













面試官問:Kafka為什么如此之快?
前言
天下武功,唯快不破。同樣的,kafka在消息隊列領域,也是非常快的,這里的塊指的是kafka在單位時間搬運的數據量大小,也就是吞吐量,下圖是搬運網上的一個性能測試結果,在同步發送場景下,單機Kafka的吞吐量高達17.3w/s,不愧是高吞吐量消息中間件的行業老大。
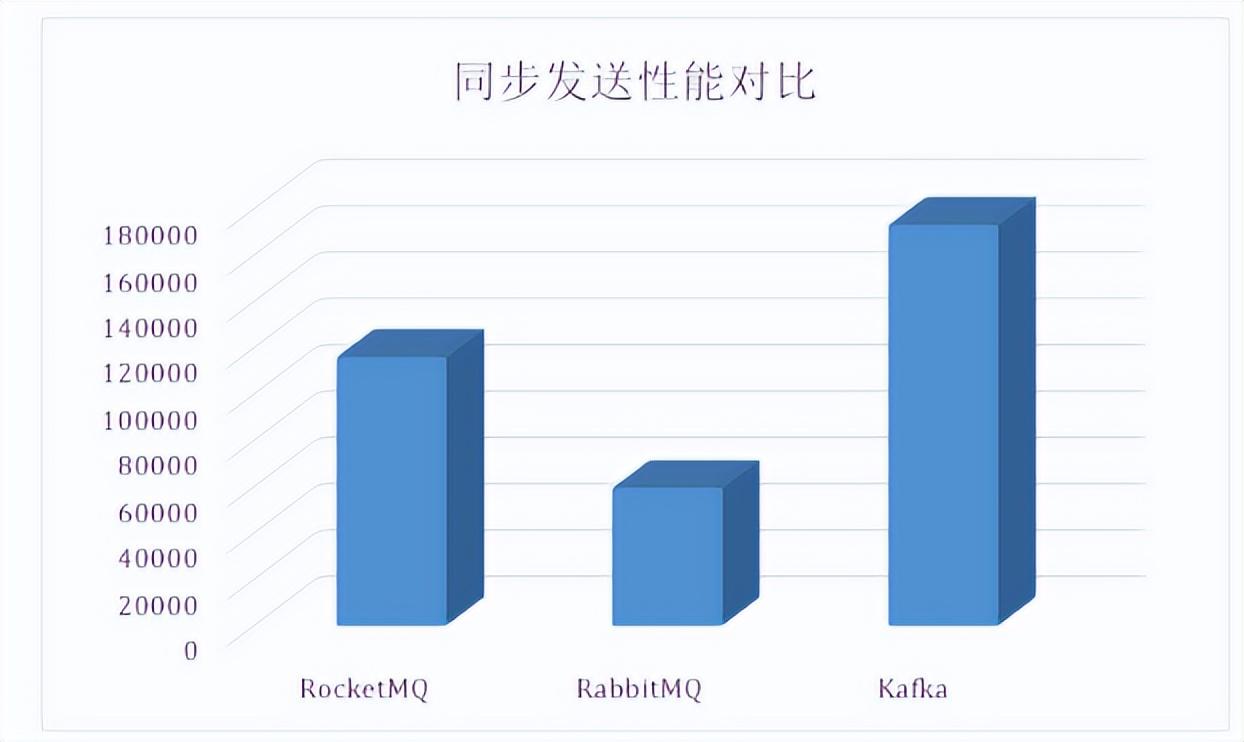
那究竟是什么原因讓kafka如此之快呢?這也是面試官非常喜歡問的問題。
四個原因
原因一:磁盤順序讀寫
生產者發送數據到kafka集群中,最終會寫入到磁盤中,會采用順序寫入的方式。消費者從kafka集群中獲取數據時,也是采用順序讀的方式。
