象不是單例的了!
- 方案二:在方案一的基礎上,我們是不是可以將創建完的proxy_A對象加入到二級緩存中,直接覆蓋掉普通A(代理對象會持有普通對象A的引用,所以可以覆蓋):這個方案看上去沒有問題,但是從設計角度講,這不符合設計規范,而且覆蓋后的A是個代理對象,在后續的操作中,如果再從二級緩存中獲取A,這時候就不知道到底獲取到的是普通A還是proxy_A了,這無形增加了判斷識別的復雜度。
- 方案三:在首次實例化A的時候就直接創建A的代理對象,并放入二級緩存中:這個方案與方案二有相同的問題,這里不在贅述。
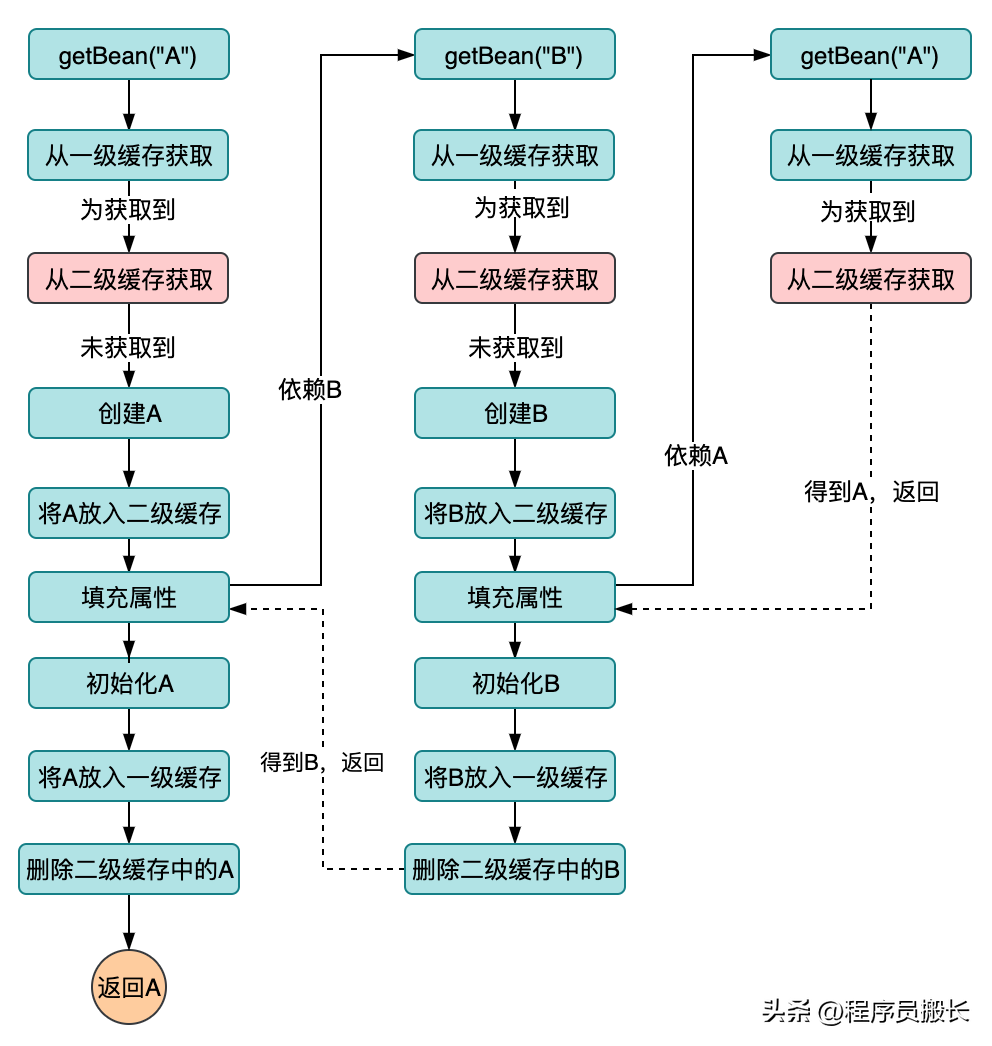
解決代理對象的循環依賴之終極方案
解決代理對象的循環依賴之終極方案-三級緩存!
