













圖解什么是一致性哈希算法
本文轉載自微信公眾號「指南針氪金入口」,作者指南針氪金入口 。轉載本文請聯系指南針氪金入口公眾號。
1. 寫在前面
周末就像太陽,總會到來,也總會離開。
此刻,沒錯,是周六呀!還是雙休那種!
昨晚在B站看了幾個長視頻,導致2點才睡覺,早上一覺醒來已經10點了。
在這里溫馨提示各位盆友們,雖然我們都是年輕人,但還是要規律作息,早睡早起。
廢話不多說了,開始今天的話題:
什么是一致性哈希算法。
2. 蒙圈的字面含義
第一次聽這個術語時候困惑于是個啥意思?
一致性,咱懂
哈希算法,咱也懂
一致性+哈希算法 什么鬼?
雖然我大白腦袋比較空,但是我不信所有的網友都知道這個術語,于是在知乎找到個問題,還以為是我寫的呢:
看來還真是有像大白這樣,腦袋不靈光但是充滿好奇的年輕人呀!
于是我決定上路,搞它!
3.分布式系統和一致性哈希
要理解一致性哈希算法就需要知道分布式系統的一些特點。
年輕人你肯定會問:為啥呢?
因為,一致性哈希算法就是為了解決分布式系統中的一些關鍵問題。
3.1 分布式系統概覽
高并發和海量數據處理等場景越來越多,實現服務應用的高可用、易擴展、短延時等成為必然。
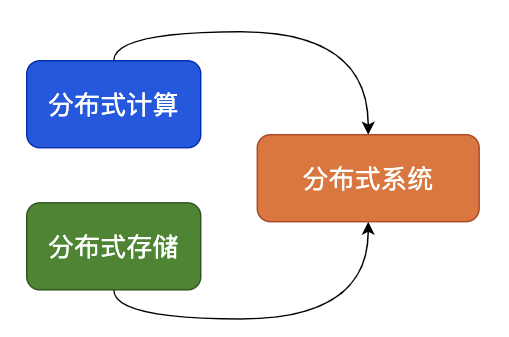
在此情況下分布式系統應運而生,互聯網的場景無外乎存儲和計算,因此分布式系統可以簡單地分為:
- 分布式存儲
- 分布式計算
可以簡單認為分布式系統就是一批物理不相鄰的計算機組合起來共同對外提供服務。
對于用戶來說具體有多少規模的計算機完成了這次請求,完全是無感知的。
分布式系統中的計算機越多,意味著計算和存儲資源等也就越多,能夠處理的并發訪問量也就越大,響應速度也越快。
如圖為簡單整體架構:
3.2 分布式和集群化
集群是從原來的單機演變來的,單臺機器扛不住就加機器,直到服務負載、穩定性、延時等指標都滿足。