無論是機械磁盤還是固態硬盤SSD,順序讀寫的速度都是遠大于隨機讀寫的。因為對于機械磁盤順序讀寫省去了磁頭頻繁尋址和旋轉盤片的開銷。而固態硬盤就更加復雜,這里不展開闡述。
下圖是網上關于讀寫方式的性能比較。
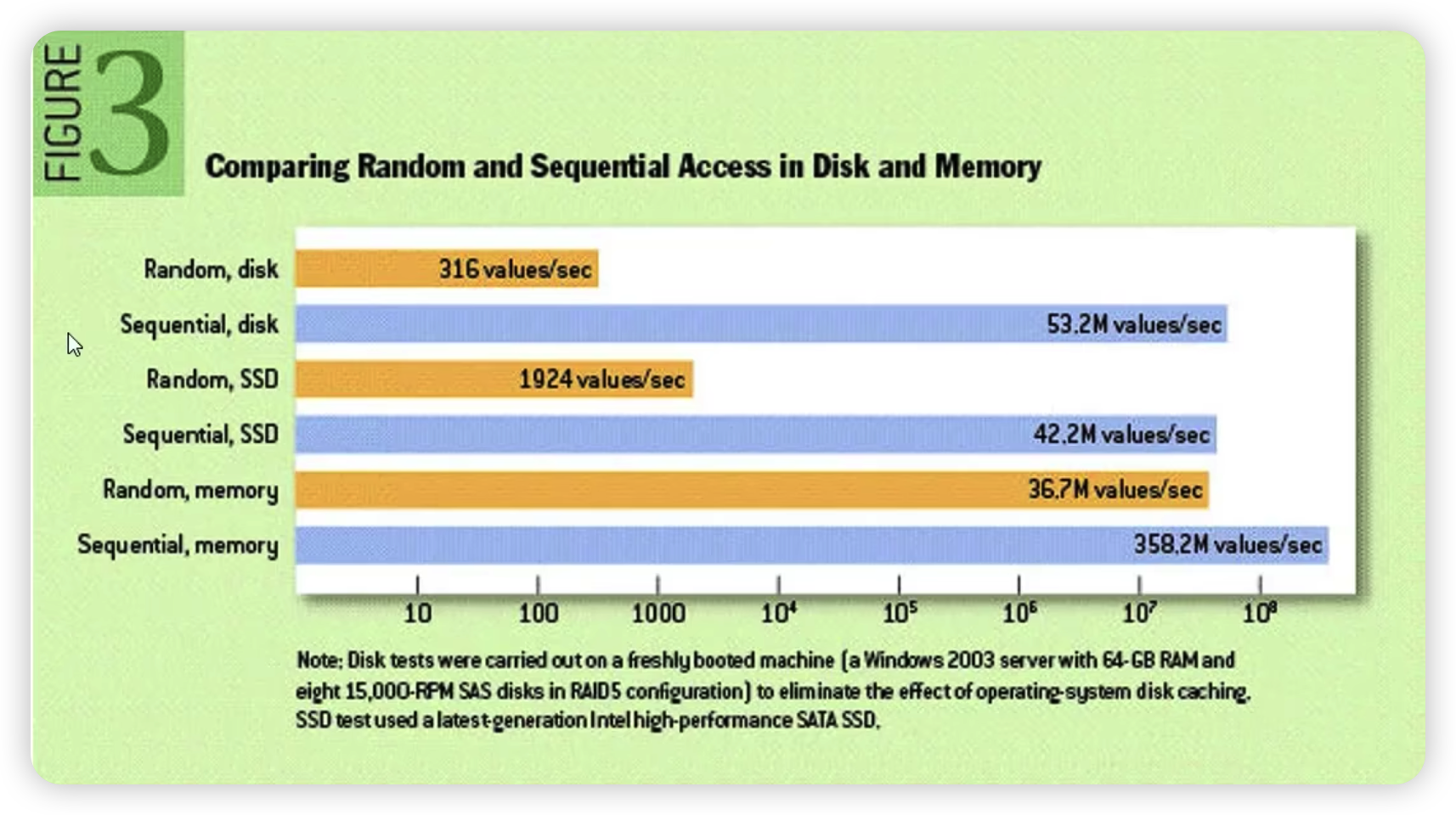
- 機械磁盤順序讀寫 53M/s,隨讀寫 316k/s
- 固態硬盤順序讀寫 42M/s, 隨機讀寫 1000k/s
因而,由于kafka一般使用機械磁盤存儲消息,因為機械磁盤的價格遠小于固態硬盤SSD。
原因二:PageCache頁緩存技術
前面提到了kafka采用順序讀寫寫入到磁盤中,難道是直接kafka到磁盤嗎,實際上不是的,中間多了一道操作系統的PageCache頁緩存,可以理解為內存。
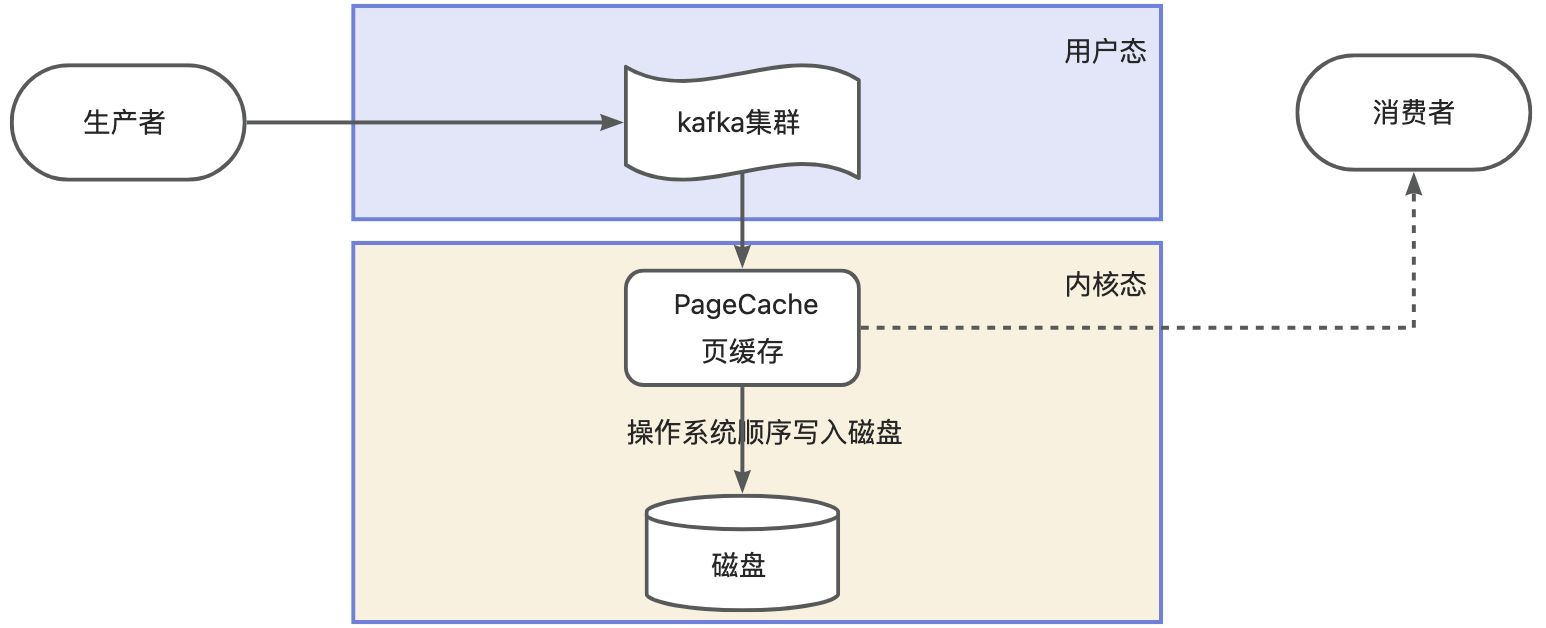
