













Delta Lake在BI+AI產品中的實踐

一、觀遠數據分析產品簡介
觀遠數據成立于2016年,總部位于杭州,主要為企業提供一站式的數據分析與智能決策產品和解決方案,客戶包括聯合利華、招商銀行、安踏、元氣森林、小紅書、B站等,分布在零售、消費、金融、互聯網等各個領域。公司的愿景是——“讓業務用起來,讓決策更智能”。我們發現很多時候數據分析產品并沒有很好地在企業內部被用起來,往往是業務提需求,讓IT部門做一些數據處理和報表,這個周期可能會比較長,并不利于敏捷、及時的分析決策。

關于數據分析產品功能,觀遠已經做的比較完備,涵蓋了數據接入、數據開發、數據分析、數據應用等各個環節。產品圍繞著“讓業務用起來”,在易用性方面有一些比較有特色的功能,比如智能ETL,它也是最受客戶歡迎的功能之一,使用門檻非常低,業務人員可以不用關心SQL,通過拖拉拽的方式進行一些數據算子的組合來進行數據開發。另外我們基于Delta lake和Python開發了數據解釋功能,提供了對數據進行多維分析的能力,可以去探尋數據背后的根因,提升我們對數據的洞察能力。
這里舉一個具體的客戶案例,某頭部銀行,其BI平臺月活達到4萬以上,百分之九十的分析行為可以在3-5秒內完成。他們的計算引擎構建在18000核的超大集群上,每日完成超過50萬的Spark任務。能夠支撐這么多用戶活躍地使用,背后是依托于Delta Lake和Spark的存儲計算方案。接下來將介紹我們在這一領域的一些實踐。
二、Delta Lake的應用實踐
1、數據湖架構介紹
Delta Lake是Databricks公司開源的數據湖存儲方案,最初選擇Delta Lake的一個原因也是因為是Databricks開源,和spark的結合應該會有比較好的性能。

這是一個比較典型的架構圖,它依托于底層的 HDFS 或者是對象存儲,又或者云上的一些存儲方案,去支撐上層的BI、AI應用,對多應用的支持也是數據湖的一個重要的特性。數據入湖的方式包括批量和流式。在BI的分析場景,批量方式會多一些,實時能力也在逐漸興起。