集群中的N臺機器上部署一樣的程序,就像一臺機器被復制多份一樣,這種形式就是集群化。
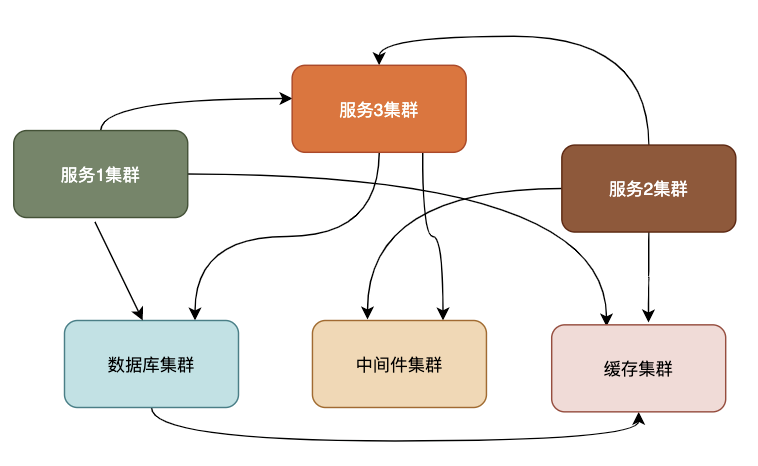
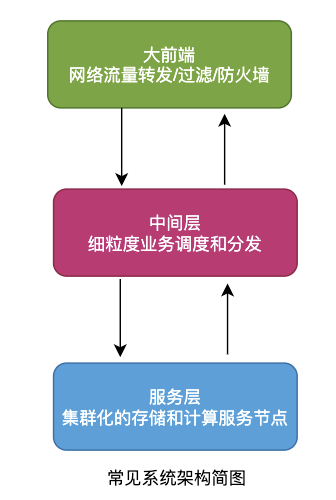
分布式是將一個完整的系統,按照業務功能拆分成一個個獨立的子系統,這些服務之間使用更高效的通信協議比如RPC來完成調度,各個子服務就像在一臺機器上一樣,實現了業務解耦,同時提高了并發能力確實不賴。
一個大的分布式系統可以理解拆分之后的子服務使用集群化,一個個子服務之間使用類似于RPC的協議串聯,組成一個龐大的存儲和計算網絡。
如圖為簡單的分布式系統結構:
3.3 集群化遇到的問題
我們以分布式存儲系統為例子,來說明一致性哈希算法的用武之地。
對于集群來說,機器多了就不好管理,必然會有機器物理故障,業務擴縮容也非常正常,機器的調整必然帶來數據的遷移。
如果存儲集群中有5臺機器,如果這時有讀寫請求,就需要考慮從哪臺機器操作數據,一般有幾種方法:
- 隨機訪問
- 輪詢策略
- 權重輪詢策略
- Hash取模策略
- 一致性哈希策略
各種方法都有各自的優缺點:
- 隨機訪問可能造成服務器負載壓力不均衡;
- 輪詢策略請求均勻分配,但當服務器有性能差異,無法按性能分發;
- 權值需要靜態配置,無法自動調節;
- 哈希取模如果機器動態變化會導致路由產生變化,數據產生大量遷移。
實際中對于規模較小的系統來說,哈希取模策略應用很廣泛,接下來重點介紹hash取模和一致性哈希的區別與聯系。
4. 哈希取模的原理和優缺點
Hash取模策略是其中常用的一種做法,它可以保證相同請求相同機器處理,這是一種并行轉串行的方法,工程中非常常見。
如果數據相對獨立,就避免了線程間的通信和同步,實現了無鎖化處理,所以還是很有用的。
index = hash_fun(key) % N
