Ray 在微信 AI 計算中的大規(guī)模實踐
一、背景
微信現(xiàn)在已經(jīng)成為人們?nèi)粘I钪蟹浅V匾慕M成部分,而隨著人工智能的發(fā)展,微信內(nèi)也為用戶提供了多種涉及 AI 計算的服務(wù)體驗。例如,語音消息的文字轉(zhuǎn)換、視頻號的 AIGC 和推薦、掃一掃功能的圖像識別等。這些功能由于微信的用戶規(guī)模巨大,所以 AI 計算的服務(wù)規(guī)模也非常大。
為了應(yīng)對大規(guī)模的 AI 計算任務(wù),我們建立了 Astra 平臺,目前,有許多業(yè)務(wù)已經(jīng)接入了 Astra 平臺,這些業(yè)務(wù)在平臺上構(gòu)建了眾多 AI 算法服務(wù),覆蓋了 LLM/多媒體處理等多個方面。

目前我們對于 Ray 的使用場景主要是 Ray Serve,在 Astra 平臺之前,我們團(tuán)隊是一個純粹的后臺開發(fā)團(tuán)隊。因此在我們在實際工作中,會更加深入的思考 AI 算法服務(wù)與傳統(tǒng)微服務(wù)之間的區(qū)別。
首先,關(guān)于應(yīng)用規(guī)模,傳統(tǒng)的微服務(wù)一般最多只有幾千個節(jié)點、十來萬核。然而,在AI算法這種計算密集型的任務(wù)上,我們的 AI 算法服務(wù)往往需要數(shù)十萬節(jié)點,其計算資源需求可達(dá)數(shù)百萬核。這種超級應(yīng)用對我們的模塊管理系統(tǒng)以及 K8S 集群提出了極高的要求,要支撐如此大規(guī)模的應(yīng)用部署是非常困難的。
其次,隨著資源數(shù)量和資源種類的增加,部署復(fù)雜度快速升高。AI 算法服務(wù)對 GPU 資源有特殊需求,市場上存在多種類型的 GPU,例如 NVIDIA、紫霄、昇騰等品牌。這些不同型號的 GPU 需要特定的適配工作,這無疑增加了每次部署時的復(fù)雜性和工作量。
再者,運維難度亦不容忽視。微服務(wù)主要涉及業(yè)務(wù)邏輯,不存在復(fù)用性,但 AI 算法是一種純算法服務(wù),并不存在業(yè)務(wù)邏輯,不同的業(yè)務(wù)可能都會需要分別部署獨立的集群,這也相應(yīng)地提高了運維工作的復(fù)雜程度。
最后,成本問題同樣突出。當(dāng)前 GPU 的價格高昂,算力資源十分昂貴。降低 AI 推理的成本并提高資源利用率也是我們的重要目標(biāo)之一。
鑒于上述考慮,我們選擇了 Ray。它可以提供統(tǒng)一的分布式平臺,整合多種計算模式,構(gòu)建一個完整的生態(tài)系統(tǒng)。
早在 2022 年,我們就注意到 Ray 的優(yōu)勢,當(dāng)時對于 Ray 的理解尚淺,但觀察到國內(nèi)外眾多企業(yè),包括 ChatGPT 等先進(jìn)應(yīng)用的成功案例,我們決定加大對 Ray 的投入,利用其將單機應(yīng)用輕松擴(kuò)展至分布式環(huán)境的能力,簡化我們的開發(fā)流程,并實現(xiàn)更高效的資源管理。

