Kafka消費者那些事兒
前言
消息的消費一般有兩種模式,推模式和拉模式。推模式是服務端主動將消息推送給消費者,而拉模式是消費者主動向服務端發起請求來拉取消息。kakfa采用的是拉模式,這樣可以很好的控制消費速率。那么kafka消費的具體工作流程是什么樣的呢?kafka的位移管理又是怎么樣的呢?
消費者消費規則
kafka是以消費者組進行消費,一個消費者組,由多個consumer組成,他們和topic的消費規則如下:

- topic的一個分區只能被消費組中的一個消費者消費。
- 消費者組中的一個消費者可以消費topic一個或者多個分區。
通過這種分組、分區的消費方式,可以提高消費者的吞吐量,同時也能夠實現消息的發布/訂閱模式和點對點兩種模式。
消費者整體工作流程
消費者消費總體分為兩個步驟,第一步是制定消費的方案,就是這個組下哪個消費者消費哪個分區,第二個是建立網絡連接,獲取消息數據。
一、制定消費方案

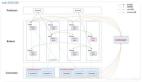
- 消費者consumerA,consumerB, consumerC向kafka集群中的協調器coordinator發送JoinGroup的請求。coordinator主要是用來輔助實現消費者組的初始化和分區的分配。
- coordinator老大節點選擇 = groupid的hashcode值 % 50( __consumer_offsets內置主題位移的分區數量)例如: groupid的hashcode值 為1,1% 50 = 1,那么__consumer_offsets 主題的1號分區,在哪個broker上,就選擇這個節點的coordinator作為這個消費者組的老大。消費者組下的所有的消費者提交offset的時候就往這個分區去提交offset。
- 選出一個 consumer作為消費中的leader,比如上圖中的consumerB。
- 消費者leader制定出消費方案,比如誰來消費哪個分區等,有Range分區策略、RoundRobin分區策略等。
- 把消費方案告訴給coordinator
- 最后coordinator就把消費方案下發給各個consumer, 圖中只畫了一條線,實際上是會下發到各個consumer。
二、消費者消費細節
現在已經初始化消費者組信息,知道哪個消費者消費哪個分區,接著我們來看看消費者細節。

- 消費者創建一個網絡連接客戶端ConsumerNetworkClient, 發送消費請求,可以進行如下配置:
- fetch.min.bytes: 每批次最小抓取大小,默認1字節
- fetch.max.bytes: 每批次最大抓取大小,默認50M
- fetch.max.wait.ms:最大超時時間,默認500ms
- 發送請求到kafka集群
- 獲取數據成功,會將數據保存到completedFetches隊列中
- 消費者從隊列中抓取數據,根據配置max.poll.records一次拉取數據返回消息的最大條數,默認500條。
- 獲取到數據后,經過反序列化器、攔截器后,得到最終的消息。
- 最后一步是提交保存消費的位移offset,也就是這個消費者消費到什么位置了,這樣下次重啟也可以繼續從這個位置開始消費,關于offset的管理后面詳細介紹。
消費者分區策略
前面簡單提到了消費者組初始化的時候會對分區進行分配,那么具體的分配策略是什么呢,也就是哪個消費者消費哪個分區數據?
kafka有四種主流的分區分配策略: Range、RoundRobin、Sticky、CooperativeSticky。可以通過配置參數partition.assignment.strategy,修改分區的分配策略。默認策略是Range + CooperativeSticky。Kafka可以同時使用多個分區分配策略。
Range 分區策略