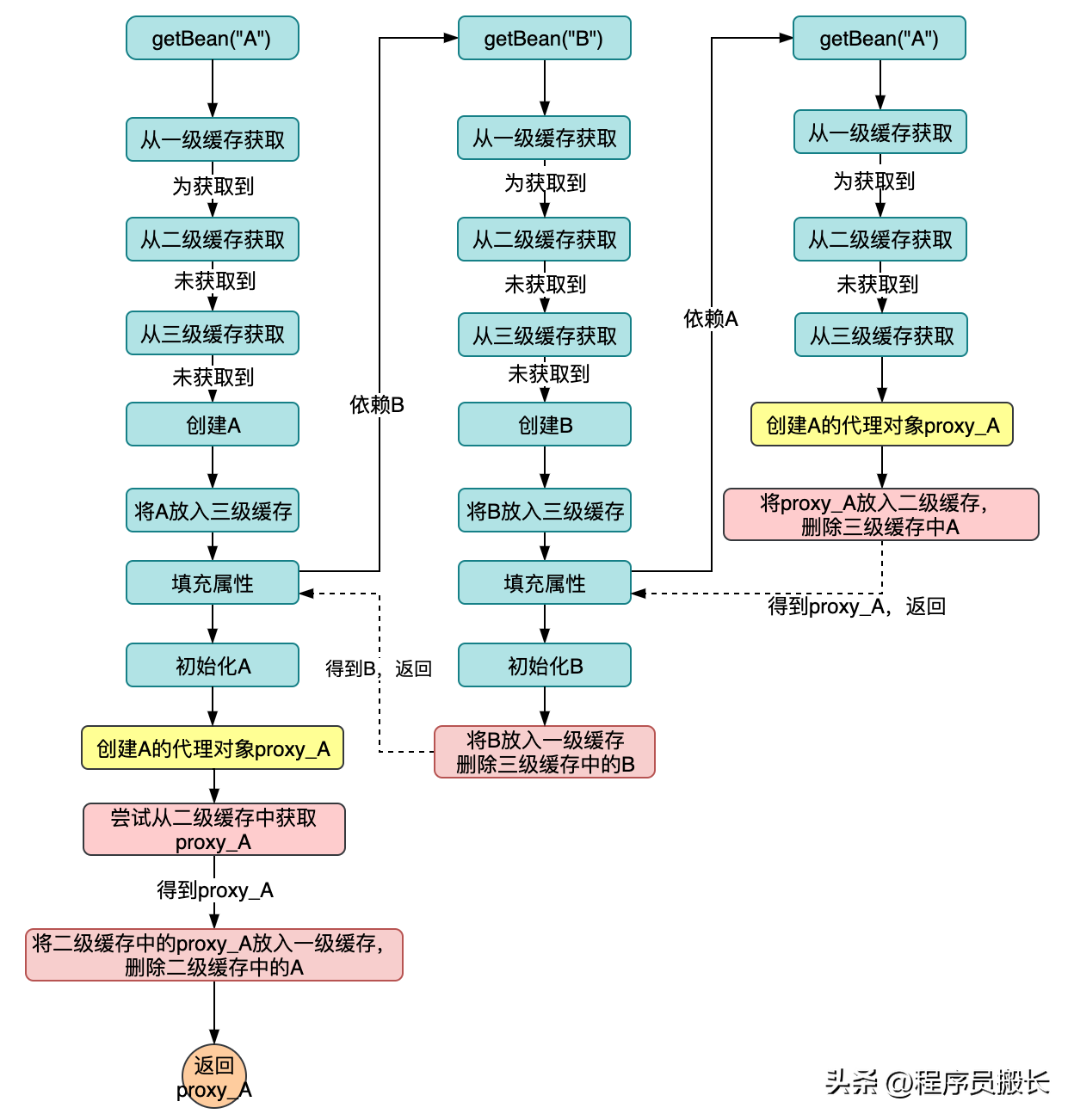
與二級緩存設計最大的不同點在于:
- 在獲取到A時創建proxy_A,同時將其加入到二級緩存中,并返回給B,這樣B就依賴了proxy_A;
- 在A初始化過程中會創建代理對象,這時候會做一個檢查,也就是會去查詢二級緩存,看有沒有proxy_A的存在,如果有說明proxy_A已經創建,我們會選擇二級緩存中的proxy_A存入一級緩存并返回(因為二級緩存中的proxy_A已經被B依賴);
其它流程不在贅述,該設計中最重要的幾個地方在Spring中的實現是更加細致的,我在流程途中只是簡單概括,下面特殊說明一下幾個點。
Spring Bean初始化會產生代理對象的場景
在上述流程中,標記位黃色的部分就是兩個代理對象的創建的地方,在Spring中就是這兩個后置處理器調用的地方,它們分別是:
- 在調用getEarlyBeanReference時如果實現了BeanPostProcessor則會創建代理對象;
- 另一個地方是在執行Bean初始化initializeBean時執行BeanPostProcessor會創建代理對象;
在Spring中的第三級緩存有更加靈活設計
在Spring中,第三級緩存不僅僅是存入了實例化的對象,而是存入了一個匿名類ObjectFactory,getEarlyBeanReference函數的實現中會調用BeanPostProcessor執行用戶自定義的邏輯。具體代碼如下:
若初始化階段的后置處理器對對象做了代理,Spring是如何處理的?
在Spring中若在initializeBean階段的后置處理器對對象做了代理,那么Spring會對做依賴檢查,具體代碼如下:
為什么Spring采用三級緩存設計?
我們再回到最初的問題上,其實上述整個設計推演過程就已經很好的回答了這個問題,這里再做一下補充。從上述Spring源碼可知,其在第三級緩存中放入的是匿名類ObjectFactory,每次需要獲取對象實例就會調用其getObject方法。我們舉個例子:
假如現在沒有earlySingletonObjects這一層緩存(也就是第二級緩存),也就是兩級緩存結構,現在有三個對象,其依賴關系如下A->B、B->A和C、C->A,從這個依賴關系可以得出,A所在的ObjectFactory會被調用兩次getObject(),如果兩次都返回不同的proxy_A(畢竟后置處理器的代碼是使用者自己寫的,可能代碼是new Proxy(A)),那么就可能導致,B、C對象依賴的proxy_A不是一個對象,那么這種設計是致命的。
這個案例也從側面反映了三層緩存的設計必要性、必然性,也是為了讓框架更加的靈活健壯,以上就是我對Spring bean 三層緩存設計的理解,如有疑問歡迎在評論區討論留言。