如何將Pandas數據幀加載到QuestDB
譯文譯者 | 李睿
審校 | 重樓
簡介

Pandas是一個開源的Python數據分析和數據操作庫,如今已經成為數據科學家和分析師的必備工具。它提供了一種簡單直觀的數據操作方式,使其成為完成數據分析任務的熱門選擇。
盡管Pandas在中小型數據集方面表現出色,但它可能難以處理超過其所運行機器可用內存的大型數據集。這正是QuestDB的優勢所在,它專門為此類場景中的高性能操作而設計,使其成為高要求數據分析任務的首選解決方案。
通過將Pandas DataFrames加載到QuestDB中,可以利用數據庫強大的數據處理功能,使用戶能夠將分析和數據操作擴展到大型數據集。以下將學習如何將大型Pandas數據幀加載到QuestDB中,并使用紐約市出租車和豪華轎車委員會發布的黃色和綠色出租車行程記錄作為數據來源。
先決條件
對于本文中的教程,建議用戶對Python和SQL有基本的了解。此外,還需要在其機器上安裝以下軟件:
- Docker
獲取數據
在開始將數據加載到QuestDB之前,需要獲取將要使用的數據。如上所述,將使用紐約市出租車和豪華轎車委員會的黃色和綠色出租車行程記錄,并下載數據:
- 首先創建一個名為pandas-to-questdb的新目錄,并在其中創建一個data目錄。
- 在終端中編輯并執行以下命令下載Parquet文件:
Shell
curl -L -o ./data/yellow_tripdata_2022-<MONTH>.parquet https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tr需要確保將<MONTH>替換成為要下載的月份的零前綴數字(在01和11之間,在撰寫本文時第12個月是不可用的)。
有了要獲取的數據,那么現在是嘗試使用Pandas加載它的時候了。
將記錄加載到內存中
人們可能已經注意到下載的文件是Parquet格式的,Parquet是一種用于大數據處理的柱狀存儲格式。與CSV和JSON等傳統的基于行的存儲格式相比,它們經過優化,可與現代大數據處理引擎一起使用,并提供高效的數據存儲和檢索。
在能夠加載任何數據之前,將設置一個模擬生產環境,在那里可以輕松地測試如果Pandas不能將Parquet文件加載到內存中會發生什么情況。在生產過程中,用戶經常遇到必須處理內存約束的情況,這個環境可以反映這一點。
運行以下命令創建一個新的Docker容器,其內存限制為1GB。如果容器達到了這個限制,Docker會終止它,或者操作系統會內存溢出(OOM)終止正在運行的進程:
Shell
docker run -it -m 1g -v "$(pwd)":/tutorial -w /tutorial --net host python:3.11.1-slim-bullseye /bin/bash現在,有了一個基于Ubuntu的Python 3.11 Docker容器。用戶可以根據自己的需求安裝,創建一個包含以下內容的requirements.txt文件:
Plain Text
pandas>=1.5.3
psycopg[binary]>=3.1.8
pyarrow>=11.0.0
questdb>=1.1.0現在,在容器內執行pip install -r requirements.txt。Pip將安裝Python需求。
至此,有了一個可以加載數據的測試環境。創建一個名為data_loader.py的新文件,其中包含以下內容:
Python
# data_loader.py
import pandas as pd
df = pd.read_parquet("./data/yellow_tripdata_2022-01.parquet")
print(df.head())
現在,在Docker容器中運行python data_loader.py來執行它。程序成功運行,可以看到以下內容:
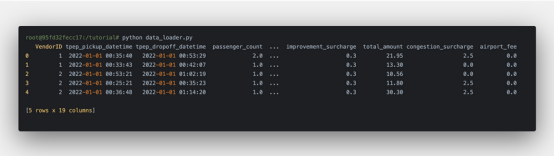
在這里載入了2022年1月的出租車行程記錄!可以嘗試加載更多的數據。將data_loader.py的內容替換為以下代碼,從data目錄加載所有文件,并再次執行該程序:
Python
# data_loader.py
import os
import glob
import pandas as pd
records = glob.glob(os.path.join("data", "*.parquet"))
df = pd.concat((pd.read_parquet(r) for r in records), ignore_index=True)