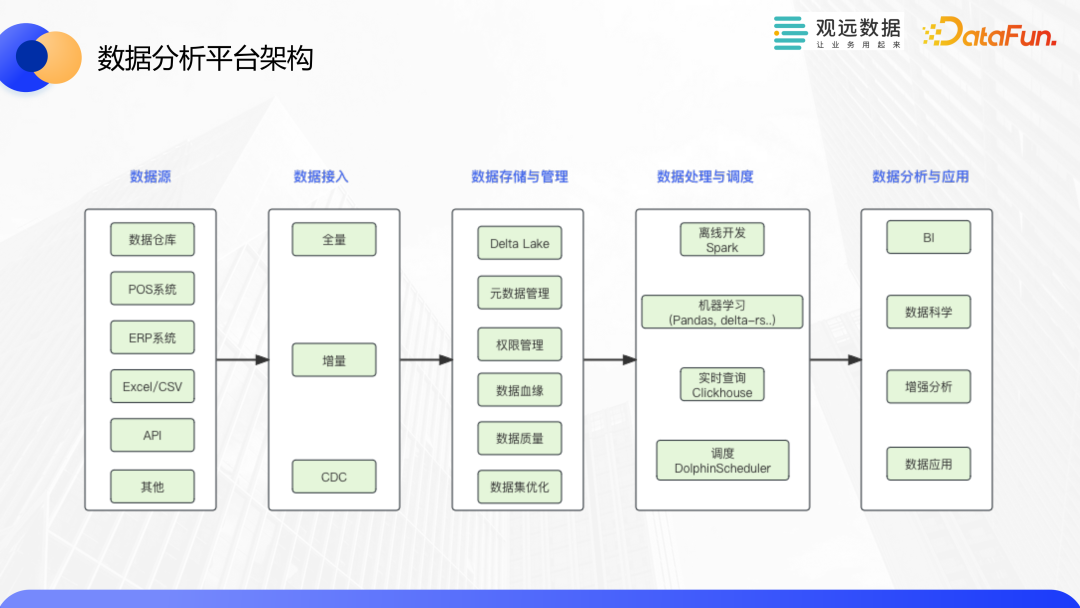
接下來我們看一下將 Delta應用在BI平臺之后的整體架構。數據接入層負責將客戶的數倉、業務系統、文件、API通過全量、增量、CDC的方式,接入到我們的平臺中。數據存儲和管理負責Delta Lake數據集、元數據管理,權限管理、血緣管理、數據質量檢查以及一些優化策略等。
數據處理和調度部分,離線開發主要基于Spark進行,它作為核心計算引擎,同時也支持機器學習工具,如Pandas,delta-rs 等。我們也引入了 ClickHouse作為查詢加速引擎,和Spark在某些場景形成互補。使用DolphinScheduler 作為任務編排和調度工具。數據分析和應用層包括BI平臺、數據科學平臺以及一些數據應用等。
2、Delta Lake的特性及應用

Delta Lake 的重要特性包括ACID事務的支持、全量/增量更新、Schema管理、對多引擎的支持(包括spark、機器學習框架等)、數據版本支持、分區、存算分離適配多種存儲方案以及流批一體的能力。

首先我們來看一下Delta Lake的表結構,其中 delta_log目錄用來記錄對表的變更歷史。每次commit都會生成一個JSON文件,每10次提交會生成一個 checkpoint文件。為什么會有checkpoint文件?它可以在Spark讀取數據的時候提供一些性能優化。當通過Spark去訪問時,可以基于某一個checkpoint文件以及之后的變更,不用去遍歷以往的大量的JSON 文件,從而提高訪問效率。如果設置分區字段,我們就會看到類似于 date=2019-01-01這樣的文件夾,它表示在date字段上設置了分區,目錄下的parquet文件就是分區中的數據。如果沒有設置分區,這些parquet文件就會以平鋪的方式進行組織。