從上面的普通hash取模公式可以看到,如果N不變或者可以自己主動控制,就可以實現數據的負載均衡和無鎖化處理,但是一旦N的變化不被控制,那么就會出現問題。
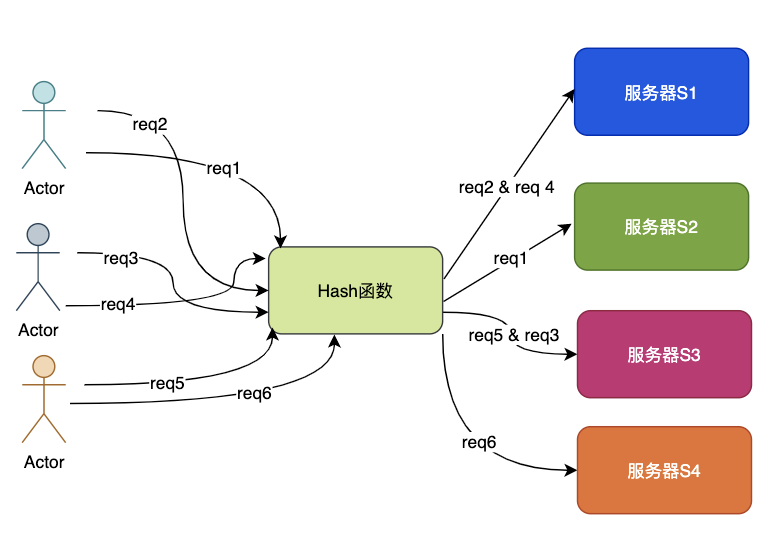
來看看哈希取模策略是如何應對擴縮容問題的,特別注意,為了簡化問題模型,接下來的例子不考慮實例的主從配置。
- 風平浪靜 齊頭并進
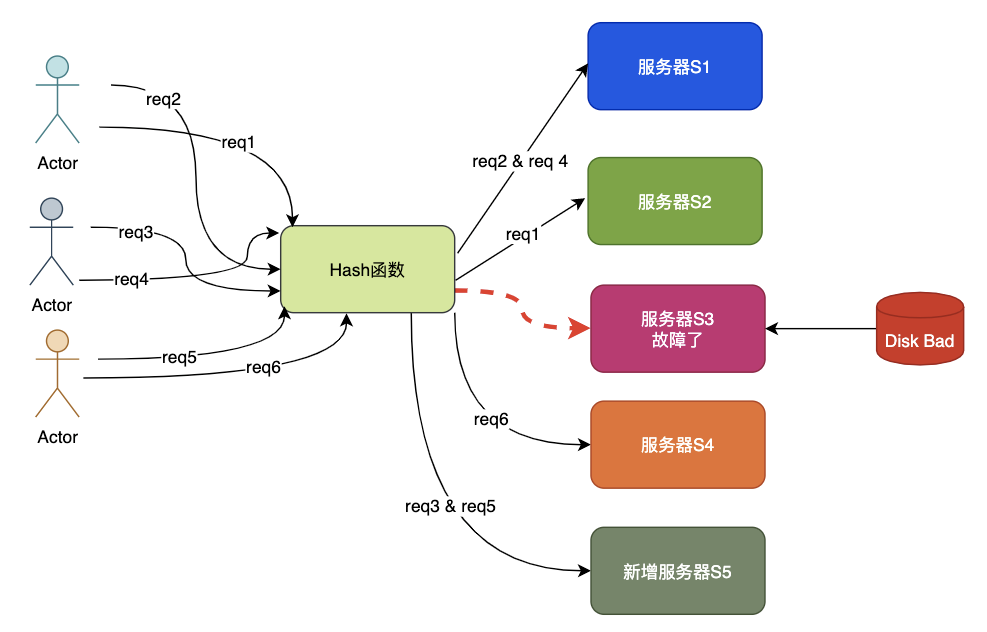
目前有N=4臺機器S1-S4,請求拼接key通過hash函數%N,獲取指定的機器序號,并將請求轉發至該機器。
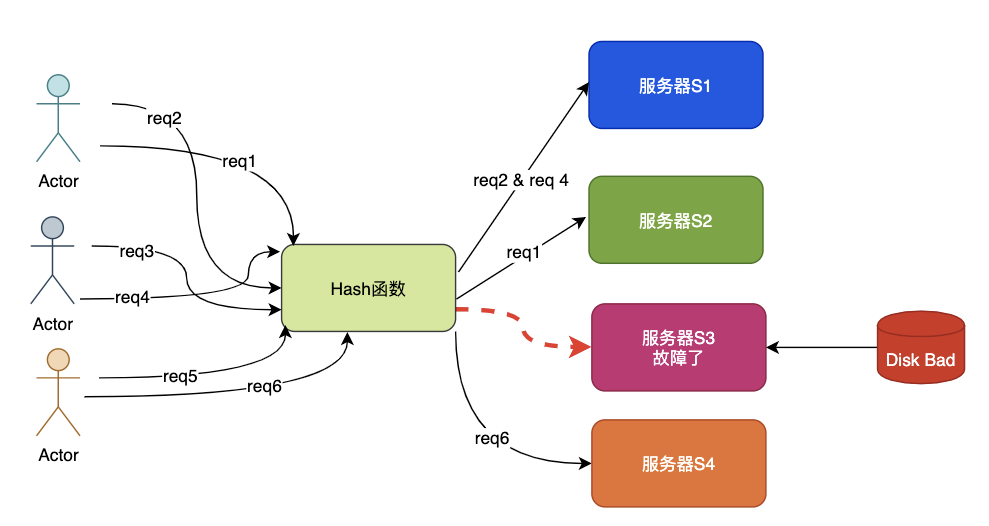
- 磁盤故障 請求支援
S3機器因為磁盤故障而宕機,這時代理層獲得故障報警調整N=3,這時就出現了問題,如果作為緩存使用,S3機器上的所有key都將出現CacheMiss。
原來存放在S1的key=abc使用新的N,被調整到S4,這樣abc也出現CacheMiss,因為在S4上找不到abc的數據。
這種場景就是牽一發而動全身,在緩存場景中會造成緩存擊穿,如果量很大會造成緩存雪崩。
- 兄弟頂住 救兵來了
由于S3宕機了,因此管理員增加了一臺機器S5,代理層再次調整N=4,此時又將出現類似于階段二的數據遷移,仍然會出現CacheMiss的情況。
5.一致性哈希算法
先來看看維基百科的英文定義:
in computer science, consistent hashing is a special kind of hashing such that when a hash table is resized, only K/n keys need to be remapped on average, where K is the number of keys, and n is the number of slots.
