好的索引當然是要覆蓋了!
如果你的查詢中用到了索引,這是一個進步,如果能夠更進一步,用到了覆蓋索引,那么就更牛了!當我們設計一個索引的時候,如果能夠從一個更加全面的角度去設計這個索引,不僅考慮到 where 中的條件,還能夠考慮到整個 SQL,那么無疑這個索引的設計將是非常成功的。
當然不能為了覆蓋而覆蓋。
1. 什么是覆蓋索引
要理解什么是覆蓋索引,我們需要先來回顧一下 InnoDB 中索引樹的數據結構。
假設我有如下數據:
id(主鍵) | username | age | address | gender |
1 | ab | 99 | 深圳 | 男 |
2 | bw | 95 | 天津 | 男 |
3 | cx | 93 | 深圳 | 男 |
4 | bc | 80 | 上海 | 女 |
5 | bg | 85 | 重慶 | 女 |
6 | ac | 98 | 廣州 | 男 |
7 | bw | 99 | 海口 | 女 |
8 | ck | 90 | 深圳 | 男 |
9 | cc | 92 | 武漢 | 男 |
10 | af | 88 | 北京 | 女 |
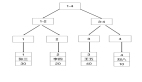
現在我給 username、age 以及 address 三個字段建立一個聯合索引,那么這個聯合索引的 B+Tree 可能是這個樣子:

上面這個索引樹是一個非聚集索引或者也可以說是一個二級索引,這種索引區別于我們之前文章跟大家聊的聚集索引(再聊 MySQL 聚簇索引),在聚集索引中,葉子結點就是這一行的數據,但是在二級索引中,葉子結點中保存的是主鍵值。
所以,當我們搜索的時候,如果使用的是二級索引,那么最終拿到的是主鍵值,有了主鍵值之后,我們還需要再去到聚簇索引中進行搜索,才能拿到完整的數據,這個過程我們也稱之為回表。
很明顯,如果進行了回表操作的話,那么執行效率顯然就要下降一截,那么是否用到了二級索引就會回表呢?其實不然!如果是覆蓋索引的話,就不需要回表。
那么什么是覆蓋索引呢?
小伙伴們觀察上面的索引樹,大家發現在這個索引樹中,離葉子結點最近的樹枝上有 username、age 以及 address,而葉子結點上有 id,所以如果我想要查詢的字段是 id、username、age 以及 address 中的任意一個或者任意幾個的話,那么就不需要再去聚簇索引上查詢了,當前這個 B+Tree 上直接就有現成的,直接返回即可,這個就是覆蓋索引。
2. 實踐
現在假設我有如下一張表:
CREATE TABLE `user` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`age` int DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`gender` varchar(2) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `user_prop_index` (`username`,`age`,`address`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;可以看到,這張表中有一個名為 user_prop_index 的索引,這個索引中一共存在三個字段,分別是 username、age 以及 address,現在我們來看如下 SQL 的執行計劃:
explain select address from user where username='ab' and age=99\G
小伙伴們看到,Extra: Using index 就表示使用到了覆蓋索引,因為我的查詢 SQL 中最終想要的值,都在當前這棵索引樹上。
更進一步,假設我要查詢 id、address 以及 age 字段,如下:
explain select id,address,age from user where username='ab'\G
很明顯,由于這三個字段都在索引樹上,所以直接直接通過回表獲取到。
但是,如果想直接 select *,那么由于這個索引樹上沒有 gender 字段,此時就必須要回表才能拿到 gender 字段的值,如下:
explain select * from user where username='ab'\G
可以看到,這個時候沒有用到覆蓋索引了。
3. 覆蓋索引的優勢
通過前面的介紹,覆蓋索引的優勢相信小伙伴們也能自己總結出來:
- 覆蓋索引不需要回表,直接在 B+Tree 這顆索引樹上就能讀取到需要的數據,這極大的減少了數據庫 IO 次數,在 IO 密集型應用中,這樣的性能提升非常有效。
- 基于 B+Tree 中聯合索引數據的排序規則,覆蓋索引中,如果涉及到范圍搜索,也是非常高效的(如果涉及到回表的話,效率就會降低很多)。