?Bash 成為了每個類 Unix 或基于 Unix 的操作系統的默認自動化語言。每個系統管理員、DevOps 工程師和程序員通常使用 Bash 編寫具有重復命令序列的 shell 腳本。Bash 腳本通常包含運行其他程序二進制文件的命令。在大多數情況下,我們可能需要在 shell 腳本中處理數據并創建邏輯流程。因此,我們經常需要在 shell 腳本中添加條件語句和文本操作語句。
?傳統的 Bash 腳本和使用舊版本 Bash 解釋器的過去的程序員通常使用 awk、sed、tr 和 cut 命令進行文本操作。這些是單獨的程序。盡管這些文本處理程序提供了良好的功能,但它們會減慢您的 Bash 腳本,因為每個特定命令都具有相當的進程生成時間。現代 Bash 版本通過著名的參數擴展功能提供了內置的文本處理功能。
在本文中,我將解釋一些內置的字符串操作語法,您可以使用這些語法在 Bash 腳本中高效地處理文本。

子字符串提取和替換
子字符串是指特定字符串的連續片段或部分。在各種腳本編寫場景中,我們需要從字符串片段中提取子字符串。例如,您可能需要僅從包含擴展名的完整文件名中獲取文件名部分。此外,您可能需要使用特定字符串段替換子字符串(例如,更改文件名的文件擴展名)。
提取子字符串非常容易,只需提供字符位置和長度:
#!/bin/bash
# Linux迷 www.linuxmi.com
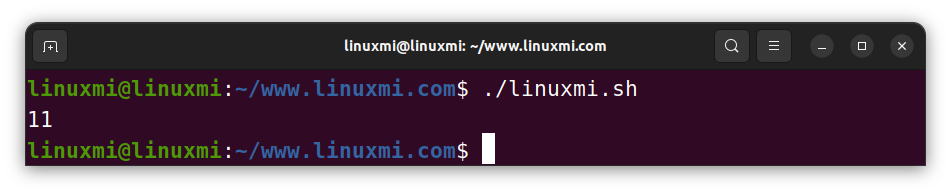
str="2023-10-12"
echo "${str:5:2}" # 10
echo "${str::4}" # 2023
echo "2022-${str:5}" # 2022-10-12
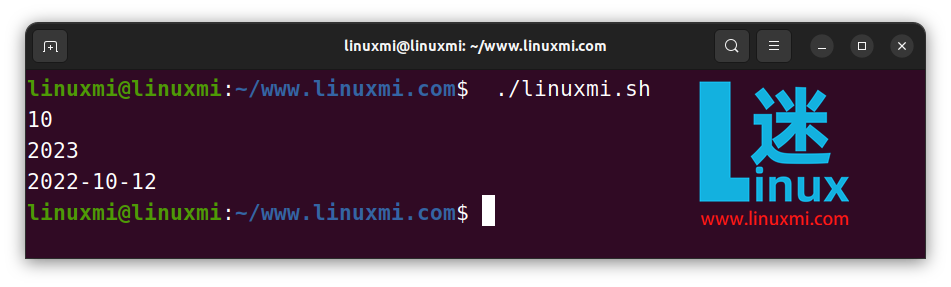
你甚至可以從右邊進行子字符串計算,如下所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
str="backup.sql"
echo "original${str:(-4)}" # original.sql
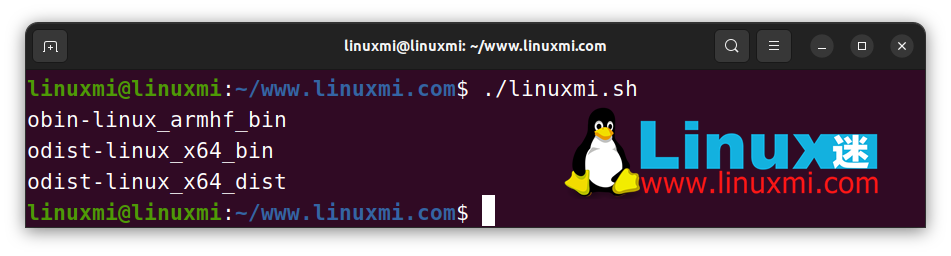
Bash 還提供了一種高效的內置語法來進行子字符串替換:
#!/bin/bash
# Linux迷 www.linuxmi.com
str= "obin-linux_x64_bin"
echo " ${str/x64/armhf} " # obin-linux_armhf_bin
echo " ${str/bin/dist} " # odist-linux_x64_bin
echo " ${str// bin/dist} " # odist-linux_x64_dist
linuxmi@linuxmi:~/www.linuxmi.com$ ./linuxmi.sh
obin-linux_armhf_bin