- Range分區 是對每個 topic 而言的。對同一個 topic 里面的分區按照序號進行排序,并對消費者按照字母順序進行排序。
- 通過 partitions數/consumer數 來決定每個消費者應該消費幾個分區。如果除不盡,那么前面幾個消費者將會多消費 1 個分區。
如上圖所示:有 7 個分區,3 個消費者,排序后的分區將會是0,1,2,3,4,5,6;消費者排序完之后將會是C0,C1,C2。7/3 = 2 余 1 ,除不盡,那么 消費者 C0 便會多消費 1 個分區。 8/3=2余2,除不盡,那么C0和C1分別多消費一個。
這種方式容易造成數據傾斜!如果有 N 多個 topic,那么針對每個 topic,消費者 C0都將多消費 1 個分區,topic越多,C0消費的分區會比其他消費者明顯多消費 N 個分區。
RoundRobin 分區策略
RoundRobin 針對集群中所有topic而言,RoundRobin 輪詢分區策略,是把所有的 partition 和所有的consumer 都列出來,然后按照 hashcode 進行排序,最后通過輪詢算法來分配 partition 給到各個消費者。

Sticky 和Cooperative Sticky分區策略
Sticky是粘性的意思,它是從 0.11.x 版本開始引入這種分配策略,首先會盡量均衡的放置分區到消費者上面,在出現同一消費者組內消費者出現問題的時候,在rebalance會盡量保持原有分配的分區不變化,這樣可以節省開銷。
Cooperative Sticky和Sticky類似,但是它會將原來的一次大規模rebalance操作,拆分成了多次小規模的rebalance,直至最終平衡完成,所以體驗上會更好。
關于什么是rebalance繼續往下看你就知道了。
消費者再均衡
上面也提到了rebalance,也就是再均衡。當kafka發生下面的情況會進行在均衡,也就是重新給消費者分配分區:
- 有新的消費者加入消費組。 ?
- 有消費者宕機下線,消費者并不一定需要真正下線,例如遇到長時間的 GC 、網絡延遲導致消費者長時間未向Group Coordinator發送心跳等情況時,GroupCoordinator 會認為消費者己下線。 ?
- 有消費者主動退出消費組。
- 消費組所對應的Group Coorinator節點發生了變更。 ?
- 消費組內所訂閱的任一主題或者主題的分區數量發生變化。
消費者位移offset管理
消費者需要保存當前消費到分區的什么位置了,這樣哪怕消費者故障,重啟后也能繼續消費,這就是消費者的維護offset管理。
一、消費者位移offset存儲位置
消費者位移offset存儲在哪呢?
- kafka0.9版本之前,consumer默認將offset保存在Zookeeper中
- 從0.9版本開始,consumer默認將offset保存在Kafka一個內置的topic中,該topic為__consumer_offsets,這樣可以大量減少和zookeeper的交互。
- __consumer_offsets 主題里面采用 key 和 value 的方式存儲數據。key 是 group.id+topic+分區號,value 就是當前 offset 的值。
如何查看__consumer_offsets主題內容?
- 在配置文件 config/consumer.properties 中添加配置 exclude.internal.topics=false,默認是 true,表示不能消費系統主題。為了查看該系統主題數據,所以該參數修改為 false。
- 查看消費者消費主題__consumer_offsets。
bin/kafka-console-consumer.sh --topic
__consumer_offsets --bootstrap-server hadoop102:9092 --
consumer.config config/consumer.properties --formatter
"kafka.coordinator.group.GroupMetadataManager$OffsetsMessageForm
atter" --from-beginning
## topic1 1號分區
[offset,topic1,1]::OffsetAndMetadata(offset=7,
leaderEpoch=Optional[0], metadata=, commitTimestamp=1622442520203,
expireTimestamp=None)
## topic1 0號分區
[offset,topic1,0]::OffsetAndMetadata(offset=8,
leaderEpoch=Optional[0], metadata=, commitTimestamp=1622442520203,
expireTimestamp=None)二、消費者位移offset提交保存模式
消費者是如何提交保存位移offset呢?
自動提交
為了使我們能夠專注于自己的業務邏輯,kafka默認提供了自動提交offset的功能。這個由消費者客戶端參數 enable.auto.commit 配置, 默認值為 true 。當然這個默認的自動提交不是每消費一條消息就提交一次,而是定期提交,這個定期的周期時間由客戶端參數 auto.commit.interval.ms 配置,默認值為 5 秒。

