













在 Python 中使用正則表達式的九個實例
?每當你遇到文本處理問題時,正則表達式(regex)總是你的好朋友。
?然而,要記住所有復雜的規則是很難的甚至是不可能的。甚至僅僅閱讀語法也是令人不知所措的。
因此,學習正則表達式的優秀方法是通過學習實際示例。
本文將總結日常編程場景中常用的九個正則表達式技巧。閱讀完后,正則表達式對你來說就像喝杯茶一樣簡單。

1.驗證電子郵件地址
檢查電子郵件地址的有效性是正則表達式的經典用例。
下面是一個示例程序:
在這個例子中,我們使用 Python 中的 re 模塊來編譯一個匹配有效電子郵件格式的正則表達式模式。然后,我們使用它的 match() 函數來檢查 email 變量是否與模式匹配。
在模式中,有幾個關鍵點:
- 我們使用 [] 表示一個范圍。例如,[a-zA-Z0-9] 可以匹配 0 到 9 之間的數字、A 到 Z 之間的字母或 a 到 z 之間的字母。
- ^ 表示行的開頭。在我們的例子中,我們使用它來確保文本必須以 [a-zA-Z0-9] 開始。
- $ 表示行的結尾。
- \ 用于轉義特殊字符(允許我們匹配像 ‘.’ 這樣的字符)。
- {n,m} 語法是用來匹配 n-m 個先前的正則表達式。我們使用了 {2,},這意味著前面的部分 [a-zA-Z] 應該至少重復 2 次。這就是為什么 “elon@example.c” 被識別為無效的電子郵件地址。
- ■表示匹配前面的正則表達式至少 1 次。例如,ab+ 將匹配 a 后面的任何非零數量的 b。
這個經典的例子演示了在 Python 中使用正則表達式的一些基本語法。
實際上,Python 的 re 模塊是一個隱藏的寶藏,我們可以從中使用許多更多的技巧。
2.從字符串中提取數字
要從長文本中找到一些特殊字符,最直接的想法是使用 for 循環遍歷所有字符并找到所需的內容。
但是,沒有必要使用任何循環。正則表達式就是為了作為過濾器而生的。
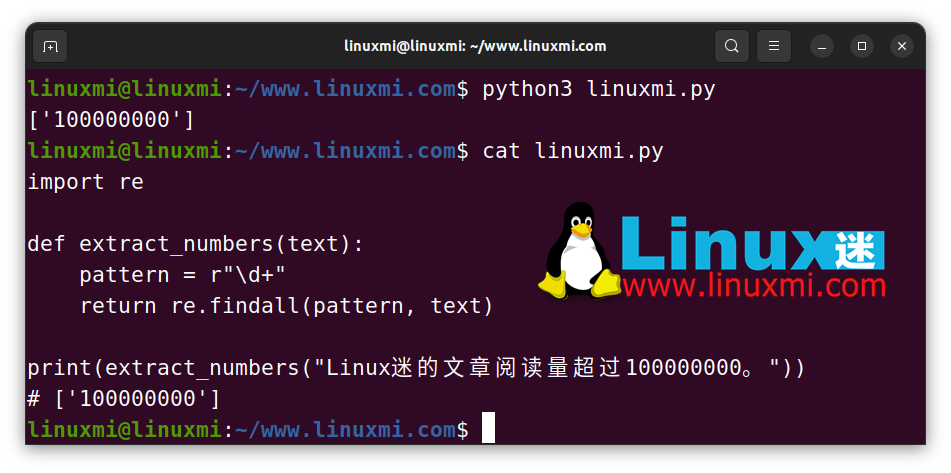
如上所示,re.findall() 函數接收一個正則表達式和一個文本,可以方便地幫助我們找到所有我們需要的字符。
其中 \d 用于在正則表達式中匹配數字。
接下來我們看一個具體例子,演示 \d 的用途。
3.驗證電話號碼
下面的例子利用了 \d 的用法來驗證有效的電話號碼:
除了 \d 外,我們還使用了 ^、$ 和 {n} 語法來確保字符串是一個有效的電話號碼。
4.將文本分割成單詞
將長文本分割成單獨的單詞是日常編程中的另一個常見需求。借助 re 模塊的 split() 函數,我們可以輕松完成此任務:
