一次只要0.003美元,比人類便宜20倍!ChatGPT讓數據標注者危矣
當前,很多自然語言處理(NLP)應用需要高質量的標注數據來支撐,特別是當這些數據被用于訓練分類器或評估無監督模型的性能等任務中。
例如,人工智能研究人員通常希望過濾嘈雜的社交媒體數據的相關性,將文本分配到不同的主題或概念類別,或衡量其情緒或立場。
而且,無論這些任務使用什么具體方法(監督、半監督或無監督),都需要標注好的數據來建立一個訓練集或黃金標準。
然而,在大多數情況下,要完成高質量的數據標注(data annotation)工作,依然離不開數據標注平臺上的眾包工作者或諸如研究助理等訓練有素的標注者來手動進行。
通常情況下,訓練有素的標注者先創建一個相對較小的黃金標準數據集,然后雇用眾包工作者來增加標注數據的數量,進行重復性工作。根據規模大小和復雜程度,數據標注任務有時會非常費時費力,不僅需要花費一定的人力成本,而且也不能保證數據標注的質量。
那么,能否讓機器幫助人類完成這一基礎任務呢?
在以往的認知中,機器并不擅長這類「慢工出細活」的任務,但出乎意料的是,「數據標注」這件事已經讓 ChatGPT 完成了,而且比大多數人做得還更好。

在一項今天發表的新研究中,來自蘇黎世大學的研究團隊使用由 2382 條推文組成的樣本,證明了 ChatGPT 在相關性、主題和框架檢測等標多個注任務上優于眾包工作者。
相關研究論文以「ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks」為題,已發表在預印本網站 arXiv 上。
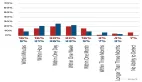
具體來說,ChatGPT 在五項任務的四項中的零樣本(zero-shot)準確率超過了眾包工作者;在所有任務中表現出的編碼者間一致性(intercoder agreement)方面,ChatGPT 不僅超過了眾包工作者,也同樣超過了訓練有素的標注者。?

ChatGPT 零樣本文本數據標注表現
值得一提的是,ChatGPT 的每個標注成本只有不到 0.003 美元,而比數據標注平臺便宜約 20 倍。
研究團隊認為,雖然需要進一步的研究來更好地了解 ChatGPT 和其他 LLMs 在更廣泛的背景下的表現,但該研究結果表明,它們有可能改變研究人員進行數據注釋的方式,極大地提高文本分類的效率,并破壞數據標注平臺的部分商業模式。
至少,從目前來看,這些發現表明了更深入地研究 LLMs 的文本標注特性和能力的重要性。
未來,研究團隊將在 ChatGPT 在多種語言中的表現、ChatGPT 在多種類型的文本(社會媒體、新聞媒體、立法、演講等)中的表現、使用思維鏈(CoT)提示和其他策略來提高零樣本推理的性能等方面繼續努力。
值得一提的是,研究團隊在進行這項工作時,OpenAI 還沒有發布 GPT-4,如果讓 GPT-4 來完成數據標注任務,又會是怎樣的結果呢?