接下來介紹一下ACID。首先,原子性方面,通過delta log來進行控制和管理。在一個事務中,數據文件會被寫入到數據文件夾下。當事務完成時,會向delta log寫入一條新的記錄,其中包括在事務中所有被修改的文件路徑,每一次提交都會增加表的版本號。操作過程中可能會發生異常。如果數據文件已經被寫入到文件夾下,當事務失敗時,這些文件將不會作為表的數據文件。一致性采用樂觀并發控制的方式,會將寫操作分為三階段。首先是讀取最新版本檢查哪些文件需要修改,接著開始寫入數據文件,最后是驗證和提交。在這個階段中,會檢查所有將要提交的變更和其他并發的事務有沒有沖突,如果沒有沖突,就可以進行提交,生成一個新的版本,寫操作完成。Delta Lake默認隔離級別是寫序列化,結合上面介紹的樂觀并發控制策略,可以提供比較好的一個吞吐能力。最后,因為 Delta Lake表是存在 HDFS、S3 或者 NAS 這些存儲方案上,這些存儲服務本身也提供了高可用和持久化的能力,因此它的持久性是依托于底層的存儲服務來實現的。

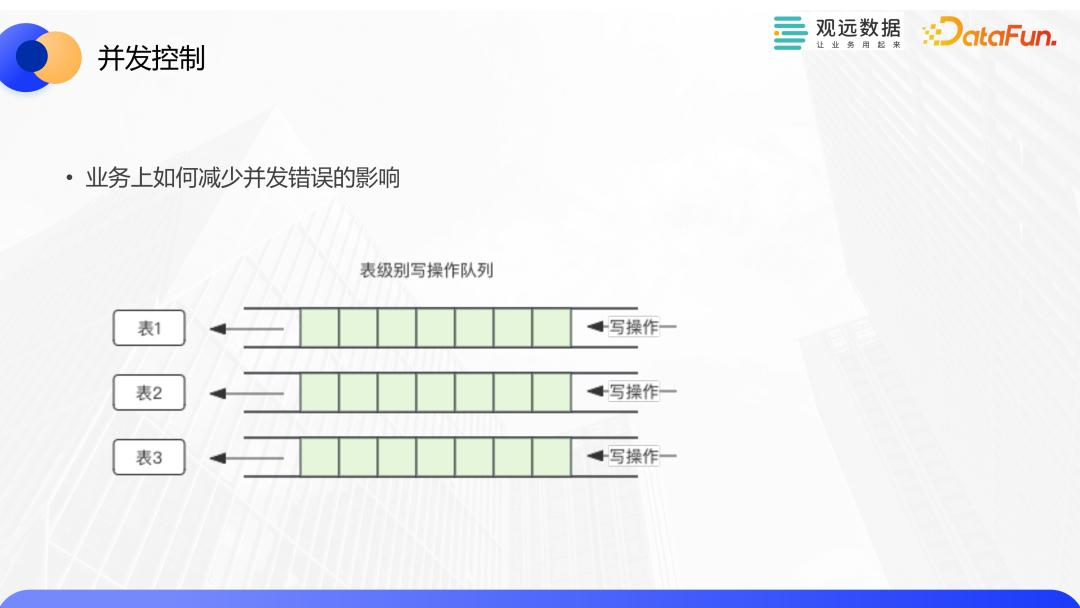
當我們對數據集進行并發更新的時候,尤其是并發修改可能會涉及到相同的數據文件時,仍然有可能會發生并發異常。BI業務的特點是平臺上每天都會運行大量的任務,當出現異常的時候,不僅會影響當前的任務,也會影響后面的任務。我們可以基于業務特點,通過一些優化來避免這些影響。比如可以對每個表維護一個寫操作的隊列,去順序執行。這里面的操作包括更新、小文件合并、版本清理等可能會出現并發異常的操作。小文件合并和版本清理也是性能優化的重要手段。
全量增量更新的能力,也是 BI業務中的基本能力。其中全量覆蓋用在表初次加載或者重建的時候。增量更新也是一個非常重要的特性,當我們以 t +1 的方式從客戶系統中取數時,可以使用基于時間戳的增量更新機制來提高加載效率。Delta Lake也支持追加新數據的方式,這時候不會對歷史數據做修改。