- 當kafka有寫操作時,先將數據寫入PageCache中,然后在定時方式順序寫入到磁盤中。
- 當讀操作發生時,先從PageCache中查找,如果找不到,再去磁盤中讀取。
通過頁緩存技術,更近一步的提高了讀寫的性能。
原因三:零拷貝技術
kafka之所以快的另外一個原因是采用了零拷貝技術。
首先我們來看下從磁盤讀取數據到網卡場景下,傳統IO的整個過程,如下圖所示:
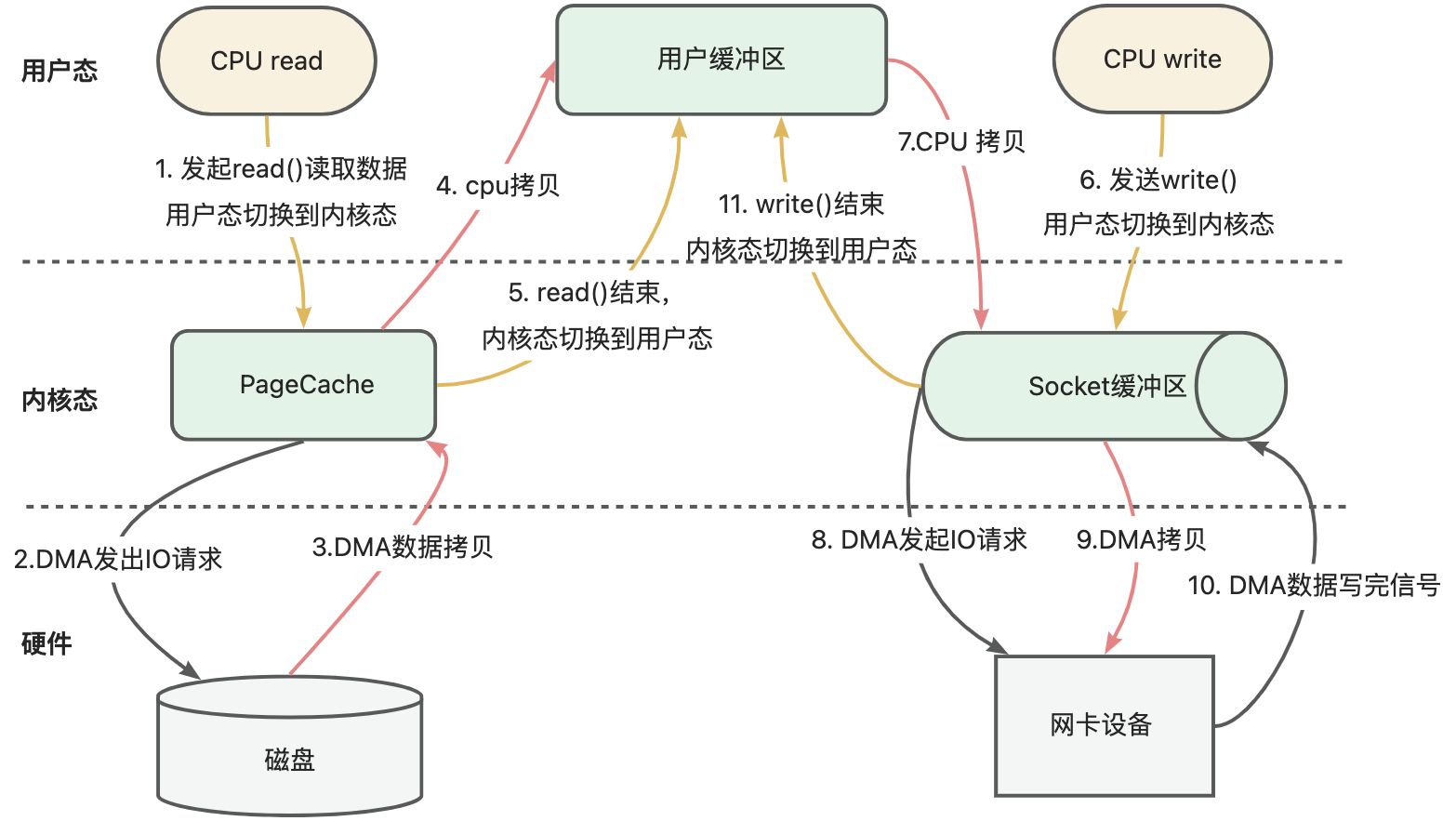
傳統IO模型下,從磁盤讀取數據,寫到網卡設備中,經歷了4次用戶態和內核態之間的切換,以及4次數據的拷貝,包括CPU拷貝和DMA拷貝。這些操作都是十分損耗性能。
DMA, Direct Memory Access, 直接內存訪問是一些計算機總線架構提供的功能,它能使數據從附加設備(如磁盤驅動器)直接發送到計算機主板的內存上。