簡單翻譯一下:
一致哈希 是一種特殊的哈希算法。
在使用一致哈希算法后,哈希表槽位數(大小)的改變平均只需要對K/n 個關鍵字重新映射,其中 K是關鍵字的數量,n是槽位數量。
在傳統的哈希表中,添加或刪除一個槽位的幾乎需要對所有關鍵字進行重新映射。
從定義可以知道,一致性哈希是一種特殊的哈希算法,區別于哈希取模,這種特殊的哈希算法實現了少量數據的遷移,避免了幾乎全部數據的移動,這樣就解決了普通hash取模的動態調整帶來的全量數據變動。
這個有點厲害了,趕緊看看是咋實現的。
5.1 一致性哈希算法思想
先不看算法的具體實現,先想想普通hash取模的問題根源是什么?
沒錯!根源就在于N的變動和數據歸屬問題。
- N的變動
那么如果N被固定住呢?
如果讓N很大,那么每次被移動的key數就是K_all/Slot_n,也就是有槽位的概念,或者說是小分片的概念,直白一點就是雞蛋放到了很多很多的固定數量的籃子里:
Key_all 存儲的全部key的數量Slot_n 總的槽位或者分片數Min_Change 為最小移動數量 Min_change = Key_all/Slot_nMin_change 也是數據的最小分片Shard
- 小分片的歸屬
這里還有一個問題要解決,將N固定且設置很大之后,數據分片shard變得非常小了,這時就有shard的所屬問題。
也就是比如N=100w,此時集群有10臺,那么每臺機器上理論上平均有10w,當然可以根據機器的性能來做差異化的歸屬配置,性能強的多分一些shard,性能差的少分一些shard。
問題到這里,基本上已經守得云開見月明了,不過還是來看看1997年麻省理工發明的一致性哈希算法原理吧。
5.2 Karger的一致性哈希算法
一致性哈希算法在1997年由麻省理工學院的Karger等人在解決分布式Cache中提出的,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。
一致性哈希修正了CARP使用的簡單哈希算法帶來的問題,使得DHT可以在P2P環境中真正得到應用。
