譯者 | 崔皓
審校 | 孫淑娟
開篇
AIGC 行業最大的兩個競爭對手:ChatGPT vs Google Bard! 本文介紹這兩個人工智能引擎之間的技術差異。
截至目前Google Bard和ChatGPT之間最大的區別是:Bard知道ChatGPT,但ChatGPT卻對Bard懵然不知。雖然我們可以玩轉ChatGPT,而Bard對我們大多數人來說仍然遙不可及。?

ChatGPT與Google Bard之戰的開始
ChatGPT和Google Bard都是人工智能聊天機器人。人工智能的簡易版本已經可以在手機上使用了,當你輸入 "good"時,手機就可以預測下一個詞是 "morning"。?
ChatGPT最初是由OpenAI開發的,然后由微軟以令人瞠目結舌的100億美元(除了早先的10億美元投資外)進行投資。谷歌方面,對他們的搜索壟斷可能要結束而略感恐慌,因此推出了Bard,但這個版本仍然存在一些缺陷。在第一次現場演示中,Bard犯了幾個事實性錯誤,讓谷歌感到很尷尬。?
ChatGPT和Google Bard比智能手機的預測文本功能要更加復雜,如果說要了解這兩款智能機器人之間的差異,下面的內容你就不能錯過了。?
這里我們會深入描述兩個人工智能引擎之間的技術差異。?
ChatGPT與Bard:內藏玄機?
我們可以通過如下表格快速了解它們之間的技術差異,通過表格可以看到很多細節。
ChatGPT? | Bard? | |
模型? | GPT-3.5? | LaMDA,即對話應用的語言模型? |
神經網絡結構? | Transformer? | Transformer? |
訓練數據? | 網絡文本,主要是被稱為 "common?crawl"的數據集,在2021年中期截止。? | 156萬字的公共對話數據和網絡文本? |
目的? | 成為一個多用途的文本生成聊天機器人? | 專門協助搜索? |
參數? | 1750億參數? | 1370億參數? |
創建者? | OpenAI? | Google? |
優勢? | - 對所有人開放? - 更加靈活,能夠處理開放式文本? - 訓練數據截止到2021年? | - 訓練數據截止到當前? - 專門為對話而訓練,所以當你和它對話的時候,聽起來更像人。? |
劣勢? | - 對話沒有那么有說服力? - 沒有那么仔細的微調? | - 目前還沒有? - 可能不那么適合一般的文本創作? |
通過上面的表格了解了兩者之間的差異,接下來讓我們深入了解一下其他指標。
什么是ChatGPT?
ChatGPT于2022年11月30日突然出現在舞臺上。到2022年12月4日,該服務每天有超過一百萬的用戶。2023年1月,這個數字膨脹到1億多用戶。?
它突然這么受歡迎其基本原因是,它能以一種聽起來幾乎是人類的方式,為你提供許多主題的靠譜回答,而且任何能夠上網的人都可以使用它。?
ChatGPT是OpenAI創建的,OpenAI是一家位于舊金山的人工智能實驗室,專注于創造友好的人工智能方案。該聊天機器人是基于GPT-3.5開發的,GPT-3.5是一個大型語言模型,當給定文本時,可以持續給請求者提供回復。?
ChatGPT在此基礎上增加了一些額外的訓練--人類培訓師通過與模型的互動改進了模型,并通過"獎勵 "的方式讓模型具備提供高質量答案的能力。?
訓練數據
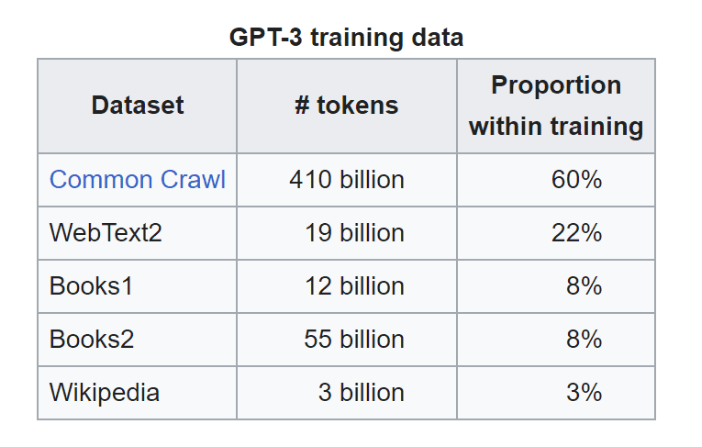
GPT-3.5是在一個巨大的網絡文本數據集上訓練的,包括一個叫做Common Crawl的流行數據集。Common Crawl包含PB級的網絡數據,包括原始網頁數據、元數據提取和文本提取。例如,它包括來自StrataScratch的URLs集合。想想ChatGPT使用訓練的數據來自網友在ChatGPT的輸入,這是不是很瘋狂??
Common Crawl負責60%的訓練數據,但GPT-3.5也有其他數據來源。?
什么是Google Bard?
Google Bard 是在ChatGPT大受追捧的情況下,由Google推出的智能聊天機器人。與ChatGPT不同,Bard是由Google自己的模型LaMDA驅動。LaMDA是對話應用語言模型的簡稱,與ChatGPT不同的是,它沒有那么驚艷,原因很簡單,大多數人還不能訪問它。盡管Google在2月初確實搞了一個充滿尷尬的Bard演示,但目前Bard只對少數人開放。?