那能否減少這樣的切換和拷貝呢?答案是肯定的,不知道大家發下沒有,kafka的消息在應用層做任何轉換,怎么存就怎么取,你看連序列化、反序列化都是在生產者和消費者做的。所以kafka采用了sendfile的零拷貝技術。
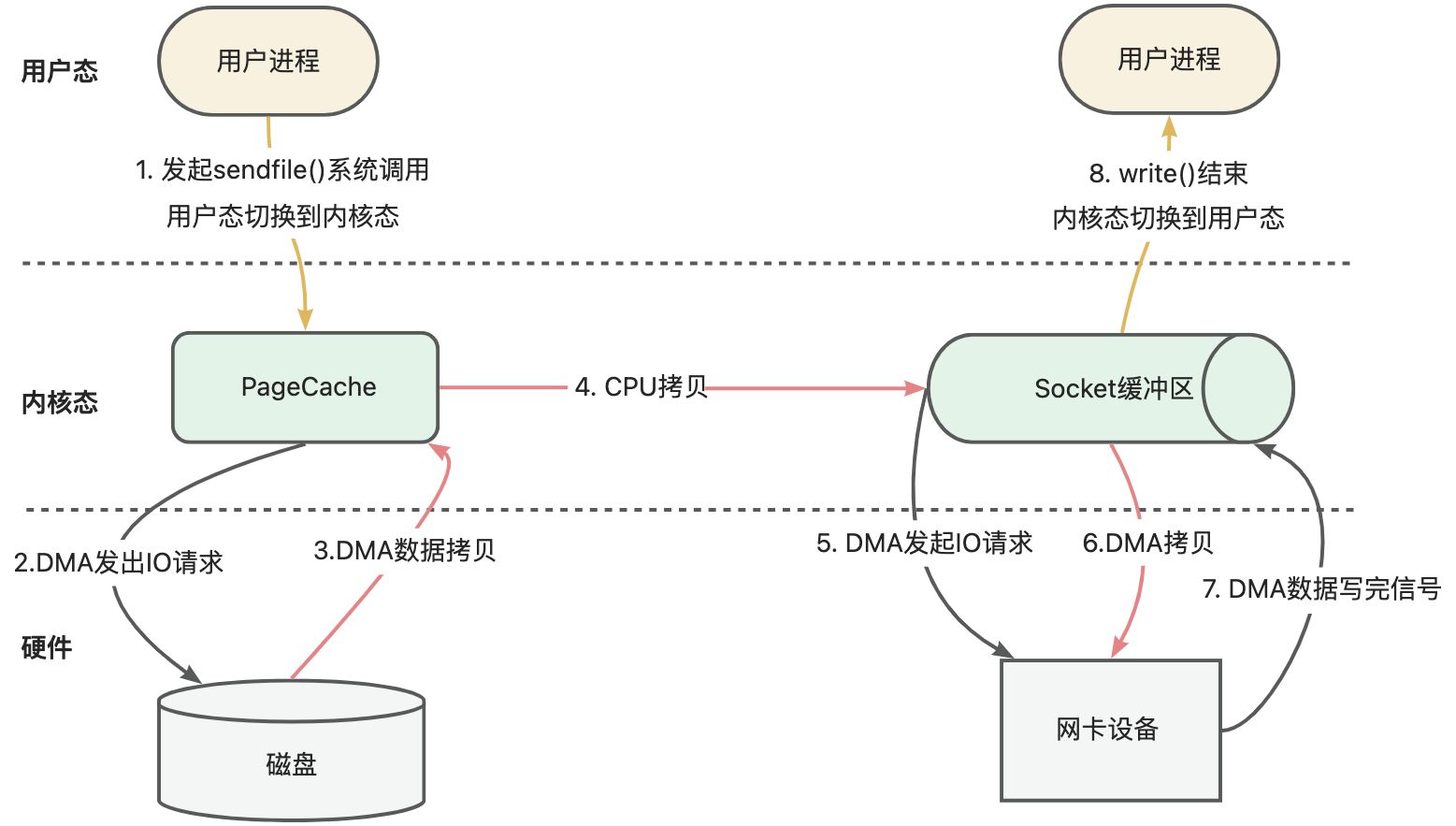
sendfile零拷貝技術在內核態將數據從PageCache拷貝到了Socket緩沖區,這樣就大大減少了不同形態的切換以及拷貝。
所謂的零拷貝技術不是指不發生拷貝,而是在用戶態沒有進行拷貝。
原因四:kafka分區架構和批量操作
一方面kafka的集群架構采用了多分區技術,并行度高。另外一方面,kafka采用了批量操作。生產者發送的消息先發送到一個隊列,然后有sender線程批量發送給kafka集群。