一起看看Karger的一致性哈希算法的基本原理以及如何應對擴縮容問題的。
- 哈希環分片
正如我們前面的思考,Karger的一致性哈希算法將N設置為2^32,形成了一個0~(2^32-1)的哈希環,也就是相當于普通Hash取模時N=2^32。
在將數據key進行hash計算時就落在了0~(2^32-1的哈希環上,如果總的key數量為Sum,那么單個哈希環的最小單位上的key數就是:
- Unit_keys = Sum/2^32
由于N非常大所以哈希環最小單位的數據量unit_keys小了很多。
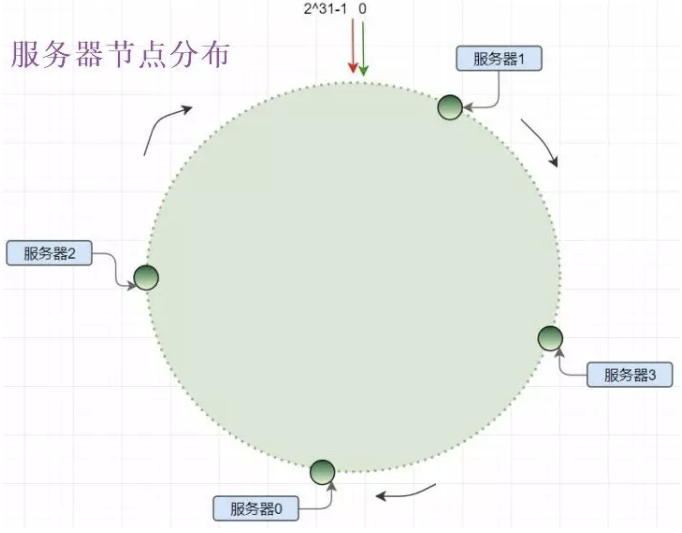
- 服務節點和哈希環分片
將服務器結點也作為一種key分發到哈希環上:
- con_hash(ip_key)%2^32
一致性哈希算法使用順時針方法實現結點對哈希環shard的歸屬,但是由于服務器結點的數量相比2^32會少非常多,因此很稀疏,就像宇宙空間中的天體,你以為天體很多,但是相比浩渺的宇宙還是空空如也。
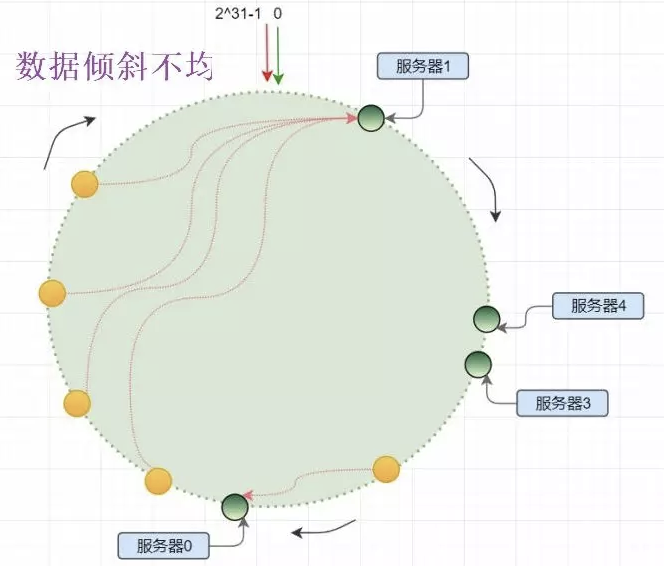
- 一致性哈希的不均衡
實體服務器結點少量相比哈希環分片數據很少,這種特性決定了一致性哈希的數據傾斜,由于數量少導致服務節點分布不均,造成機器負載失衡。
如圖所示,服務器1的負載遠大于其他機器:
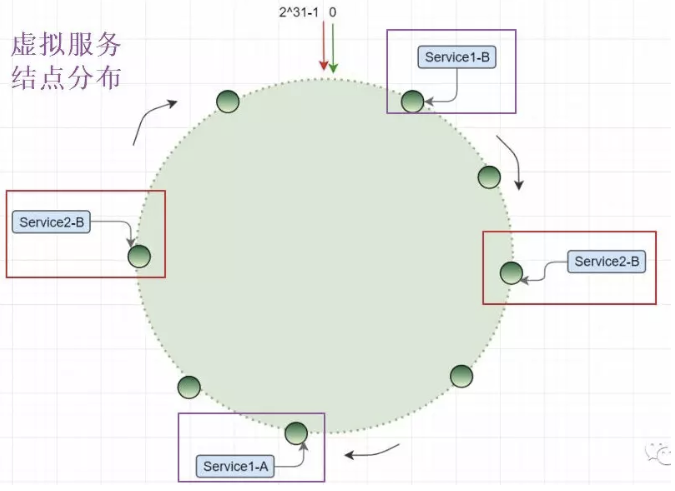
- 虛擬節點的引入
這個說白了服務器結點不夠,就讓服務器的磁盤、內存、CPU全去占位置,現實生活中也這樣:12306出來之前,火車站連夜排隊買票,這時什么書包、水杯、眼鏡都代表了張三、李四、王二麻子。
同樣的道理,將服務器結點根據某種規則來虛擬出更多結點,但是這些虛擬節點就相當于服務器的分身。
比如采用如下規則在ip后綴增加#index,來實現虛擬節點的定位:
- vnode_A_index = con_hash(ip_key_#A)%2^32
- vnode_B_index = con_hash(ip_key_#B)%2^32
- ...
