后端面霸之旅-MapReduce探秘
最近在看一些大數據的東西,發現對其中的shuffle過程很模糊,于是決定學習一下,深入之后又發現對整個mapreduce的數據完成處理過程也同樣模糊。
所以本文將從以下幾個角度來展開:
- mapreduce以及hadoop框架的一些認識
- mapreduce的核心思想是什么
- mapreduce數據處理過程推演
- mapreduce的shuffle是如何實現的
Hadoop三劍客
Hadoop是一個由Apache開發的大數據處理框架,它包括了HDFS(Hadoop分布式文件系統)、YARN(Yet Another Resource Negotiator,資源管理器)以及MapReduce計算框架。
HDFS是Hadoop的存儲組件,YARN則是用于資源管理和調度的組件,而MapReduce是Hadoop用于分布式計算的框架。
在Hadoop中,數據通常存儲在HDFS中,通過MapReduce框架進行分布式計算,YARN負責管理計算資源,并協調MapReduce等計算框架的運行。
MapReduce、Hadoop、HDFS和YARN之間是相互依存、協同工作的關系,它們共同構成了一個完整的大數據處理系統。

MapReduce核心思想
分而治之
MapReduce的主要思想是將大規模數據處理任務分解成多個小任務,并在分布式計算集群上并行執行,從而實現高效的數據處理和分析。
MapReduce數據處理任務分為兩個主要階段:Map階段和Reduce階段。
在Map階段中,MapReduce將輸入數據分割成若干個小塊,然后在分布式計算集群上同時執行多個Map任務,每個任務都對一個小塊的數據進行處理,并將處理結果輸出為一系列鍵值對,Map任務的輸出結果會被臨時存儲在本地磁盤或內存中,以供Reduce任務使用。
在Reduce階段中,它主要負責對Map任務的輸出結果進行整合和匯總,生成最終的輸出結果。Reduce任務會將所有Map任務輸出的鍵值對按照鍵進行排序,并將相同鍵的值合并在一起,Reduce任務的輸出結果通常會寫入到文件系統中

計算向數據靠攏
在傳統的分布式計算中,數據通常需要從存儲介質中讀取到計算節點進行處理,這會造成大量的數據傳輸和網絡延遲,導致計算效率較低。
"計算向數據靠攏"是MapReduce的一個設計思想,旨在最大化利用數據本地性(data locality)來提高作業的性能。
在MapReduce中,數據通常分布在集群的不同節點上,而處理數據的任務(Map任務和Reduce任務)盡量在數據所在的節點上執行,減少數據的網絡傳輸和節點間的通信開銷,提高作業的性能。
MapReduce過程推演
我們嘗試從頭來推演整個MapReduce任務的大致執行過程:
- 怎么寫跨語言的MapReduce作業?
- JobClient做了些什么?
- JobClient和Yarn是如何交互的?
- Hadoop2.x中AppMaster、NodeManager是如何協作的?
- 輸入文件分割是怎么實現的?
Hadoop Streaming
如果使用非 Java 編程語言來實現 MapReduce 任務,或者希望更靈活地定制 Map 和 Reduce 函數的實現方式,可以考慮使用 Hadoop Streaming。
Hadoop Streaming 是 Hadoop 提供的一個工具,可以讓用戶通過標準輸入和標準輸出來實現自定義 Map 和 Reduce 函數的功能。使用 Hadoop Streaming 可以使用任何語言來實現 Map 和 Reduce 函數,而不僅僅局限于 Java。
當使用 Hadoop Streaming 時,客戶端會將 Map 和 Reduce 函數打包成可執行文件,然后提交給 Hadoop 集群來執行。這些可執行文件可以用任何編程語言編寫,例如 Python、Perl、Ruby、C++ 等。