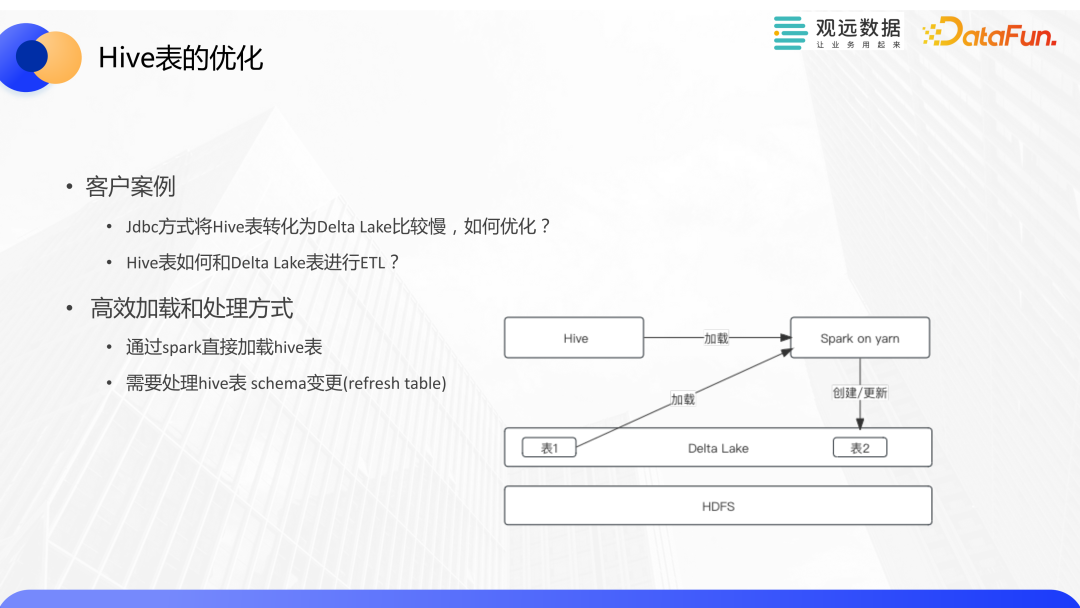
數據入湖的方式,對于數據倉庫或者業務庫來說,通常可以采用JDBC 的方式從源端抽數生成一個臨時文件,通過 Spark 把它轉化為Delta Lake的數據集。這種方式對接方便,較為通用。針對抽取 Hive 表比較慢的情況,因為 Hive 表本身的數據文件以及Delta Lake的數據文件都會存在 HDFS 上,沒有必要再去生成臨時文件,而是可以通過 Spark 去直接加載 Hive 表并進行轉換,這樣就大大提高了加載效率。
衍生的一個問題是,客戶希望可以將 Hive 表和Delta Lake表進行直接的ETL。我們的做法如下圖所示,依然通過 Spark 來加載 Hive 表和 Delta Lake表,并進行處理。前文中介紹過智能 ETL 這一模塊,我們也在不斷將這些能力和ETL進行結合,提升數據開發的易用性。
Schema 管理也是數據開發中常被討論的一個話題。默認情況下Delta Lake不允許追加 schema不匹配的數據。不過它也提供了一種機制來支持schema變化,比如通過 mergeSchema參數。舉個例子,假設初始的源表有兩個字段,分別是first_name和age,通過它去創建一個目標的Delta Lake表會和源表具有相同的 schema信息。當源表的Schema發生變更,比如age字段被刪除,添加了一個新的字段,這時如果我們再向之前的那個表去追加數據時,會發生錯誤。我們可以使用 mergeSchema的機制來向目標表去追加新數據,這樣目標表schema 也會反映源表的變更。

多引擎支持方面,Spark 是我們核心的處理引擎,它是和Delta Lake結合得最緊密,也是使用場景最廣泛的計算引擎。我們的產品中使用 Spark 和Delta Lake來進行數據的接入、開發、數據分析等任務。Spark本身作為大數據技術中的明星,有很多優異的特性,包括對大規模集群的支持、高效任務處理、社區活躍以及性能表現優越等。