ChatGPT原理解析
盡管OpenAI沒有公布ChatGPT的論文和相關的訓練和技術細節,但我們可以從其兄弟模型InstructGPT以及網絡上公開的碎片化的情報中尋找到實現ChatGPT的蛛絲馬跡。根據OpenAI所言,ChatGPT相對于InstructGPT的主要改進在于收集標注數據的方法上,而整個訓練過程沒有什么區別,因此,可以推測ChatGPT的訓練過程應該與InstructGPT的類似,大體上可分為3步:
1.預訓練一個超大的語言模型;
2.收集人工打分數據,訓練一個獎勵模型;
3.使用強化學習方法微調優化語言模型。
1、預訓練超大語言模型
從GPT/Bert開始,預訓練語言模型基本遵循這樣一個兩段式范式,即通過自監督方式來預訓練大模型。然后再在此基礎上,在下游具體任務上進行fine-tuning(微調)。其中GPT因為用的是單向Transformer解碼器,因此偏向于自然語言生成,而Bert用的是雙向Transformer編碼器,因此偏向于自然語言理解。因為Bert的及時開源和Google在業界的強大影響力,外加業務導向的AI應用公司寄希望的快速落地能力,那個時候絕大多數的從業者都更加看好Bert,哪怕是openai發布的GPT2也是反響平平,這也為后來的落后埋下了伏筆。
這種兩段式的語言模型,其Capability(能力)是單一的,即翻譯模型只能翻譯,填空模型只能填空,摘要模型只能做摘要等等,要在實際任務中使用,需要各自在各自的數據上做微調訓練,這顯然很不智能,為了進一步向類似人類思維的通用語言模型靠齊,GPT2開始引入更多的任務進行預訓練,這里的創新之處在于它通過自監督的模型來做監督學習的任務。經過這樣訓練的模型,能在沒有針對下游任務進行訓練的條件下,就在下游任務上有很好的表現。也就是說Capability有了較大的擴展,但此時的Alignment(對齊)還相對較弱,實際應用上還不能完全去除fine-tuning,算是為zero-shot leaning(零樣本學習)奠定了基礎。為了解決Alignment問題,GPT3使用了更大的模型,更多的數據,并優化了in-context learning(上下文學習)的訓練方式,即在訓練時去擬合接近人類語言的Prompt(提示),以指導模型它該做些什么,這進一步提升了模型zero-shot learning的能力,總而言之,語言模型在朝著越來越大的方向發展。

圖1 不同參數規模語言模型zero-shot效果對比
正如上面GPT3論文中的對比圖所示,zero-shot極度依賴于大語言模型(LLM),可以說從GPT3開始的語言模型的發展,已經與缺乏資源的普通人無關了,自然語言處理的發展已經全面進入了超大語言模型時代,但這并不影響我們去理解和借鑒其思想。
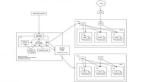
ChatGPT也正是依賴于一個大規模的語言模型(LLM)來進行冷啟動的,具體過程如圖2所示:

圖2 初始化預訓練語言模型
顯然,由于參與初始模型微調的人工生成數據量很少,對于整個語言模型的訓練數據而言是滄海一粟,因此初始化語言模型時,這一步的微調對ChatGPT整體而言大概是可有可無的。
盡管經過精心設計的LLM的Capability和Alignment均已達到非常好的水平,但是僅僅憑借預訓練或加一些監督文本微調得到的語言模型終究還是無法應對人類所生活的真實語言環境的復雜性,這種模型在實際應用中時長會暴露以下缺陷:
- 提供無效回答:沒有遵循用戶的明確指示,答非所問。
- 內容胡編亂造:純粹根據文字概率分布虛構出不合理的內容。
- 缺乏可解釋性:人們很難理解模型是如何得出特定決策的,難以確信回答的準確性。
- 內容偏見有害:模型從數據中獲取偏見,導致不公平或不準確的預測。
- 連續交互能力弱:長文本生成較弱,上下文無法做到連續。
2、訓練人類偏好模型
為了進一步增強語言模型的效果,人們試圖將強化學習引入到語言模型之中。但由于機器難以衡量自然語言輸出的質量好壞,這個研究方向一直發展緩慢,并且不被專業人員看好。盡管DeepMind早就提出了RLHF(Reinforcement Learning with human feedback)的訓練方法,但也一直沒有在實際產品中看見成效。OpenAI在InstructGPT中用一個小規模的GPT3模型通過RLHF微調后產生了比原始大GPT3更好的效果見證了RLHF的強大,隨后的ChatGPT真正將RLHF發揚光大。

圖3 原始RL框架
回想一下原始的強化學習框架,Agent要基于環境給出的獎勵信號來不斷優化自身的策略。那么在我們的聊天機器人的場景下,顯然語言模型作為一個Agent,它基于用戶輸入上下文語境(Environment)來輸出文本(action)。那么由什么來定義這個獎勵函數呢?正如前文所言,只有人才能夠評估輸出文本的好壞,那么就讓人來充當這個獎勵函數,這就是所謂的human feedback。但是這個更新過程需要不斷進行,顯然不能讓人一直在哪打分,那不妨就搞一個深度學習模型,去學習人類評估輸出質量的過程,于是便有了獎勵模型(Reward Model),如圖4所示。