Google Bard的主要優勢是它對互聯網開放。問ChatGPT“現在誰是總統?”,它是不知道的。這是因為訓練數據在2021年中期左右被切斷了。而Bard則是借鑒了今天互聯網上的信息。從理論上講,Bard應該能夠從今天互聯網上的數據中提取,告訴你現在誰是總統。?
很容易看出Bard在幾個關鍵方面是如何從ChatGPT中脫穎而出的。?
訓練數據
首先,LaMDA是在對話中訓練的,專門用于對話,而不是像GPT-n模型那樣只產生文本。雖然ChatGPT對其訓練數據不加掩飾,但我們對Bard所訓練的數據還不甚了解,可以通過查看LaMDA的研究論文來推斷。谷歌的研究人員說,12.5%的訓練數據來自Common Crawl,比如GPT-n模型。另外12.5%來自維基百科。而根據研究論文,他們使用了1.56萬億字的 "公共對話數據和網絡文本"。?
以下是完整的分類:?
- 12.5%基于C4的數據(Common Crawl數據的衍生品)。?
- 12.5%的英語維基百科?
- 12.5%來自編程問答網站、教程和其他的代碼文檔?
- 6.25%的英文網絡文檔?
- 6.25%的非英語網絡文檔?
- 50%來自公共論壇的對話數據?
從上面的信息可以知道兩者共同利用的數據,顯然有維基百科。其余的數據明顯是Google故意隱藏的,大概是為了保護Bard(和LaMDA)不被模仿。?
LaMDA是通過微調Transformer的神經語言模型而形成的,它是一個最初由谷歌開發的開源神經網絡架構。(GPT也是建立在Transformer的基礎上)。
ChatGPT存在一些壁壘,以防止它讓人生厭或者說一些廢話,但谷歌強調如何保證質量,以使Bard變成更好、更安全的聊天機器人。Bard經過微調,變得"高質量、接地氣和安全"。?
谷歌對此有很多說法,我建議閱讀他們的相關博文,但如果你時間不多,基本上可以分成如下幾個方面:?
- Bard應該給出有意義的回應--沒有荒謬的內容,沒有矛盾的內容?
- Bard應作出有見地、詼諧或出人意料的回應。?
- Bard應該避免任何有可能對用戶造成傷害的東西--血腥、偏見、可憎的刻板印象等?
- Bard不胡編亂造?
眾所周知,由于一次錯誤的發布,谷歌還沒有完全弄清楚底層需求。但值得注意的是,谷歌對設計要求說得很清楚,而ChatGPT沒有說的那么清楚--至少目前是這樣。?
ChatGPT與Google Bard對比:模型參數為什么很重要?
ChatGPT確實比Bard擁有更多的模型參數--1750億對1370億。你可以把參數看作是模型調整的旋鈕或杠桿,以適應它所訓練的數據。更多的參數通常意味著模型有更多的能力來捕捉語言中的復雜關系,但也有過度擬合的風險。與ChatGPT相比,Google Bard可能不那么靈活,但也可能因為新的語言用例使其更加強大。?
ChatGPT與Google Bard:共同點?
值得強調的是,Bard和ChatGPT的模型(分別是LaMDA和GPT-3.5)都位于基于Transformer的深度學習神經網絡。?
例如,Transformer可以使一個經過訓練的模型來閱讀一個句子或段落,注意這些詞之間的關系,然后預測它認為接下來會出現什么詞--類似前面提到的智能手機預測性文本的功能。?
這里就不展開討論了,但你需要知道的是,這意味著在其核心部分,Bard和ChatGPT彼此之間沒有太大區別。?
ChatGPT與Google Bard:所有權
雖然所有權并不完全是一個技術上的差異,但它是值得記住的。?
Google Bard是由Google制作并完全擁有的,在LaMDA之上,LaMDA也是由Google創建的。?
ChatGPT是由OpenAI開發的,這是一家位于舊金山的人工智能研究實驗室。OpenAI最初是非營利性的,但它在2019年創建了一個營利性的子公司。OpenAI也是Dall-E的幕后推手,你可能玩過的人工智能文本到圖像的生成。?
雖然微軟在OpenAI上投入了大量資金,但就目前而言,它是一個獨立的研究機構。
ChatGPT和谷歌 Bard哪個好?
這個問題很難給出公平的回答,因為兩者相似的地方很多,但也有不同的地方。首先,現在幾乎沒有人可以訪問Google Bard。另外,ChatGPT的訓練數據幾乎在兩年前就被切斷了。?
兩者都是文本生成器--你提供一個提示,Google Bard和ChatGPT都能回答。兩者都有數十億的參數來微調模型。兩者都有重疊的訓練數據源,并且都建立在Transformer上,即同一個神經網絡模型。?
它們的設計目的也不同,Bard將幫助你瀏覽谷歌搜索,它被設計為對話式的。ChatGPT可以生成整個博客文章。它的設計是為了輸出有意義的文本。?
即便說了ChatGPT和Google Bard之間的差異,那也只能證明人工智能驅動的文本生成技術已經取得了多大進展。雖然它們都有一段路要走,而且都面臨著版權和道德方面的爭議,但這兩個生成器都是現代人工智能模型發展的有力證明。?
譯者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。
原文標題:??ChatGPT vs Google Bard: A Comparison of the Technical Differences??,作者:Nate Rosidi