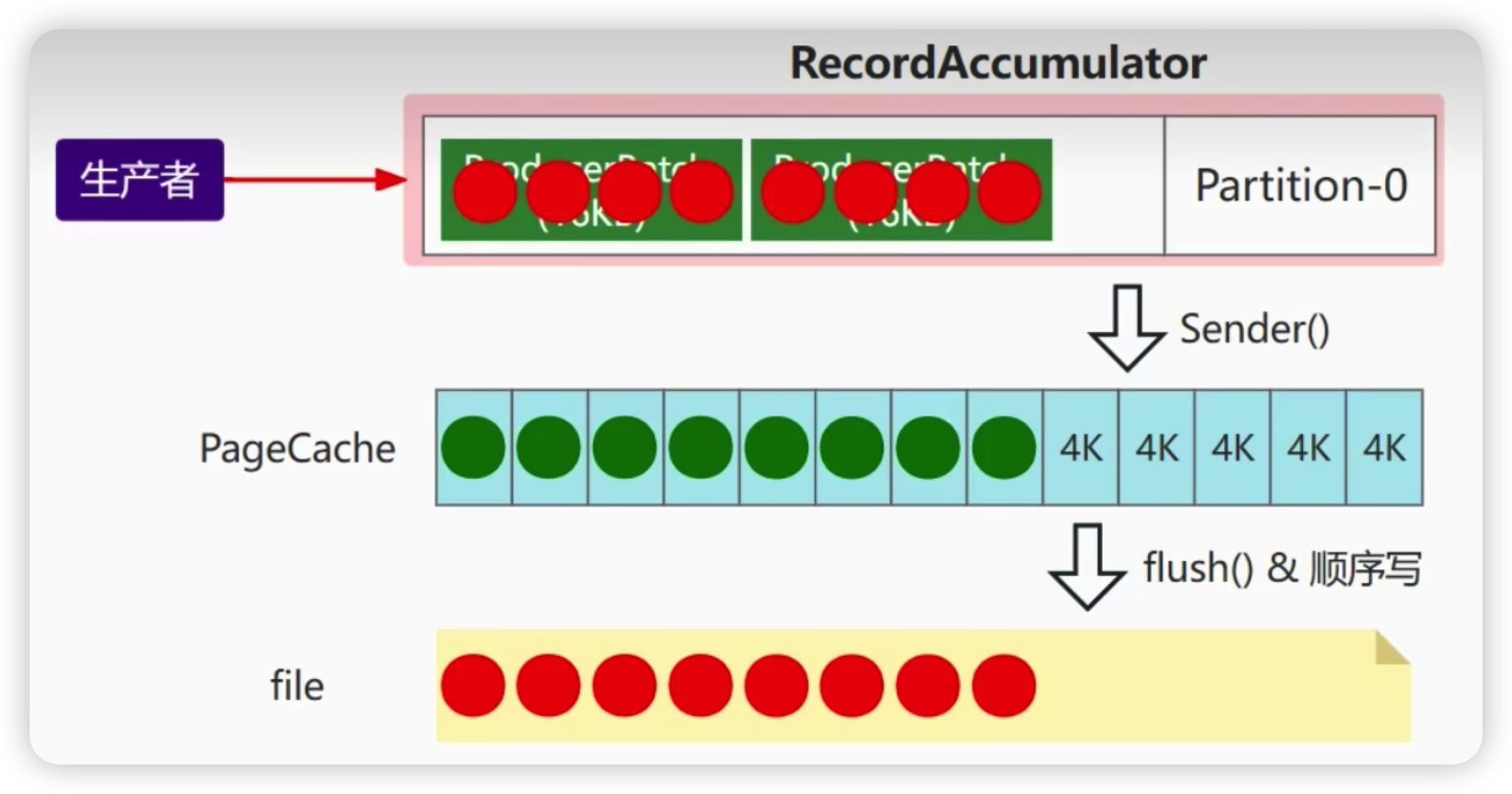
如何提高生產者的吞吐量?
kafka生產者提供的一些配置參數可以有助于提高生產者的吞吐量。
參數名稱 | 描述 |
buffer.memory | RecordAccumulator 緩沖區總大小,默認 32m。適當增加該值,可以提高吞吐量。 |
batch.size | 緩沖區一批數據最大值,默認 16k。適當增加該值,可以提高吞吐量,但是如果該值設置太大,會導致數據傳輸延遲增加。 |
linger.ms | 如果數據遲遲未達到 batch.size,sender線程等待 linger.time之后就會發送數據。單位 ms,默認值是 0ms,表示沒有延遲。生產環境建議該值大小為 5-100ms 之間。 |