odist-linux_x64_bin
odist-linux_x64_dist
當你處理一些字符串時,例如文件名、路徑等,你可能需要替換字符串的前綴和后綴。將一個文件擴展名替換為另一個擴展名就是一個很好的例子。看下面的例子:
#!/bin/bash
# Linux迷 www.linuxmi.com
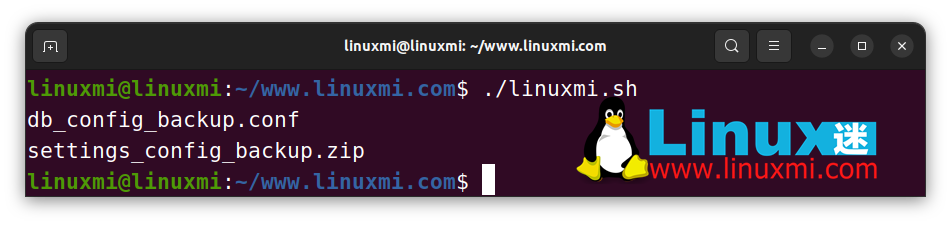
str="db_config_backup.zip"
echo "${str/%.zip/.conf}" # db_config_backup.conf
echo "${str/#db/settings}" # settings_config_backup.zip
在上面的子字符串替換示例中,我們使用了確切的子字符串段進行匹配,但您還可以使用 * 通配符字符來使用子字符串的一部分,如下所示:
#!/bin/bash
str="db_config_backup.zip"
echo "${str/%.*/.bak}" # db_config_backup.conf
echo "${str/#*_/new}" # newbackup.zip
如果您不知道要搜索的確切子字符串,上述方法很有用。
正則表達式匹配、提取和替換
許多 Unix 或 GNU/Linux 用戶已經知道,可以使用 grep 和 sed 進行基于正則表達式的文本搜索。sed 幫助我們進行正則表達式替換。你可以使用內置的 Bash 正則表達式功能來處理文本,比使用這些外部二進制文件更快。
你可以使用 if 條件和 =~ 操作符執行正則表達式匹配,如下面的代碼片段所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
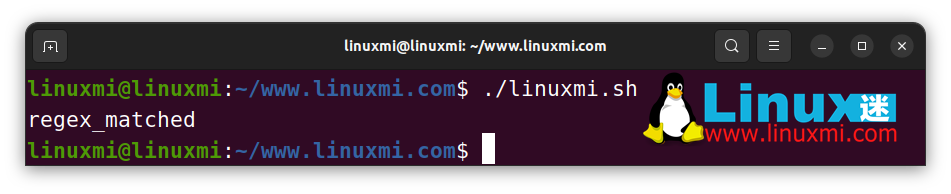
str="db_backup_2003.zip"
if [[ $str =~ 200[0-5]+ ]]; then
echo "regex_matched"
fi
如果你想的話,也可以用內聯條件語句來替換 if 語句,如下所示:
[[ $str =~ 200[0-5]+ ]] && echo "regex_matched"
一旦 Bash 解釋器執行了一個正則表達式匹配,它通常會將所有匹配結果存儲在 BASH_REMATCH shell 變量中。這個變量是一個只讀數組,并將整個匹配的數據存儲在第一個索引中。如果使用子模式,則 Bash 會逐步將這些匹配項存儲在其他索引中:
#!/bin/bash
# Linux迷 www.linuxmi.com
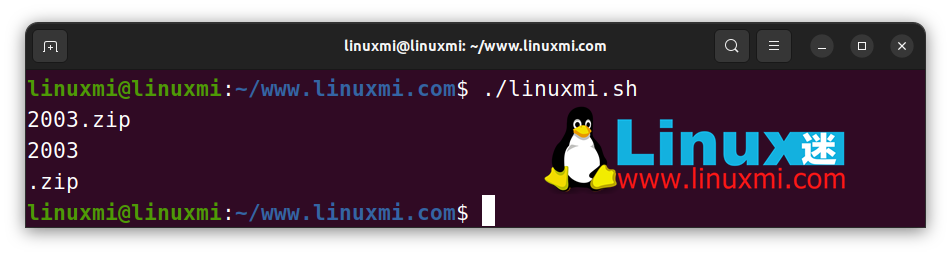
str="db_backup_2003.zip"
if [[ $str =~ (200[0-5])(.*)$ ]]; then
echo "${BASH_REMATCH[0]}" # 2003.zip