- 消費者每隔 5 秒會將拉取到的每個分區中最大的消息位移進行提交。
- 自動位移提交 的動作是在 poll() 方法的邏輯里完成的,在每次真正向服務端發起拉取請求之前會檢查是否可以進行位移提交,如果可以,那么就會提交上一次輪詢的位移。
自動提交會帶來什么問題?
自動提交消費位移的方式非常簡便,但會帶來是重復消費的問題。

假設剛剛提交完一次消費位移,然后拉取一批消息進行消費,在下一次自動提交消費位移之前,消費者崩潰了,那么又得從上一次位移提交的地方重新開始消費,這樣便發生了重復消費的現象。
我們可以通過減小位移提交的時間間隔來減小重復消息的窗口大小,但這樣 并不能避免重復消費的發送,而且也會使位移提交更加頻繁。
手動提交
很多時候并不是說拉取到消息就算消費完成,而是需要將消息寫入數據庫、寫入本地緩存,或者是更 加復雜的業務處理。在這些場景下,所有的業務處理完成才能認為消息被成功消費。手動的提交方式可以讓開發人員根據程序的邏輯在合適的地方進行位移提交。
// 是否自動提交 offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);手動提交可以細分為同步提交和異步提交,對應于 KafkaConsumer 中的 commitSync()和 commitAsync()兩種類型的方法。
- 同步提交方式
同步提交會阻塞當前線程,一直到提交成功,并且會自動失敗重試(由不可控因素導致,也會出現提交失敗),它必須等待offset提交完畢,再去消費下一批數據。
// 同步提交 offset
consumer.commitSync();- 異步提交方式
異步提交則沒有失敗重試機制,故有可能提交失敗。它發送完提交offset請求后,就開始消費下一批數據了。
// 異步提交 offset
consumer.commitAsync();那么手動提交會帶來什么問題呢?可能會出現"漏消息"的情況。