- vnode_k_index = con_hash(ip_key_#k)%2^32
這是由于引入了虛擬節點,因此虛擬節點的分片都要實際歸屬到真實的服務節點上,因此在實際中涉及到虛擬節點和實體結點的映射問題。
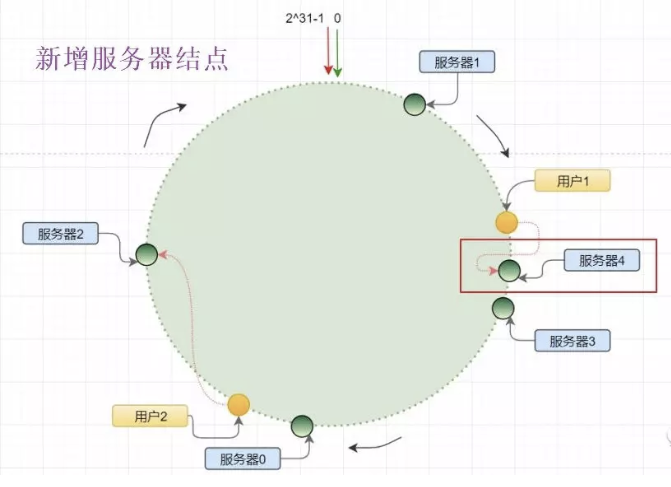
- 新增服務器結點
當管理員新增了服務器4時,原來在服務器3和服務器1之間分布的哈希環單元上的數據,將有一部分遷移到服務器4,當然由于虛擬節點的引入,這部分數據遷移不會很大。
并不是服務器4和服務器1之間的數據都要順時針遷移,因此這樣就實現了增加機器時,只移動少量數據即可。
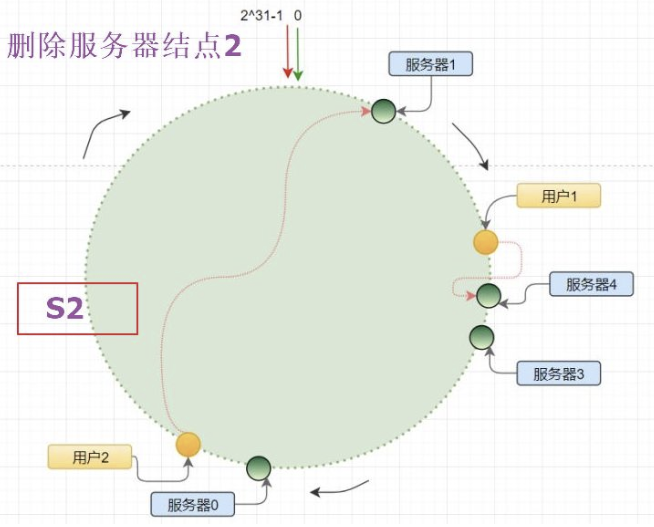
- 刪除服務器結點
當服務器結點2發生宕機,此時需要被摘除進行故障轉移,原來S2以及其虛擬節點上的數據都將進行順時針遷移到下一個實體結點或者虛擬結點。
6. Redis的一致性哈希實現
Redis cluster 擁有固定的16384個slot,slot是虛擬的且被分布到各個master中,當key 映射到某個master 負責slot時,就由對應的master為key 提供服務。
每個Master節點都維護著一個位序列bitmap為16384/8字節,也就是Master使用bitmap的原理來表征slot的下標,Master 節點通過 bit 來標識哪些槽自己是否擁有,比如對于編號為1的槽,Master只要判斷序列的第二位是不是為1即可。
這樣就建立了分片和服務結點的所屬關系,所以整個過程也是兩個原則,符合上文的一致性哈希的思想。
- hash_slot_index =CRC16(key) mod 16384
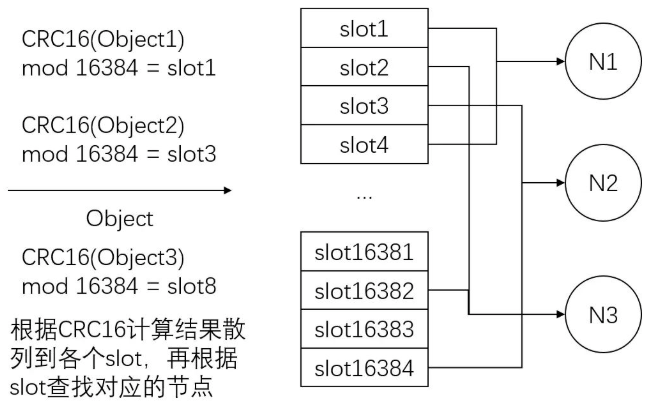
7. 思考和總結
通過前面的對比和理解,我們有必要思考一下,一致性哈希算法的精髓。
7.1 一致性哈希算法的兩個關鍵點