echo "${BASH_REMATCH[1]}" # 2003
echo "${BASH_REMATCH[2]}" # .zip
fi
記得我們之前在子字符串匹配中使用了通配符嗎?類似地,可以在參數擴展中使用正則表達式定義,如下面的例子所示:
#!/bin/bash
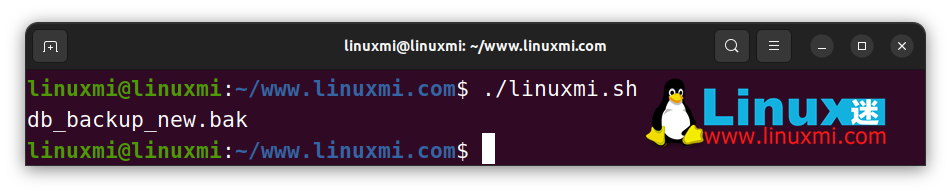
# Linux迷 www.linuxmi.com
str="db_backup_2003.zip"
re="200[0-3].zip"
echo "${str/$re/new}.bak" # db_backup_new.bak
子字符串刪除技巧
我們在許多文本處理需求中經常需要預處理文本段,以刪除不需要的子字符串。例如,如果您提取了一個帶有 v 前綴和一些構建編號的版本號,并想找到主要版本號,則必須刪除一些子字符串。您可以使用相同的子字符串替換語法,但省略替換字符串參數以進行字符串刪除,如下所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
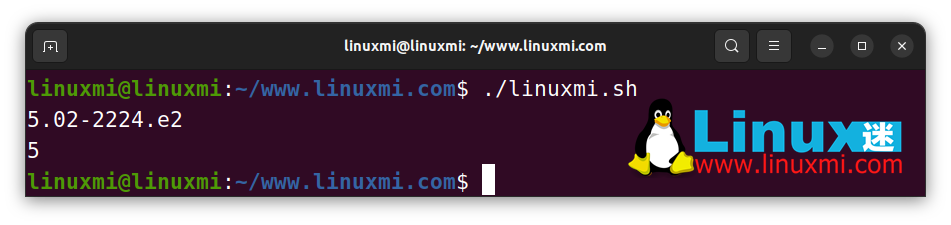
str="ver5.02-2224.e2"
ver="${str#ver}"
echo $ver # 5.02-2224.e2
maj="${ver/.*}"
echo $maj # 5
在上面的示例中,我們使用了精確的子字符串和通配符進行子字符串刪除,但是您還可以使用正則表達式。看看如何提取一個不帶冗余字符的干凈版本號:
#!/bin/bash
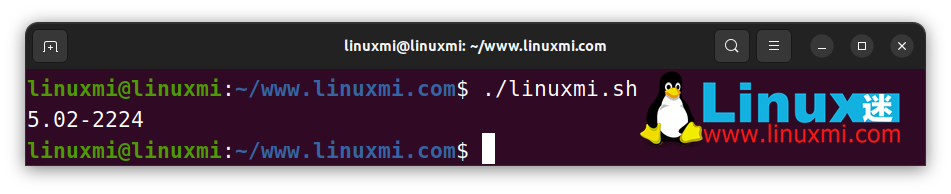
# Linux迷 www.linuxmi.com
str="ver5.02-2224_release"
ver="${str//[a-z_]}"
echo $ver # 5.02-2224
大小寫轉換和基于大小寫的變量
即使是標準的 C 語言也提供了一個函數來轉換字符的大小寫。幾乎所有現代編程語言都提供了內置函數來進行大小寫轉換。作為一種命令語言,Bash 不提供大小寫轉換的函數,但它通過參數擴展和變量聲明為我們提供了大小寫轉換的功能。
請看下面的示例,它將字母的大小寫進行轉換:
#!/bin/bash
# Linux迷 www.linuxmi.com
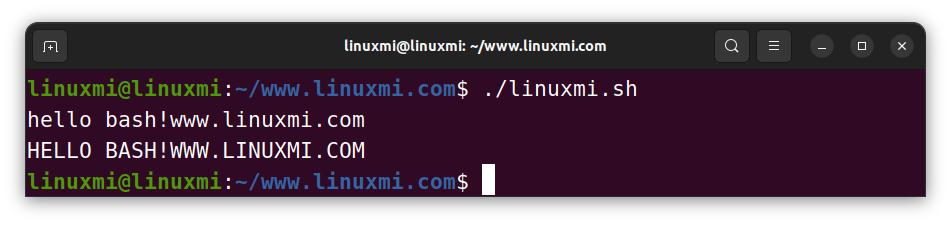
str="Hello Bash!www.linuxmi.com"
lower="${str,,}"
upper="${str^^}"
echo $lower # hello bash!www.linuxmi.com
echo $upper # HELLO BASH!WWW.LINUXMI.COM
你也可以只將字符串的第一個字符大寫或小寫,如下所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