設置offset為手動提交,當offset被提交時,數據還在內存中未落盤,此時剛好消費者線程被kill掉,那么offset已經提交,但是數據未處理,導致這部分內存中的數據丟失。
我們可以通過消費者事物來解決這樣的問題。
其實無論是手動提交還是自動提交,都有可能出現消息重復和是漏消息,與我們的編程模型有關,需要我們開發的時候根據消息的重要程度來選擇合適的消費方案。
消費者API
一個正常的消費邏輯需要具備以下幾個步驟:
(1)配置消費者客戶端參數及創建相應的消費者實例;
(2)訂閱主題;
(3)拉取消息并消費;
(4)提交消費位移 offset;
(5)關閉消費者實例。
public class MyConsumer {
public static void main(String[] args) {
Properties props = new Properties();
// 定義 kakfa 服務的地址,不需要將所有 broker 指定上
props.put("bootstrap.servers", "doitedu01:9092");
// 制定 consumer group
props.put("group.id", "g1");
// 是否自動提交 offset
props.put("enable.auto.commit", "true");
// 自動提交 offset 的時間間隔
props.put("auto.commit.interval.ms", "1000");
// key 的反序列化類
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// value 的反序列化類
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 如果沒有消費偏移量記錄,則自動重設為起始 offset:latest, earliest, none
props.put("auto.offset.reset","earliest");
// 定義 consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消費者訂閱的 topic, 可同時訂閱多個
consumer.subscribe(Arrays.asList("first", "test","test1"));
while (true) {
// 讀取數據,讀取超時時間為 100ms
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}訂閱主題
- 指定集合方式訂閱主題
consumer.subscribe(Arrays.asList(topicl ));
consumer subscribe(Arrays.asList(topic2))- 正則方式訂閱主題
如果消費者采用的是正則表達式的方式(subscribe(Pattern))訂閱, 在之后的過程中,如果 有人又創建了新的主題,并且主題名字與正表達式相匹配,那么這個消費者就可以消費到 新添加的主題中的消息。
consumer.subscribe(Pattern.compile ("topic.*" ));- 訂閱主題指定分區
消費者不僅可以通過 KafkaConsumer.subscribe()方法訂閱主題,還可直接訂閱某些主題的指定分區。
consumer.assign(Arrays.asList(new TopicPartition ("tpc_1" , 0),new TopicPartition(“tpc_2”,1))) ;取消訂閱
通過unsubscribe()方法采取消主題的訂閱。
consumer.unsubscribe();poll()拉取消息
kafka 中的消息消費是一個不斷輪詢的過程,消費者所要做的就是重復地調用 poll() 方法, poll()方法返回的是所訂閱的主題(分區)上的一組消息。
對于 poll () 方法而言,如果某些分區中沒有可供消費的消息,那么此分區對應的消息拉取的結果就為空。
public ConsumerRecords<K, V> poll(final Duration timeout)超時時間參數 timeout ,用來控制 poll() 方法的阻塞時間,在消費者的緩沖區里沒有可用數據時會發生阻塞。
指定位移消費
有些時候,我們需要一種更細粒度的掌控,可以讓我們從特定的位移處開始拉取消息,而 KafkaConsumer 中的 seek( 方法正好提供了這個功能,讓我們可以追前消費或回溯消費。
public void seek(TopicPartiton partition,long offset)消費者重要參數
最后我們總結一下消費者中重要的參數配置。
參數名稱 | 描述 |
bootstrap.servers | 向 Kafka 集群建立初始連接用到的 host/port 列表。 |
key.deserializer 和value.deserializer | 指定接收消息的 key 和 value 的反序列化類型。一定要寫全類名。 |
group.id | 標記消費者所屬的消費者組。 |
enable.auto.commit | 默認值為 true,消費者會自動周期性地向服務器提交偏移量。 |
auto.commit.interval.ms | 如果設置了 enable.auto.commit 的值為 true, 則該值定義了消費者偏移量向 Kafka 提交的頻率,默認 5s。 |
auto.offset.reset | 當 Kafka 中沒有初始偏移量或當前偏移量在服務器中不存在(如,數據被刪除了),該如何處理? earliest:自動重置偏移量到最早的偏移量。 latest:默認,自動重置偏移量為最新的偏移量。 none:如果消費組原來的(previous)偏移量不存在,則向消費者拋異常。 anything:向消費者拋異常。 |
offsets.topic.num.partitions | __consumer_offsets 的分區數,默認是 50 個分區。 |
heartbeat.interval.ms | Kafka 消費者和 coordinator 之間的心跳時間,默認 3s。該條目的值必須小于 session.timeout.ms ,也不應該高于session.timeout.ms 的 1/3。 |
session.timeout.ms | Kafka 消費者和 coordinator 之間連接超時時間,默認 45s。超過該值,該消費者被移除,消費者組執行再平衡。 |
max.poll.interval.ms | 消費者處理消息的最大時長,默認是 5 分鐘。超過該值,該消費者被移除,消費者組執行再平衡。 |
fetch.min.bytes | 默認 1 個字節。消費者獲取服務器端一批消息最小的字節數。 |
fetch.max.wait.ms | 默認 500ms。如果沒有從服務器端獲取到一批數據的最小字節數。該時間到,仍然會返回數據。 |
fetch.max.bytes | 默認 Default: 52428800(50 m)。消費者獲取服務器端一批消息最大的字節數。如果服務器端一批次的數據大于該值(50m)仍然可以拉取回來這批數據,因此,這不是一個絕對最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影響。 |
max.poll.records | 一次 poll 拉取數據返回消息的最大條數,默認是 500 條。 |
總結
kafka消費是很重要的一個環節,本文總結kafka消費者的一些重要機制,包括消費者的整個流程,消費的分區策略,消費的再平衡以及消費的位移管理。在明白這些機制以后,簡單講解了如何使用消費者consumer的API以及消費者中重要的參數。