Delta-rs是我們在算法實驗中比較重要的一個工具,他是一個rust庫,上層也實現了python API。引入delta-rs的主要原因是避免啟動一個很重的spark應用,而是把大部分計算資源預留給E TL和交互式查詢使用,而且算法任務中希望通過python直接消費數據,delta-rs剛好提供了這樣的能力。相比spark,他有更好的讀取性能。不過缺點是對寫入支持不完善,存在bug,我們也對社區提了一些優化。
Standalone Reader 是一個java庫,可以比較方便的讀取數據、和schema。不過這個項目感覺缺乏維護,存在一些bug。也不支持sql查詢和寫入。使用場景比較有限,比如說數據集的簡單預覽等。我們也對這個項目做了一些修復。
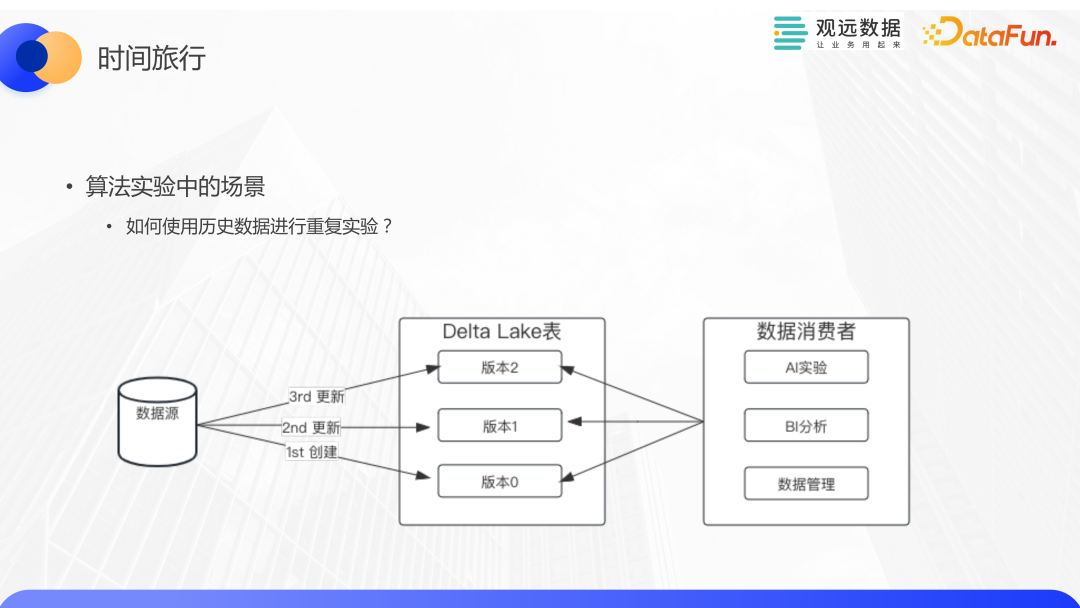
時間旅行,也叫 time travel,指的是對數據多版本的支持。給大家介紹一個算法實驗中的場景,比如我們的算法工程師在進行算法實驗時,除了使用最新的數據外,也想使用歷史版本的數據來進行實驗效果的比對,時間旅行剛好可以很好地解決這些問題。
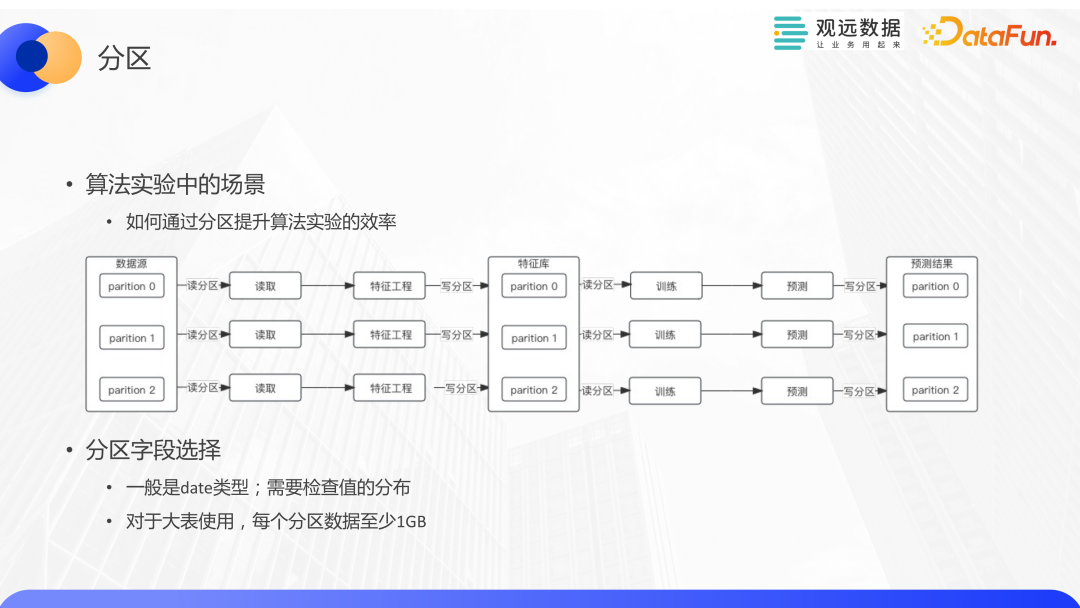
關于分區,也以一個算法實驗的場景來說明如何通過分區來提高算法實驗的效率。我們和客戶合作的銷量預測場景,業務上區分了不同的產品線,比如洗浴產品、食品等。每條產品線的業務形態不同,因此需要去分別構建模型。不過這些特征工程的邏輯比較接近,所以我們可以把這些都放在一個數據集里,通過分區來管理。因為不同分區的寫入不會發生沖突,這些流程都可以并發運行,從而提升了的執行效率。對分區字段的選擇,也是有一些要求的,比如一般是date類型,在進行正式的分區之前,可以做一些前置檢查看字段是否適合分區,避免使用錯誤的情況;另外,分區適合對大表使用。
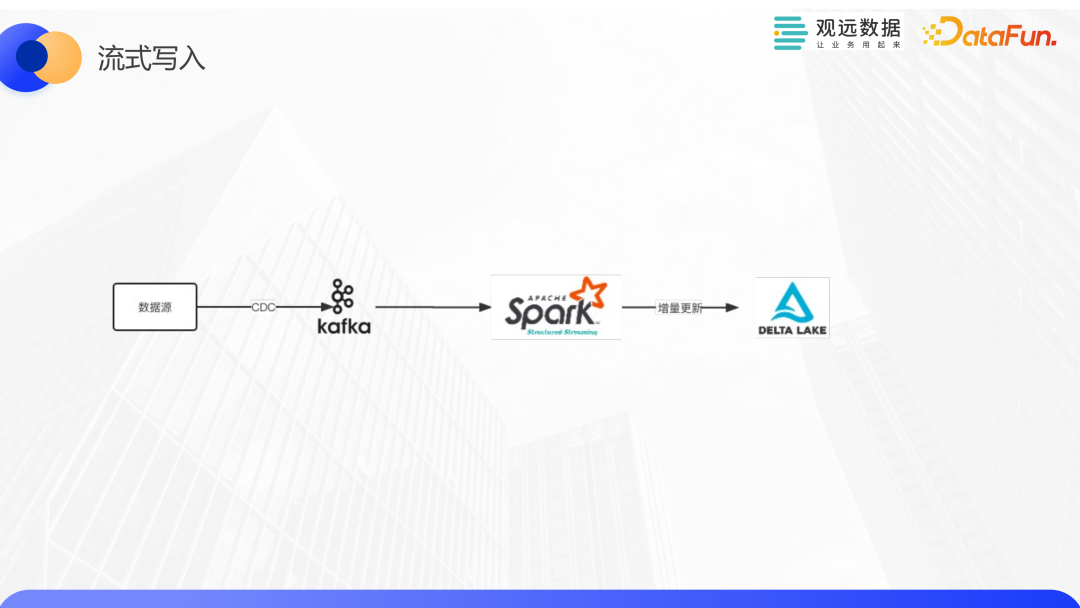
