由 ChatGPT 帶來的對(duì)低代碼產(chǎn)品的思考

在之前的文章中多次提到我們?cè)陂_發(fā)一款低代碼平臺(tái),主要面向 ToB 企業(yè),幫助企業(yè)完善信息化建設(shè),給企業(yè)的數(shù)字化轉(zhuǎn)型貢獻(xiàn)一份力量。
數(shù)字化轉(zhuǎn)型的目標(biāo)是降本增效,同樣,效率對(duì)我們來說也至關(guān)重要,主要體現(xiàn)在:售前能快速提供原型和客戶溝通、實(shí)施過程中能高效交付、售后遇到的各種問題能立馬找到答案。
最近,ChatGPT 持續(xù)火熱,每天在推上都能發(fā)現(xiàn)新的應(yīng)用,那么 ChatGPT 和我們的低代碼產(chǎn)品能結(jié)合嗎?或者說這種大語言模型的思路能給低代碼帶來怎樣的效率提升?
其實(shí)一些巨頭已經(jīng)這樣做了。
Salesforce 宣布推出新產(chǎn)品 EinsteinGPT,這是一種基于 LLM 技術(shù)的產(chǎn)品,它與 Salesforce 的主要網(wǎng)絡(luò)應(yīng)用程序集成,利用 OpenAI ChatGPT 模型來幫助跟蹤銷售人員聯(lián)系潛在客戶的頻率,并自動(dòng)編寫營(yíng)銷電子郵件,無需手動(dòng)編寫電子郵件。
另一方面,微軟也宣布將 ChatGPT 技術(shù)擴(kuò)展到 Power Platform 平臺(tái)上。Power Platform 是微軟的一款低代碼產(chǎn)品,在《最近看了兩本低代碼的書》中有介紹。這意味著 Power Platform 上的 Power 虛擬代理和 AI Builder,都已經(jīng)更新了 ChatGPT 編碼功能,使用戶可以在很少甚至不用編寫代碼的情況下,開發(fā)自己的應(yīng)用程序。
Salesforce 將其應(yīng)用在業(yè)務(wù)能力上,微軟則在平臺(tái)能力上進(jìn)行了增強(qiáng)。對(duì)我們來說,售前和實(shí)施中需要的是能快速搭建應(yīng)用,售后需要快速解決問題,所以有兩個(gè)方向可以去做:
1、應(yīng)用搭建效率的提升。
2、構(gòu)建智能問答系統(tǒng)。
目前項(xiàng)目實(shí)施的步驟如下:
- 需求分析師和客戶溝通完后,整理出需求文檔。
- 需求分析師對(duì)搭建工程師和開發(fā)進(jìn)行需求宣講。
- 可以通過配置實(shí)現(xiàn)的部分由搭建工程師進(jìn)行搭建配置,其他部分由開發(fā)人員進(jìn)行定制開發(fā)然后和平臺(tái)進(jìn)行集成。
讓低代碼產(chǎn)品集成了 ChatGPT 的能力后,系統(tǒng)就會(huì)變成這樣:
- 系統(tǒng)具備理解自然語言的能力。
- 需求分析和客戶聊完形成的文檔本身就是自然語言描述的。
- 在系統(tǒng)中有聊天對(duì)話框和進(jìn)行交互。
- 在對(duì)話框輸入需求描述,能夠識(shí)別關(guān)鍵信息,關(guān)鍵信息包括接口識(shí)別、參數(shù)提取。
- 調(diào)用平臺(tái)接口進(jìn)行應(yīng)用的創(chuàng)建,或者局部功能調(diào)整。
- 就這樣聊著天把系統(tǒng)給做完了。
例如:在對(duì)話框中輸入,將當(dāng)前列表的項(xiàng)目名稱這一列寬度調(diào)整到 500 ,這時(shí)就需要能識(shí)別參數(shù):項(xiàng)目名稱和寬度 500,而且知道需要調(diào)用調(diào)整列寬的接口。
現(xiàn)有的低代碼平臺(tái)在后臺(tái)做完各種配置后,點(diǎn)擊保存后,前端收集所有數(shù)據(jù)傳遞給接口,接口的顆粒度比較粗,一次性會(huì)存儲(chǔ)很多內(nèi)容,但上面例子中調(diào)整一個(gè)列的列寬設(shè)置就需要一個(gè)接口,這就需要接口的顆粒度非常細(xì),所以,改造接口顆粒度是實(shí)現(xiàn)智能化的第一步。
上面說結(jié)合 ChatGPT 的能力,并不是直接對(duì)接 ChatGPT 的接口,所以說要實(shí)現(xiàn)還是相當(dāng)有難度的。不過一個(gè)新的技術(shù)興起到完全在 ToB 市場(chǎng)中普及,是有一個(gè)時(shí)間周期的,只要方向沒錯(cuò),完全有這個(gè)準(zhǔn)備的時(shí)間。
目前在項(xiàng)目實(shí)施過程中存在幾個(gè)問題,這也是為什么一個(gè)智能問題系統(tǒng)很重要的原因:
- 因?yàn)槠脚_(tái)功能多、非常靈活,以至于同樣的需求不同的人去實(shí)現(xiàn),方法和途徑是不一樣的,工作量可能有好幾倍的差距;
- 實(shí)施過程中遇到的各種產(chǎn)品問題,需要找熟悉的同事詢問,或者咨詢產(chǎn)品團(tuán)隊(duì)。
現(xiàn)在的方式就是通過文檔搜索,這些年也沉淀了非常多的文檔,比如:業(yè)務(wù)場(chǎng)景案例、操作手冊(cè)、實(shí)施常見問題手冊(cè)等,不過是基于關(guān)鍵字搜索的,用關(guān)鍵字搜索有幾個(gè)問題:
- 很多時(shí)候不知道怎么提取關(guān)鍵字。
- 搜索的結(jié)果非常多,不能精準(zhǔn)匹配,隨著文檔的增多,需要在大量的結(jié)果中去篩選。
- 針對(duì)某個(gè)業(yè)務(wù)場(chǎng)景去尋找搭建方案,匹配度非常差。
如果按照 ChatGPT 的思路,智能問答系統(tǒng)的邏輯就是這樣的:
- 所有沉淀的文檔(語料庫)生成向量數(shù)據(jù)存儲(chǔ)到向量數(shù)據(jù)庫。
- 輸入的自然語言生成向量,計(jì)算相似度,找到相關(guān)結(jié)果。
- 整理輸出。
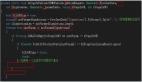
針對(duì)這個(gè)問題,我在知識(shí)星球問過張善友大佬,下面的圖就是張善友提供的:

寶玉在推上也回答過類似的問題:
https://twitter-thread.com/t/1641656561650249730。
不過張善友和寶玉提供的參數(shù)都是依賴 OpenAI 的接口,如果不依賴 OpenAI,有辦法實(shí)現(xiàn)嗎?這需要進(jìn)一步去學(xué)習(xí)和研究。
最近看到 Supabase 產(chǎn)品的文檔就提供了 AI 問答(https://supabase.com/docs),這個(gè)效果就是我想要達(dá)到的,總結(jié)下就是根據(jù)自然語言的輸入,給一個(gè)精準(zhǔn)的答案。

未來已經(jīng)到來,不管是產(chǎn)品還是個(gè)人,都需要持續(xù)不斷地學(xué)習(xí)和進(jìn)化,才能不被淘汰。