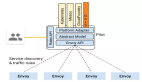
接下來介紹 Astra 平臺與 Ray 結(jié)合的整體架構(gòu)。在這一架構(gòu)中,平臺管理的基本單位是基于 Ray 的應(yīng)用,其底層由我們自主設(shè)計的聯(lián)邦集群架構(gòu)支撐。該架構(gòu)底層連接至公司內(nèi)部多個 K8S 集群,允許我們的應(yīng)用部署于不同的 K8S 集群之上。這些 K8S 節(jié)點是我們預(yù)先從 K8S 申請的資源,每個節(jié)點上都會集成我們 Starlink 集群管理的 Agent、網(wǎng)絡(luò)穿透 P2P 下載組件以及 TFCC AI 運行時。
架構(gòu)圖的下層展示了 Starlink 集群管理模塊,它主要提供了以下幾項核心能力:服務(wù)發(fā)現(xiàn)、負(fù)載均衡、容災(zāi)調(diào)度以及應(yīng)用調(diào)度。面對的主要挑戰(zhàn)是支持多達(dá)數(shù)十萬個節(jié)點的大規(guī)模集群管理,這意味著我們需要具備處理百萬級 Pod 節(jié)點的能力,并確保高效的集群管理。此外,為了降低成本,考慮到騰訊內(nèi)部可能存在資源利用不充分的情況,我們致力于優(yōu)化資源配置,充分利用那些利用率較低或空閑的資源。最后,為了簡化應(yīng)用部署流程,我們?yōu)樗惴ㄩ_發(fā)人員提供了便捷的方式,使他們能夠迅速且輕松地部署應(yīng)用程序。
通過這樣的架構(gòu)設(shè)計,我們不僅能夠應(yīng)對大規(guī)模集群管理帶來的技術(shù)挑戰(zhàn),還能夠在成本控制和部署效率上取得顯著進(jìn)步,從而更好地支持微信平臺上的 AI 計算需求。

二、百萬級節(jié)點的集群管理
接下來,將詳細(xì)探討在處理百萬級節(jié)點集群管理時所面臨的挑戰(zhàn)及解決方案。
調(diào)度架構(gòu)通常可以分為三種類型:單層、兩層以及共享調(diào)度。每種架構(gòu)都有其特點和適用場景。
單層調(diào)度:這種架構(gòu)類似于 K8S,適用于規(guī)模較小的集群,一般為數(shù)千個節(jié)點。單層調(diào)度的一個主要限制是其較低的并發(fā)度,因為整個集群通常只依賴于單一的調(diào)度器進(jìn)行資源分配。
兩層調(diào)度:此架構(gòu)預(yù)先將資源池中的機器分配給上層調(diào)度器,例如 Spark 采用的就是這種模式。相比單層調(diào)度,兩層調(diào)度具有更高的并發(fā)度,支持更大規(guī)模的集群。
共享調(diào)度:這一概念源于谷歌的 Omega 論文。其核心特點是支持無限數(shù)量的調(diào)度器,每個應(yīng)用都有自己的調(diào)度器,且所有調(diào)度器都能查看到整個資源池的狀態(tài)。我們實現(xiàn)了樂觀調(diào)度策略,即每個調(diào)度器假設(shè)沒有沖突地分配資源,并在檢測到?jīng)_突時進(jìn)行調(diào)整。這種方法不僅能夠顯著提升調(diào)度規(guī)模和資源利用率,還能大幅提高調(diào)度并發(fā)度,非常適合處理數(shù)十萬節(jié)點的大規(guī)模集群需求。
對于需要管理幾十萬甚至更多節(jié)點的超級應(yīng)用而言,選擇共享調(diào)度架構(gòu)幾乎是必然的。它通過允許多個調(diào)度器同時工作,確保了高并發(fā)度和高效的資源利用,滿足了大規(guī)模集群管理的需求。我們的 Astra 平臺結(jié)合 Ray,正是采用了這樣的共享調(diào)度策略,以應(yīng)對微信 AI 計算中遇到的巨大挑戰(zhàn)。

