麻了,一個操作把MySQL主從復制整崩了
前言
最近公司某項目上反饋mysql主從復制失敗,被運維部門記了一次大過,影響到了項目的驗收推進,那么究竟是什么原因導致的呢?而主從復制的原理又是什么呢?本文就對排查分析的過程做一個記錄。
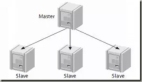
主從復制原理
我們先來簡單了解下MySQL主從復制的原理。

- 主庫master 服務器會將 SQL 記錄通過 dump 線程寫入到 二進制日志binary log 中;
- 從庫slave 服務器開啟一個 io thread 線程向服務器發送請求,向 主庫master 請求 binary log。主庫master 服務器在接收到請求之后,根據偏移量將新的 binary log 發送給 slave 服務器。
- 從庫slave 服務器收到新的 binary log 之后,寫入到自身的 relay log 中,這就是所謂的中繼日志。
- 從庫slave 服務器,單獨開啟一個 sql thread 讀取 relay log 之后,寫入到自身數據中,從而保證主從的數據一致。
以上是MySQL主從復制的簡要原理,更多細節不展開討論了,根據運維反饋,主從復制失敗主要在IO線程獲取二進制日志bin log超時,一看主數據庫的binlog日志竟達到了4個G,正常情況下根據配置應該是不超過300M。

binlog寫入機制
想要了解binlog為什么達到4個G,我們來看下binlog的寫入機制。
binlog的寫入時機也非常簡單,事務執行過程中,先把日志寫到 binlog cache ,事務提交的時候,再把binlog cache寫到binlog文件中。因為一個事務的binlog不能被拆開,無論這個事務多大,也要確保一次性寫入,所以系統會給每個線程分配一個塊內存作為binlog cache。

- 上圖的write,是指把日志寫入到文件系統的page cache,并沒有把數據持久化到磁盤,所以速度比較快
- 上圖的fsync,才是將數據持久化到磁盤的操作, 生成binlog日志中
生產上MySQL中binlog中的配置max_binlog_size為250M, 而max_binlog_size是用來控制單個二進制日志大小,當前日志文件大小超過此變量時,執行切換動作。,該設置并不能嚴格控制Binlog的大小,尤其是binlog比較靠近最大值而又遇到一個比較大事務時,為了保證事務的完整性,可能不做切換日志的動作,只能將該事務的所有$QL都記錄進當前日志,直到事務結束。一般情況下可采取默認值。
所以說懷疑是不是遇到了大事務,因而我們需要看看binlog中的內容具體是哪個事務導致的。
查看binlog日志
我們可以使用mysqlbinlog這個工具來查看下binlog中的內容,具體用法參考官網:https://dev.mysql.com/doc/refman/8.0/en/mysqlbinlog.html。
- 查看binlog日志
./mysqlbinlog --no-defaults --base64-output=decode-rows -vv /mysqldata/mysql/binlog/mysql-bin.004816|more- 以事務為單位統計binlog日志文件中占用的字節大小
./mysqlbinlog --no-defaults --base64-output=decode-rows -vv /mysqldata/mysql/binlog/mysql-bin.004816|grep GTID -B1|grep '^# at' | awk '{print $3}' | awk 'NR==1 {tmp=$1} NR>1 {print ($1-tmp, tmp, $1); tmp=$1}'|sort -n -r|more
生產中某個事務竟然占用4個G。
- 通過start-position和stop-position統計這個事務各個SQL占用字節大小
./mysqlbinlog --no-defaults --base64-output=decode-rows --start-positinotallow='xxxx' --stop-positinotallow='xxxxx' -vv /mysqldata/mysql/binlog/mysql-bin.004816 |grep '^# at'| awk '{print $3}' | awk 'NR==1 {tmp=$1} NR>1 {print ($1-tmp, tmp, $1); tmp=$1}'|sort -n -r|more
發現最大的一個SQL竟然占用了32M的大小,那超過10M的大概有多少個呢?
- 通過超過10M大小的數量
./mysqlbinlog --no-defaults --base64-output=decode-rows --start-positinotallow='xxxx' --stop-positinotallow='xxxxx' -vv /mysqldata/mysql/binlog/mysql-bin.004816|grep '^# at' | awk '{print $3}' | awk 'NR==1 {tmp=$1} NR>1 {print ($1-tmp, tmp, $1); tmp=$1}'|awk '$1>10000000 {print $0}'|wc -l
統計結果顯示竟然有200多個,毛估一下,也有近4個G了
- 根據pos, 我們看下究竟是什么SQL導致的
./mysqlbinlog --no-defaults --base64-output=decode-rows --start-positinotallow='xxxx' --stop-positinotallow='xxxxx' -vv /mysqldata/mysql/binlog/mysql-bin.004816|grep '^# atxxxx' -C5| grep -v '###' | more
根據sql,分析了下,這個表正好有個blob字段,統計了下blob字段總合大概有3個G大小,然后我們業務上有個導入操作,這是一個非常大的事務,會頻繁更新這表中記錄的更新時間,導致生成binlog非常大。
問題: 明明只是簡單的修改更新時間的語句,壓根沒有動blob字段,為什么生產的binlog這么大?因為生產的binlog采用的是row模式。
binlog的模式
binlog日志記錄存在3種模式,而生產使用的是row模式,它最大的特點,是很精確,你更新表中某行的任何一個字段,會記錄下整行的內容,這也就是為什么blob字段都被記錄到binlog中,導致binlog非常大。此外,binlog還有statement和mixed兩種模式。
- STATEMENT模式 ,基于SQL語句的復制
- 優點: 不需要記錄每一行數據的變化,減少binlog日志量,節約IO,提高性能。
- 缺點: 由于只記錄語句,所以,在statement level下 已經發現了有不少情況會造成MySQL的復制出現問題,主要是修改數據的時候使用了某些定的函數或者功能的時候會出現。
- ROW模式,基于行的復制
5.1.5版本的MySQL才開始支持,不記錄每條sql語句的上下文信息,僅記錄哪條數據被修改了,修改成什么樣了。
- 優點: binlog中可以不記錄執行的sql語句的上下文相關的信息,僅僅只需要記錄那一條被修改。所以rowlevel的日志內容會非常清楚的記錄下每一行數據修改的細節。不會出現某些特定的情況下的存儲過程或function,以及trigger的調用和觸發無法被正確復制的問題
- 缺點: 所有的執行的語句當記錄到日志中的時候,都將以每行記錄的修改來記錄,會產生大量的日志內容。
- MIXED模式
從5.1.8版本開始,MySQL提供了Mixed格式,實際上就是Statement與Row的結合。
在Mixed模式下,一般的語句修改使用statment格式保存binlog。如一些函數,statement無法完成主從復制的操作,則采用row格式保存binlog。
總結
最終分析下來,我們定位到原來是由于大事務+blob字段大致binlog非常大,最終我們采用了修改業務代碼,將blob字段單獨拆到一張表中解決。所以,在設計開發過程中,要盡量避免大事務,同時在數據庫建模的時候特別考慮將blob字段獨立成表。