下圖是一個典型的流式寫入流程,通過一些實時同步工具,將源端數據同步到Kafka,再通過Spark Structured Streaming進行增量更新,同步到Delta Lake,供上層應用使用。
性能優化主要在以下四個方面:
- 小文件合并(compaction):當持續更新數據集時,數據文件會不斷增多,我們觀察發現,當對一個數據集進行比較高頻的更新,比如每 5 分鐘做一次更新,在幾個小時之內,文件數量就可能增加到數萬甚至更多。大量的文件會嚴重影響 Spark 的查詢性能。因此我們需要將大量的小文件壓縮為少量大文件,去提高訪問效率。
- 版本清理(vacuum):在數據分析的很多場景我們只需要使用最新數據就可以了,Delta Lake提供了vacuum機制來進行版本清理。如果使用了時間旅行,需要根據情況來制定版本清理策略。關于小文件合并和歷史版本清理的時機,我們一般通過定時任務來觸發,我們也在客戶環境觀察到這樣的現象,比如一天之內會有幾個任務比較密集的時間段,文件和磁盤的增長都比較快,我們的定時策略可以靈活地調整,在這些任務完成之后進行及時地合并和清理。
- 僅讀取需要的列:算法中也有一些典型應用場景,比如可以把Delta Lake的表當成特征庫來使用,構建包含數百列的大寬表,但每個產品線在建模時,可以只選擇其中所需要的列,這也利用了列式存儲的優勢。
- 持續升級版本
三、總結和展望
我們會持續地去升級版本,使用新的一些特性,比如Z-Order對查詢性能的優化,DML增強等。同時,我們也會讓我們的產品更加云原生,融合多引擎,包括 Databricks,ClickHouse等。也計劃讓Delta Lake更加開放,可以通過 SQL 的方式提供給其它工具使用。此外,我們計劃可以基于數據集catalog做數據資產管理。我們也在持續的回饋社區,公司內有多位delta lake,spark,delta-rs的contributor。






