接下來,將深入介紹 Astra 自研調(diào)度架構(gòu)的整體設(shè)計,我們從下往上介紹。
最底層是部署在不同 K8S 集群上的節(jié)點,這些資源是預(yù)先分配好的。例如,特定業(yè)務(wù)可以向 K8S 申請所需的資源,并將其集成到我們的平臺中使用。每個 K8S 集群包含各自的節(jié)點,這些節(jié)點會定期向 resource 集群發(fā)送心跳信號,以報告其狀態(tài)。
Resource 集群會聚合這些心跳信息,并通過廣播的方式實現(xiàn)輕量級的狀態(tài)同步。這一機制保證了即使單個集群僅由幾臺機器組成,也能夠支持多達(dá)百萬級別的節(jié)點管理,并維持一個在線節(jié)點列表,作為高性能資源管理的基礎(chǔ)。
Resource 是整個系統(tǒng)的核心部分,它不僅負(fù)責(zé)收集和同步節(jié)點狀態(tài),還提供了高效的資源管理能力。Resource 集群能夠?qū)崟r掌握所有節(jié)點的最新狀態(tài),為上層調(diào)度提供準(zhǔn)確的信息。
在 Resource 集群之上,是 APP 級別的獨立調(diào)度器。每個應(yīng)用程序(APP)都有自己的調(diào)度器,這些調(diào)度器可以直接訪問整個集群中所有節(jié)點的狀態(tài)信息。每個調(diào)度器的主要職責(zé)包括:資源調(diào)度、負(fù)載均衡、容災(zāi)調(diào)度。得益于共享調(diào)度的設(shè)計,調(diào)度器每分鐘可以處理數(shù)萬節(jié)點的調(diào)度任務(wù),極大提升了系統(tǒng)的響應(yīng)速度和效率。
最上層是用戶操作界面,用于執(zhí)行諸如擴(kuò)縮容等操作。這一層直接與最終用戶交互,提供了直觀的操作體驗,使得用戶可以輕松管理其應(yīng)用程序和服務(wù)。
這套架構(gòu)構(gòu)成了我們進(jìn)行百萬級別集群管理的基礎(chǔ),通過分層設(shè)計和資源共享調(diào)度機制,實現(xiàn)了對大規(guī)模節(jié)點的有效管理,同時保證了高并發(fā)度和資源利用率,滿足了微信 AI 計算中的復(fù)雜需求。此架構(gòu)不僅支持了數(shù)十萬節(jié)點的大規(guī)模集群管理,還顯著降低了運維復(fù)雜度和成本,提高了整體的服務(wù)質(zhì)量和用戶體驗。

三、高效穩(wěn)定地利用低優(yōu)資源
下面探討如何高效且穩(wěn)定地利用低優(yōu)資源。騰訊內(nèi)部低優(yōu)資源的總量非常龐大,但與此同時也伴隨著諸多挑戰(zhàn),“天下沒有免費的午餐”,盡管低優(yōu)資源的成本較低,但也帶來了新的問題。
以下是從我們系統(tǒng)監(jiān)控中截取的幾張圖,能說明我們所遇到的一些問題。
首先,節(jié)點處于亞健康狀態(tài)的比例較高,例如 CPU 時間片可能會被搶占,或者節(jié)點可能隨時被高優(yōu)先級任務(wù)搶占。在 Ray 的應(yīng)用上,當(dāng) Ray 應(yīng)用部署到低優(yōu)資源時,節(jié)點被搶占會導(dǎo)致集群難以恢復(fù)。特別是在 Ray Cluster 錯誤處理方面,如果頭節(jié)點出現(xiàn)故障,會難以恢復(fù)。當(dāng)前社區(qū)版僅提供通過 Redis 備份的方式進(jìn)行恢復(fù),但我們不希望在服務(wù)中引入額外的依賴。因此,我們希望有一種簡潔的解決方案,能快速的地解決這一問題。

針對亞健康節(jié)點及被移除節(jié)點的快速處理,我們采取了一系列措施以確保系統(tǒng)的高效與穩(wěn)定。以下是具體方法:
首先,對于異常節(jié)點的下線,K8S 平臺通常不會提前很長時間通知即將縮容。因此,我們使用 K8S 的 Pre Stop 特性來迅速響應(yīng)。由于我們的心跳檢測頻率為每秒一次,一旦觸發(fā) Pre Stop,我們可以立即從在線列表中移除該節(jié)點。在3秒鐘內(nèi)更新路由表,這意味著在 Pre Stop 觸發(fā)后的 4 秒內(nèi),該節(jié)點將被完全移除。即使節(jié)點隨后被資源平臺直接終止,也不會對我們的服務(wù)造成影響。
其次,對于性能較低的節(jié)點,我們會實時監(jiān)控并收集其運行數(shù)據(jù)。通過自動調(diào)節(jié)權(quán)重的路由算法調(diào)整節(jié)點接收的請求量。具體而言,性能較差的節(jié)點將被賦予較低權(quán)重,而高性能節(jié)點則保持較高權(quán)重。這種機制確保了任務(wù)能夠根據(jù)節(jié)點的實際性能進(jìn)行合理分配,從而優(yōu)化了 serving 層的工作負(fù)載分配,優(yōu)化了整體服務(wù)吞吐和耗時。
通過上述措施,我們不僅能夠快速處理異常節(jié)點,還能有效管理性能差異較大的節(jié)點,確保系統(tǒng)在面對低優(yōu)資源固有問題時仍能保持高效穩(wěn)定的運行。