如上述代碼所示,我們使用 \s 來在正則表達式中匹配一個空格。
5.使用正則表達式查找和替換文本
在使用正則表達式從文本中找到特定字符后,我們可能需要用新的字符串來替換它們。
re 模塊的 sub() 函數可以使這個過程變得非常順暢:
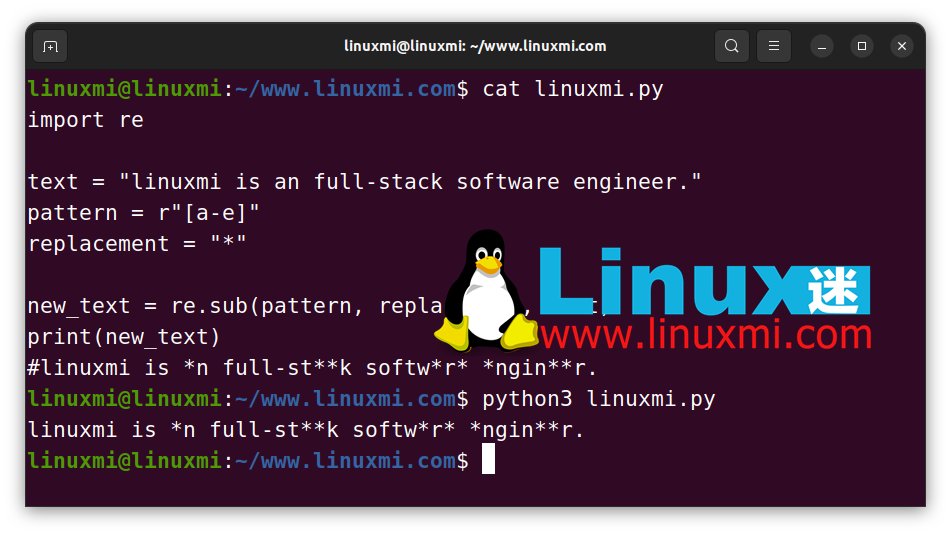
如上所示,我們只需要將三個參數傳遞給sub()函數:模式、替換字符串和原始文本。它將在執行后返回新文本。
6.在Python中預編譯正則表達式
在Python中使用正則表達式匹配字符串時,有兩個步驟:
編譯正則表達式。 使用編譯后的正則表達式匹配字符串。 因此,如果一個正則表達式被重復使用,每次編譯都會浪費時間。
為了避免這種情況,Python允許我們預先編譯一個正則表達式,然后重復使用編譯后的對象進行后續匹配。這可以顯著提高性能和效率。
上面的例子展示了如何使用re模塊中的compile()函數預編譯正則表達式并稍后使用它。只要字符串無法匹配正則表達式,match()函數就會返回None。
7.提取和操作文本的子內容
group()方法是Python re模塊中的一個函數,它返回一個或多個匹配的正則表達式匹配對象的子組。它非常方便,用于提取文本的不同部分。
例如,以下代碼展示了如何從“HH:MM”格式的時間字符串中提取兩個部分:
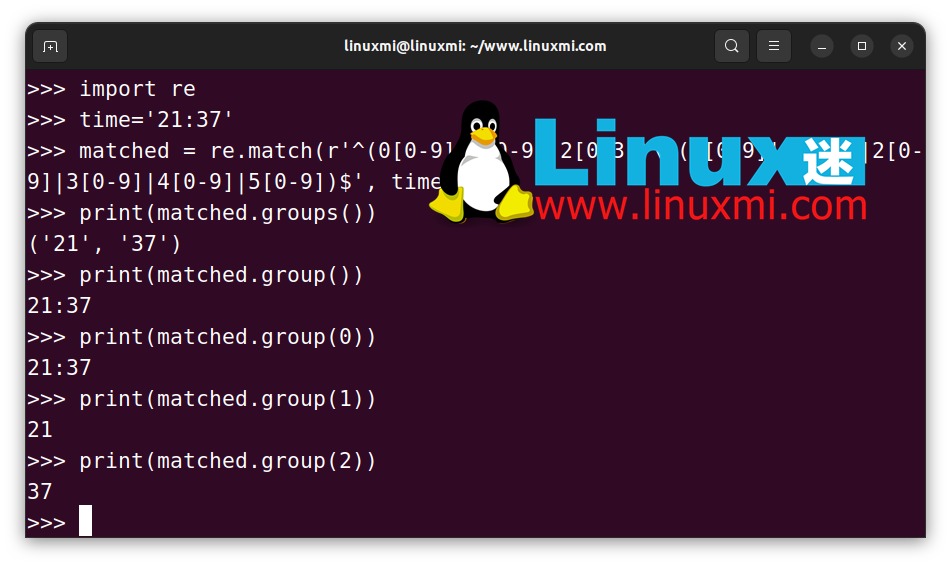
如上所示,group(0) 返回原始字符串。然后,group(1) 和 group(2) 分別返回匹配字符串的第一部分和第二部分。
8.用于提取子內容的命名分組
如果子組數量變得很多,由于太多的神奇數字,程序將很難閱讀。
因此,Python 提供了用于子內容提取的命名組技巧:我們可以使用命名組捕獲匹配字符串的特定部分,而不是使用編號的捕獲組。這可以使我們的代碼更易于閱讀和維護。
以下是一個例子:
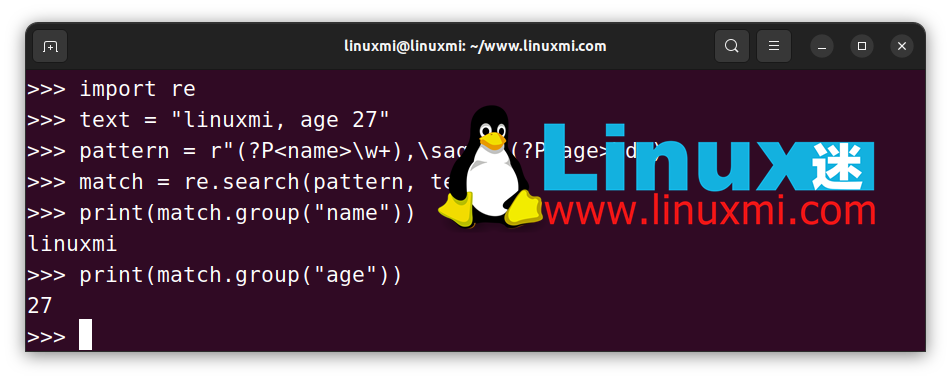
如上所示,命名分組的關鍵語法是 ?P<xxx>。它定義了對應組的名稱,我們可以使用 group() 函數根據名稱提取內容。
9.使用VERBOSE標志使正則表達式易讀
在一些復雜的情況下,正則表達式可能會變得越來越復雜和難以讀取。我們肯定需要一種方法來使其更整潔和干凈。
這就是re.VERBOSE技巧。
如上所示,我們可以將復雜的正則表達式分成多行,以提高可讀性。只要在re.search()函數中加入re.VERBOSE標志,它就可以像平常一樣被正確識別。


