一致性哈希算法是一種特殊的哈希算法,特殊之處在于將普通哈希取模的N進行固定,從而確保了相同的key必然是相同的位置,從而避免了牽一發而動全身的問題,這是理解一致性哈希的關鍵。
一致性哈希算法的另外一個要點就是將N固定且設置很大之后,實際上就是進行數據分片Sharding,分布的小片就要和實際的機器產生關聯關系,也就是哪臺機器負責哪些小分片。
但是一致性哈希算法并不是從徹底解決了由于動態調整服務器數據產生的數據遷移問題,而是將原來普通哈希取模造成的幾乎全部遷移,降低為小部分數據的移動,是一種非常大的優化。
個人認為,一致性哈希算法的關鍵有兩點:
- 大量固定數量的小數據塊的分片
- 小分片的服務器歸屬問題
7.2 算法的其他工程版本
像Redis并沒有使用2^32這種哈希環,而是采用了16384個固定slot來實現的,然后每個服務器Master使用bitmap來確定自己的管轄slot。
管理員可以根據機器的配置和負載情況進行slot的動態調整,基本上解決了最開始的幾種負載均衡策略的不足。
所以假如讓你設計一個一致性哈希算法,只要把握兩個原則即可,并不是只有麻省理工Karger的一種哈希算法,它只是提供了一種思想和方向。
7.3 關于一致性哈希算法的命名
回到最初的疑問:為什么要用"一致性哈希算法" 這個名字。
英文原文是Consistent hashing,其中Consistent譯為"一致的,連貫的",我覺得連貫的更貼切一些,以為這種特殊的哈希算法實現了普通哈希取模算法的平滑連貫版本,稱為連貫性哈希算法,好像更合適,一點愚見,水平有限,看看就完事了。
8.小結
對于指南針的資深讀者來說,應該看出來這是一篇老文章了,確實是的,真是抱歉了。
【編輯推薦】
- 開源 Go 項目推薦:將漢字轉拼音,竟然能帶聲調
- Go GC 怎么標記內存?顏色是什么含義?圖解三色標記法
- 使用Delve代替Println來調試Go程序
- 云原生時代,Java還是Go?
- 螞蟻王益:Go+ 可有效補全 Python 的不足


 分享到微信
分享到微信  分享到微博
分享到微博