從我們在 Astra 平臺上使用低優(yōu)資源的效果圖中可以清晰地看到優(yōu)化前后的對比。圖中的綠色線條代表優(yōu)化之前的狀態(tài),而紅色線條則展示了優(yōu)化之后的結(jié)果。通過對比可以看出,優(yōu)化后我們的失敗率顯著降低,同時平均處理時間也得到了大幅改善。

在低優(yōu)資源上使用 Ray 時,我們必須良好的設(shè)計系統(tǒng)來容忍節(jié)點(包括 worker 和頭節(jié)點)被頻繁踢出的情況。為此,我們借鑒了 K8S 聯(lián)邦集群的概念,提出了 Ray 聯(lián)邦集群的架構(gòu)。這一架構(gòu)的核心特點是每個 Ray cluster 作為一個服務(wù)的最小單位,每個 Ray Cluster 都能夠獨立提供完整的服務(wù)。這種設(shè)計確保了即使任意一個 Ray cluster 出現(xiàn)故障,整體服務(wù)依然不受影響。
Ray 聯(lián)邦集群的特點包括:
- 服務(wù)單元化:每個 Ray cluster 都是一個獨立的服務(wù)單元,可以單獨提供完整的服務(wù)。
- 容災(zāi)能力:通過增加更多的 Ray cluster 來實現(xiàn)容災(zāi)。每個 cluster 都可以視為一個容災(zāi)單元,從而增強了系統(tǒng)的魯棒性。
- 突破規(guī)模限制:由于我們的基礎(chǔ)設(shè)施本身支持百萬級節(jié)點管理,我們可以將每個 Ray cluster 設(shè)計得較小,從而突破單個 cluster 的規(guī)模限制。
- 無狀態(tài)服務(wù)般的容災(zāi):無論哪個節(jié)點或整個 cluster 掛掉,我們都可以迅速替換,確保服務(wù)的連續(xù)性。
具體容災(zāi)方案如下:
- 頭節(jié)點故障處理:當(dāng)頭節(jié)點出現(xiàn)心跳異常時,我們會立即從路由算法中移除該 cluster,并調(diào)度一個新的 Ray cluster 進(jìn)行替換。
- Worker 節(jié)點故障處理:如果僅是 worker 節(jié)點故障,該 cluster 仍可繼續(xù)使用,只需替換故障的 worker 節(jié)點即可。
- 擴(kuò)展性:我們的 Ray Cluster 機制支持縱向擴(kuò)容,可以根據(jù)需要調(diào)整 worker 數(shù)量,從而解決了大規(guī)模部署下的擴(kuò)展性問題。
通過上述措施,我們不僅提升了系統(tǒng)的容災(zāi)能力,還確保了在大規(guī)模節(jié)點管理中的高效性和靈活性。此架構(gòu)使得每個 Ray APP 可以擁有無數(shù)個請求者,集群能夠像無狀態(tài)服務(wù)一樣靈活應(yīng)對節(jié)點或 cluster 級別的故障,確保了服務(wù)的高可用性和穩(wěn)定性。

針對訓(xùn)練任務(wù)的自動調(diào)速,我們開發(fā)了一套內(nèi)部工具用于數(shù)據(jù)處理。鑒于低優(yōu)資源隨時可能被移除,這會導(dǎo)致集群處理能力下降,我們對每個節(jié)點的性能進(jìn)行了預(yù)估,即根據(jù)資源類型和數(shù)量來評估其處理能力。隨著集群資源指標(biāo)的變化,我們會自動調(diào)整任務(wù)的消費速率,以確保服務(wù)的正常運行。自動調(diào)速機制如下:
- 性能預(yù)估:我們根據(jù)資源類型(如不同型號的 GPU)和可用資源的數(shù)量,動態(tài)評估每個節(jié)點的處理能力。這一預(yù)估考慮了多種卡型共存的情況,確保評估結(jié)果的準(zhǔn)確性。
- 動態(tài)調(diào)整消費速率:基于性能預(yù)估的結(jié)果,當(dāng)檢測到集群中的資源變化時,系統(tǒng)會自動調(diào)整任務(wù)的消費速率。這種調(diào)整確保即使在資源減少的情況下,也能維持服務(wù)的穩(wěn)定性和性能。
- 保障服務(wù)連續(xù)性:通過上述機制,即使低優(yōu)資源被移除或集群處理能力發(fā)生變化,我們的系統(tǒng)仍能保持正常運行,避免因資源波動導(dǎo)致的服務(wù)中斷。
通過這套自動調(diào)速機制,我們的離線任務(wù)可以穩(wěn)定的在低優(yōu)資源上進(jìn)行部署,確保了在復(fù)雜多變的環(huán)境中,離線任務(wù)能夠持續(xù)高效地運行。