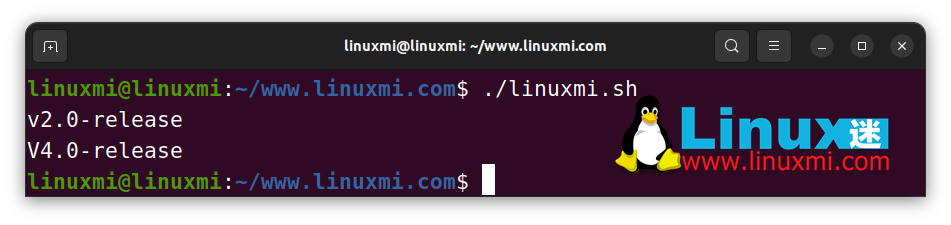
ver1="V2.0-release"
ver2="v4.0-release"
echo "${ver1,}" # v2.0-release
echo "${ver2^}" # V4.0-release
如果您需要使特定變量嚴格大寫或小寫,您不需要每次都運行一個大小寫轉換函數。相反,您可以使用內置的declare命令為特定變量添加大小寫屬性,如下面的示例所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
declare -l ver1
declare -u ver2
ver1="V4.02.2"
ver2="v2.22.1"
echo $ver1 # v4.02.2
echo $ver2 #V2.22.1
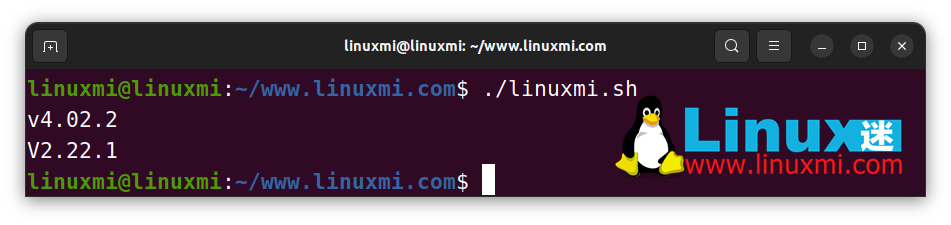
上面的 ver1 和 ver2 變量在聲明時接收到了大小寫屬性,因此每當你為一個特定的變量分配一個值時,Bash 會根據變量屬性轉換文本大小寫。
拆分字符串(字符串到數組的轉換)
Bash 允許你使用 declare 內置函數定義索引和關聯數組。大多數通用編程語言提供了在字符串對象中或通過標準庫函數中拆分方法(例如 Go 的 strings.Split 函數)。在 Bash 中,你可以使用多種方法拆分一個字符串并創建一個數組。例如,我們可以將 IFS 更改為所需的分隔符并使用 read 內置函數,或者我們可以使用 tr 命令和循環構建數組,另外使用內置參數展開也是一種方法。在 Bash 中有很多字符串拆分方法。
使用 IFS 和 read 是最簡單和無誤的拆分字符串的方法之一:
#!/bin/bash
# Linux迷 www.linuxmi.com
str="C,C++,JavaScript,Python,Bash"
IFS=',' read -ra arr <<< "$str"
echo "${#arr[@]}" # 5
echo "${arr[0]}" # C
echo "${arr[4]}" # Bash
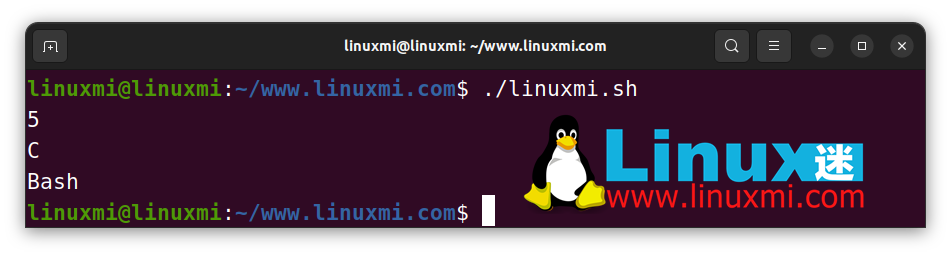
上面的代碼片段使用,作為分隔符,并使用內置的read命令基于IFS創建一個數組。
即使有最簡單的方法可以在不使用read的情況下處理拆分,但要確保沒有隱藏的問題。例如,以下拆分實現非常簡單,但當您將*(擴展為當前目錄的內容)作為元素,空格作為分隔符時,它會出現問題:
#!/bin/bash
# Linux迷 www.linuxmi.com
# 警告:這段代碼有幾個隱藏的問題。
str="C,Bash,*"
arr=(${str//,/ })
echo "${#arr[@]}" # 包含當前目錄內容