JobClient
在提交任務之前,客戶端需要將任務的輸入數據和輸出路徑等信息設置好,以便Hadoop集群能夠正確地執行任務并將結果輸出到指定的路徑。
MapReduce的客戶端JobClient通常會將任務打包成JAR包,然后將該JAR包提交給Hadoop集群來執行任務。
JAR包中包含了MapReduce任務所需的輸入數據、輸出路徑、 Map 和 Reduce 的數量,以及每個任務需要的內存和 CPU 資源等參數,這樣可以保證任務在集群中的任何節點上都能夠正常運行。
hadoop 1.x和2.x
在Hadoop 1.x版本中,JobTracker和TaskTracker是Hadoop集群中的兩個重要組件,其中JobTracker負責整個集群中所有MapReduce任務的協調和管理,而TaskTracker負責具體的任務執行。
在Hadoop 2.x版本中引入了YARN框架,將JobTracker的功能拆分成兩部分,一部分是ResourceManager,負責集群資源的管理和分配,另一部分是ApplicationMaster,負責具體任務的管理和協調。
在Hadoop 2.x版本及以后的版本中,ApplicationMaster扮演的角色類似于JobTracker。
AppMaster
在 Hadoop YARN 中,ApplicationMaster是一個關鍵的組件,它負責在集群中管理和監控一個特定的應用程序。
在 MapReduce 中,每個 MapReduce 作業都有一個對應的 ApplicationMaster 實例,該實例負責協調整個作業的執行過程,包括分配任務、監控任務的進度和狀態、處理任務失敗等。
當客戶端提交 MapReduce 作業時,YARN 資源管理器會為該作業啟動一個 ApplicationMaster 實例。
ApplicationMaster 將向資源管理器請求分配資源,并與各個 NodeManager 協商任務的執行。它還負責將 MapReduce 作業的邏輯劃分為多個 Map 和 Reduce 任務,并將任務分配給相應的 NodeManager 執行。
在任務執行期間,ApplicationMaster 將持續監控任務的進度和狀態,并在任務出現錯誤或失敗時進行相應的處理。
NodeManager
AppMaster和NodeManager不同,它們是YARN框架中的兩個不同的組件,分別扮演著不同的角色。
AppMaster是一個應用程序級別的組件,它運行在分布式集群中的一個節點上,負責協調和管理應用程序的生命周期。它向ResourceManager請求資源,然后將這些資源分配給它的任務(如Map和Reduce任務)。在任務運行期間,AppMaster監視任務的進度并與ResourceManager通信,以確保應用程序在分布式集群上有效地運行。
NodeManager是一個節點級別的組件,它運行在每個節點上,負責管理該節點上的容器和資源。在應用程序啟動時,AppMaster向ResourceManager請求節點資源,并指示NodeManager在該節點上啟動容器來執行應用程序的任務。
NodeManager負責啟動容器并為它們分配資源,同時監視它們的進度,并向ResourceManager報告資源使用情況。

HDFS輸入文件邏輯分割
客戶端程序中的Job對象會設置輸入文件的路徑和InputFormat類,在提交作業之前,Job會調用InputFormat的getSplits()方法來獲取輸入文件的切片信息。
InputFormat 是針對輸入文件進行邏輯分割,將一個或多個輸入文件劃分為一組輸入切片InputSplit,以便于 MapReduce 作業的并行處理。
對于大多數常見的數據類型,Hadoop 提供了一些內置的 InputFormat 實現,如下:
- TextInputFormat:按行讀取文本文件,并將每行作為一個輸入記錄。
- KeyValueTextInputFormat:按行讀取鍵值對形式的文本文件,并將每個鍵值對作為一個輸入記錄。
- SequenceFileInputFormat:讀取 Hadoop 序列文件(SequenceFile),并將其中的每個 key-value 對作為一個輸入記錄。
- CombineFileInputFormat:支持讀取多個小文件或者多個小數據塊,并將它們合并成一個或多個輸入切片,以便于提高作業的并行度和執行效率。
輸入文件的切片由InputFormat的getSplits()方法生成,這個方法會計算輸入文件的切片,并返回一個切片數組。每個切片都包含了一個起始偏移量和一個長度,這些信息告訴了Map任務它需要處理的輸入數據的范圍,ResourceManager會根據Split對象數組來計算作業需要的資源,并分配相應的資源來運行作業。
當Map任務啟動時,它會使用InputFormat提供的InputSplit信息來創建一個RecordReader實例,用于讀取該Map任務需要處理的輸入數據。
RecordReader從HDFS或其他存儲系統中讀取數據,將數據劃分成適當大小的記錄,然后將它們轉換為鍵值對(key-value pairs),再將它們傳遞給Mapper進行處理。

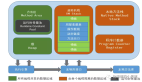
shuffle簡介
先看一個完整的圖,接下來會進行展開:

什么是shuffle
在 MapReduce 中,Map 和 Reduce 任務都是并行執行的,Map 任務負責對輸入數據進行處理,將其轉換為鍵值對的形式,而 Reduce 任務負責對 Map 任務的輸出結果進行聚合和計算。
在 MapReduce 中,Shuffle 過程的主要作用是將 Map 任務的輸出結果傳遞給 Reduce 任務,并為 Reduce 任務提供輸入數據,它是 MapReduce 中非常重要的一個步驟,可以提高 MapReduce 作業效率。
Shuffle 過程的作用包括以下幾點:
- 合并相同 Key 的 Value:Map 任務輸出的鍵值對可能會包含相同的 Key,Shuffle 過程會將相同 Key 的 Value 合并在一起,減少 Reduce 任務需要處理的數據量。
- 按照 Key 進行排序:Shuffle 過程會將 Map 任務的輸出結果按照 Key 進行排序,這樣 Reduce 任務可以順序地處理鍵值對序列,避免在處理數據時需要進行額外的排序操作。
- 劃分數據并傳輸:Shuffle 過程會將 Map 任務的輸出結果按照 Key 劃分成多個分區,并將每個分區的數據傳輸到對應的 Reduce 任務中。這樣,Reduce 任務可以從不同的 Map 任務中獲取到數據,從而實現更好的并行化處理。

Map端的Shuffle
- Map任務在執行過程中會將輸出的鍵值對寫入本地磁盤上的環形緩沖區中,按照Partitioner函數的規則將鍵值對映射到不同的區域Partition中。
- 當環形緩沖區滿或者Map任務執行完畢時,Map任務將環形緩沖區中的數據進行排序,并按照Partition和排序結果寫入到本地磁盤上的Spill文件中。
- 當所有Map任務都執行完畢后,MapReduce會按照Partition對所有Spill文件進行歸并排序,形成一個有序的大文件。
環形緩沖區的作用
環形緩沖區是一種特殊的緩沖區,它將數據存儲在一個固定大小的、循環的緩沖區中,當緩沖區滿時,新的數據將覆蓋最老的數據,于鏈表和數組等數據結構,環形緩沖區具有以下優勢:
- 高效的讀寫性能:由于環形緩沖區具有固定的大小,可以預先分配一定的空間,因此讀寫操作非常高效。而且由于緩沖區是循環的,可以通過簡單的指針操作來實現數據的讀寫操作,而不需要復雜的數據移動操作。
- 空間利用率高:由于環形緩沖區可以循環利用空間,因此空間利用率非常高。相比于鏈表和數組等數據結構,它不需要額外的空間來維護節點或索引等信息,可以更好地利用內存空間。
- 易于實現和管理:由于環形緩沖區的結構非常簡單,因此易于實現和管理。可以通過一些簡單的技術來解決緩沖區溢出等問題,從而保證 Shuffle 過程的正確性。
分區&排序&溢寫
在 Map 階段中,Map 任務會將輸出數據寫入環形緩沖區,而這些數據會被分為多個分區,并且每個分區內的數據是按照鍵(Key)進行排序的。
分區的劃分是由 Partitioner 類完成的,默認情況下,Partitioner 類會根據鍵值對的鍵(Key)來計算分區編號(Partition ID),從而將數據分配到對應的分區中。
不同的鍵(Key)可能會被分到同一個分區中,而相同的鍵(Key)則一定會被分到同一個分區中,這是為了保證相同鍵(Key)的數據能夠被發送到同一個 Reduce 任務中進行處理。
Map 任務向環形緩沖區中寫入數據時,先將數據插入到分區內,然后對該分區內的所有數據進行快速排序。
當環形緩沖區中的數據量達到一定閾值(MapReduce 1.x 中默認為環形緩沖區大小的 0.8 倍),或者某個分區內存放的數據大小達到一定閾值(MapReduce 1.x 中默認為 100MB),就會觸發溢寫操作,將數據按照分區寫到磁盤上的臨時文件中。

Reduce端的Shuffle
- map的shuffle階段會生成包含不同分區的大文件
- reduce任務可能會多個不同的分區,但是同一個分區的數據一定在同一個reduce中
- reduce任務收集來自多個map輸出的同一個分區的數據,在內部再針對同一分區的多個文件做歸并成一個大文件

小結
很多時候明確問題比知道答案更重要,多想為什么、多在腦海里去推演過程、最終才能自洽吸收外界知識,化為自己的經驗。?