













聊一聊分片和一致性哈希

在設計大規模分布式系統時,你可能會遇到兩個概念——分片(sharding)和一致性哈希(consistent hashing)。雖然我在網上找到了很多關于這些術語的解釋,但它們讓我感到有些困惑。我覺得分片和一致性哈希本質上是在討論同一件事——將數據分布在一組服務器上。
我想—這兩個概念是不是相同的,還是有所不同?如果你也有類似的困惑,讓我們簡要地來解釋一下。
分片
想象一下我們有一個數據庫,其中數據以行和列的形式存儲(就像關系型數據庫,盡管分片也適用于NoSQL數據庫)。當我們的數據集變得非常龐大時(比如1百萬條記錄),對龐大數據集進行任何類型的操作(讀取、更新、刪除、連接等)都會變得非常緩慢。而且隨著數據量的增長,由于服務器可能具有的物理空間(HDD/SSD)的限制,將所有數據存儲在一個數據庫服務器上幾乎是不可能的。為了解決這些問題,最合理的方法是將數據集劃分為較小的數據集。
想象一下,我們將整個數據集(100萬行)劃分為10個較小的子集(每個子集有10萬行)。這個將數據集水平(或沿著行)劃分的過程被稱為對數據集進行分片。
除了提高性能外,分片數據集的另一個非常重要的好處是將這些數據分片存儲在較小且更便宜的數據庫服務器上,而不是將整個百萬行存儲在一個龐大且非常昂貴的數據庫服務器上。
一致性哈希
一致性哈希是一種將龐大的數據集(例如100萬行)分割成多個較小的數據子集(存儲在一組數據庫服務器上)的技術,以確保在集群中的服務器數量發生變化(即添加或刪除服務器)時,數據的遷移量最小。在大規模分布式系統設計中,這非常重要,因為服務器故障在數據中心中相當常見。
對于一致性哈希,我們選擇兩個值M和N,即哈希鍵空間(根據應用程序需求選擇的M)和數據庫服務器數量(用N表示)。通常情況下,M >> N。
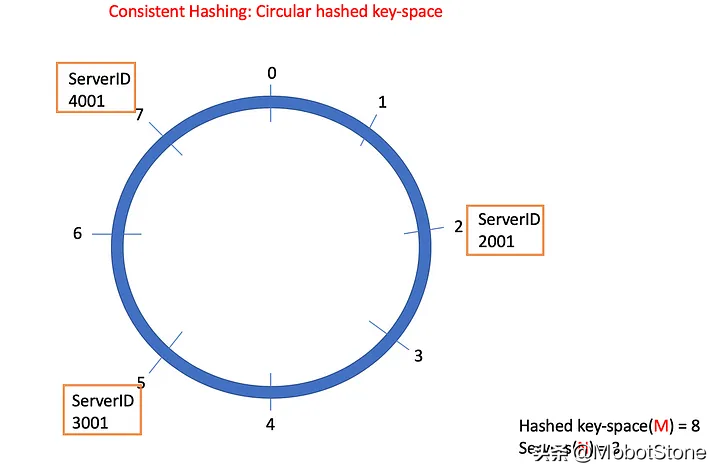
算法本身是一個簡單的三步過程。
創建一個循環數字線(從0到M-1)。 對數據庫服務器ID進行哈希運算,對M取模,并在循環數字線上分配一個位置。 對每個數據行進行哈希(基于其唯一鍵),對M取模,并在循環數字線上找到其位置。順時針方向移動,直到找到第一個數據庫服務器。將這些數據存儲在該服務器上。
好了..那么它們之間有什么真正的區別嗎? 盡管分片和一致性哈希看起來都可以將巨大的數據集分割成較小的數據集,但它們之間存在微妙的區別。分片是所有水平數據分區方案的統稱。從本質上講,分片只是將數據集沿著行進行劃分的一個花哨的名字。
如果你覺得水平分割(或分片)數據集可能有許多不同的方式,那么你是對的。在許多不同的分片數據集的方式/算法中,一致性哈希是最高效的算法之一。所以,這是一個相當簡單但微妙的區別。分片是一個通用術語,而一致性哈希是一種特定類型的算法,用于實現數據分片。