print(df.head())在執行data_loader.py時,應該得到一條錯誤消息:“已經終止”。正如人們可能認為的那樣,內存溢出(OOM)殺手終止了該過程。并且無法加載數據集,因此不能這樣做,而是需要一種不同的方法。
將數據攝取到QuestDB
在一個新的終端窗口中,通過執行以下操作啟動QuestDB容器:
Shell
docker run --rm -it -p 8812:8812 -p 9009:9009 --net host --name questdb questdb/questdb數據庫現在可以接收數據了。更新data_loader.py以使用QuestDB包將數據攝取到QuestDB中,該包使用TCP上的InfluxDB Line Protocol (ILP)以獲得最大吞吐量。
為了處理大型數據集,將逐個讀取文件并將其內容傳輸到QuestDB。然后,將使用QuestDB來查詢數據,并將結果加載回Pandas DataFrames中。基于以上重構數據加載器:
Python
# data_loader.py
import os
import glob
import pandas as pd
from questdb.ingress import Sender
def main():
files = glob.glob(os.path.join("data", "*.parquet"))
with Sender("127.0.0.1", 9009) as sender:
for file in files:
df = pd.read_parquet(file)
print(f"ingesting {len(df.index)} rows from {file}")
sender.dataframe(df, table_name="trips", at="tpep_pickup_datetime")
if __name__ == "__main__":
main()讓我們從頭開始。注意到的第一個主要變化是,需要在腳本中指定主機名和端口號才能運行它。
然后遍歷Parquet文件,并使用Pandas將它們加載到內存中。之后,利用QuestDB的Python客戶端,將直接從Pandas DataFrames攝取到QuestDB。
在Python容器中,運行Python data_loader.py。腳本每次攝取一個Parquet文件。
使用行程數據
到目前為止,已經準備好了數據集并將其加載到QuestDB中。現在是執行一些查詢并將結果加載到DataFrames中的時候了。使用整個數據集,希望知道按乘客分組的乘客的平均總支付金額是多少。
創建一個名為query_amount.py的新文件,包含以下內容:
Python
# query_amount.py
import pandas as pd
import psycopg
QUERY = """
SELECT passenger_count, avg(total_amount)
FROM 'trips'
WHERE passenger_count > 0
GROUP BY passenger_count
"""
if __name__ == "__main__":
conn = psycopg.connect(
dbname="questdb",
host="127.0.0.1",
user="admin",
password="quest",
port=8812,
)
df = pd.read_sql_query(QUERY, conn)
print(df.head(10))與數據加載器腳本類似,該腳本需要主機和端口。在上面的腳本中,使用了PostgreSQL Python客戶端并使用它連接到QuestDB。在Python容器中,執行Python query_amount.py:
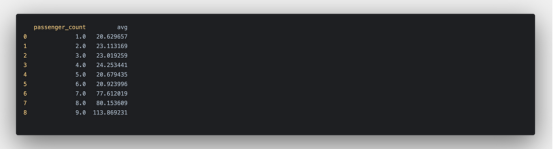
在完成腳本之后,應該看到乘客支付的平均總金額。有趣的是,6名乘客和7名乘客的平均金額相差很大,7名乘客的平均金額幾乎是6名乘客的2.5倍。
通過進一步分析數據,可能會發現這一根本原因,這可能與人類的本性有關:這是因為對于路程更長的旅行,人們通常會分擔乘車費用。
結語
在本文中,學習了如何使用Pandas DataFrames將大型數據集加載到QuestDB中。通過將數據從Pandas傳輸到QuestDB,利用了數據庫強大的數據處理能力,使用戶能夠擴展分析和數據操作,以處理大型數據集。
本文的教程中概述的方法只是使用Pandas和QuestDB處理大數據的一種方法。用戶可以自定義這一方法以滿足其特定需求,并繼續探索這些強大工具的可能性。最終目標是使數據分析和操作更容易和更有效,而不管數據集的大小。
原文標題:Loading Pandas DataFrames Into QuestDB,作者:Gabor Boros