圖4 獎勵(偏好)模型訓練框架
獎勵模型實際上就是去學習人類的偏好,因此也被叫作偏好模型。他的基本目標就是獲得一個打分模型,接收一系列的文本,并輸出一個標量獎勵,這個獎勵以數字的形式代表了人類對輸入輸出好壞的偏好。關鍵在于這個模型應當輸出一個標量獎勵,這樣方可與現有的RL算法無縫對接。獎勵模型基本上是基于其他的語言模型或者是通過Transformer從頭開始訓練。
OpenAI使用用戶以往通過GPT API提交的prompt,然后使用初始語言模型來生成一系列的新文本作為提示生成對(prompt-generation pairs)。然后再由人類訓練師來對初始LM生成的文本進行排序。雖然我們最初的想法是讓人類直接給這些輸出進行打分,但這在實踐中是很難做到的,人的不同打分標準容易導致這些分數跟實際有所偏差,而排序同樣可以用來比較多個模型輸出的質量,并且能夠創建一個更好的正則化數據集。有很多種方法用于對文本進行排序,一種比較成功的方式是讓用戶比較語言模型基于同一個prompt輸出的不同文本,通過兩個模型的輸出比較,再使用如Elo rating system(Elo系統)之類的方式來生成模型和輸出之間的相對排名,這樣就能將排名標準化為我們所需的標量獎勵信號。
至此,RLHF系統的兩個前置條件就達成了,接下來就是使用RL來進一步微調語言模型了。
3、強化學習微調
盡管業界已經近乎宣告強化學習不適用于語言模型,但仍舊有許多機構和科研人員在探索強化學習微調全部或部分語言模型參數的可行性,OpenAI就是其中最具代表性的。ChatGPT使用的是OpenAI自己提出的成熟的SOTA強化學習模型PPO來進行語言模型微調的,目前在語言模型上取得成功的RL算法也只有PPO,那么接下來就讓我們來看一下這個微調過程是如何被描述成一個RL問題的。
顯然,策略(Policy)是一個語言模型,它接受Prompt返回文本序列(或者只是文本上的概率分布)。策略的動作空間是語言模型詞匯表對應的所有token(通常在50000左右量級),觀測空間則是所有可能輸入的token序列(于是狀態空間在詞匯表大小^輸入token大小的量級),獎勵函數則由上述的偏好模型和策略轉移約束共同決定。于是整個過程大概是這樣的:
? 從訓練集采樣一個prompt: ;
;
? 從原始的語言模型產生一個文本序列 ,從當前微調迭代的語言模型產生一個文本序列
,從當前微調迭代的語言模型產生一個文本序列 ;
;
? 把當前策略產生的文本輸入到偏好模型,得到一個標量獎勵 ;
;
? 將文本 與
與 進行對比,一般使用KL散度來計算它們之間的差異
進行對比,一般使用KL散度來計算它們之間的差異 ,這個作為一種變化約束,來防止模型生成能夠欺騙偏好模型卻胡言亂語的文本;
,這個作為一種變化約束,來防止模型生成能夠欺騙偏好模型卻胡言亂語的文本;
? 結合 和
和 就得到了用于RL更新的最終的獎勵函數:
就得到了用于RL更新的最終的獎勵函數: ,不過OpenAI在訓練InstructGPT時,還在這個基礎上還添加了額外的在人類標注集合上的預訓練梯度;
,不過OpenAI在訓練InstructGPT時,還在這個基礎上還添加了額外的在人類標注集合上的預訓練梯度;
? 接下來就是跟普通PPO一樣通過最大化當前批次的回報來進行在線更新。

圖5 強化學習微調框架
語言模型經過PPO算法的不斷自我迭代,外加獎勵函數的不斷人工糾偏,這個語言模型將如同AlphaGo那樣不斷完成進行自我進化,最終達到令人驚艷的效果。
4、總結
1?? ChatGPT向業界證明了GPT路線的優越性。實際上從GPT3開始,GPT技術路線在通用人工智能上已經成為一種演進趨勢。
2?? ChatGPT以其卓越的表現將RLHF方法重新帶入到了研究人員的視野,接下來可能會在更多的場合發光發熱,比如將RLHF與圖像領域的Diffusion結合,或將碰撞出意想不到的火花。
3?? RLHF在很大程度上解決了語言模型的對齊問題,使通用大模型走進人們的生活成為可能,但由于嚴重依賴人工標注者的偏好,這將影響到模型的公平性,或存在安全隱患。
??參考文獻
[1] Paul Christiano, Jan Leike, Tom B. Brown et al.?Deep reinforcement learning from human preferences. arXiv preprint arXiv:1706.03741.
[2] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida et al.Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155.
[3]《Illustrating Reinforcement Learning from Human Feedback (RLHF)》,https://huggingface.co/blog/rlhf.
[4] John Schulman, Filip Wolski, Prafulla Dhariwal, et al.?Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347.