compression.type | 指定消息的壓縮方式,默認值為“none ",即默認情況下,消息不會被壓縮。該參數還可以配置為 "gzip","snappy" 和 "lz4"。對消息進行壓縮可以極大地減少網絡傳輸、降低網絡 I/O,從而提高整體的性能 。 |
如何提高消費者的吞吐量?
- 如果是Kafka消費能力不足,則可以考慮增加Topic的分區數,并且同時提升消費組的消費者數量,消費者數 = 分區數,并發度最高。
- 如果是下游的數據處理不及時:提高每批次拉取的數量。批次拉取數據過少,使處理的數據小于生產的數據,也會造成數據積壓。
- fetch.max.bytes:默認 Default: 52428800(50 m)。消費者獲取服務器端一批消息最大的字節數。如果服務器端一批次的數據大于該值(50m)仍然可以拉取回來這批數據,因此,這不是一個絕、對最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影響。
- max.poll.records:一次 poll 拉取數據返回消息的最大條數,默認是 500 條
- 優化消費者代碼處理的邏輯
總結
本文總結了Kafka為什么快的原因,4個關鍵字,磁盤順序讀寫,頁緩存技術,零拷貝技術,Kafka本身分區機制和批量操作。我們抓住這4個關鍵字,有點到面地和面試官娓娓道來。
Kafka 在性能上確實是一騎絕塵,但在消息選型過程中,我們不僅僅要參考其性能,還有從功能性上來考慮,例如 RocketMQ 提供了豐富的消息檢索功能、事務消息、消息消費重試、定時消息等。
通常在大數據、流式處理場景基本選用 Kafka,業務處理相關選擇 RocketMQ更佳。






