四、降低應(yīng)用部署復(fù)雜度
接下來探討如何降低應(yīng)用部署的復(fù)雜度。一個 APP 可能包含多個模型,每個模型需要部署在不同類型的 GPU 上,且每種 GPU 類型可能會超出系統(tǒng)單個集群的數(shù)量、規(guī)模限制。這種情況下,我們面臨的復(fù)雜度大約是 O(N^3)。為了有效降低這一復(fù)雜度,我們采取了以下措施:
首先,多模型擴(kuò)展。我們選擇 Ray 作為解決方案的關(guān)鍵原因之一在于其能夠簡化多模型擴(kuò)展。以往,服務(wù)中可能需要引入一個中間模塊來專門管理各個模型之間的調(diào)用。而現(xiàn)在使用 Ray,僅需一個腳本即可實現(xiàn)多模型的有效管理和調(diào)度,大大簡化了部署流程。
其次,多卡型擴(kuò)展。針對不同類型的 GPU,我們設(shè)計了相應(yīng)的擴(kuò)展機制。這部分內(nèi)容將在后續(xù)詳細(xì)說明。
最后,多模塊擴(kuò)展。我們的架構(gòu)還支持多模塊的擴(kuò)展,確保系統(tǒng)能夠靈活應(yīng)對不同類型和數(shù)量的組件需求。
通過上述措施,我們顯著降低了應(yīng)用部署的復(fù)雜度,使得多模型、多卡型以及多模塊的管理變得更加高效和簡便。

接下來我們詳細(xì)描述我們?nèi)绾巫龅竭@一點。首先,統(tǒng)一基座環(huán)境。
- 核心組件:該環(huán)境包含了所有必需的核心組件,例如 P2P 網(wǎng)絡(luò)穿透、TFCC 以及特定版本的 CUDA,以確保一致性和兼容性。
- 包管理:允許用戶使用 Conda 管理包,允許用戶選擇不同版本的 Python,并實現(xiàn)自定義環(huán)境配置。這一系統(tǒng)是我們自行開發(fā)的環(huán)境管理工具,旨在為用戶提供靈活的包管理能力。
- 自定義庫與編譯:支持用戶自定義使用各種庫及進(jìn)行 CI(持續(xù)集成)編譯操作,以滿足多樣化的開發(fā)需求。
其次, TFCC 引擎的支持。
針對不同類型的 GPU(如 NVIDIA、昇騰等),特別是當(dāng) NVIDIA 卡用于 TensorRT 時可能需要不同的模型編譯,TFCC 引擎起到了關(guān)鍵作用,它能夠屏蔽底層 GPU 卡的具體類型,使得用戶無需關(guān)心底層硬件細(xì)節(jié)。用戶只需調(diào)用 TFCC 提供的推理接口,即可完成推理任務(wù),無論底層使用何種 GPU 卡。
通過上述標(biāo)準(zhǔn)化的環(huán)境管理方案,不僅簡化了多依賴項的服務(wù)部署,還確保了跨多種 GPU 類型的無縫支持,極大提升了用戶體驗和服務(wù)靈活性。

最后是 P2P 下載優(yōu)化。隨著 AI 模型規(guī)模的不斷擴(kuò)大,正如前面提到當(dāng)前的模型體積已經(jīng)顯著增加。例如,一些常見的 72B 模型可能達(dá)到 140GB 的大小。將如此龐大的模型下發(fā)至各節(jié)點進(jìn)行部署耗時會比較長。為此,我們使用 P2P 對下載能力進(jìn)行了多項優(yōu)化:
- NAT 穿透:實現(xiàn)了 NAT 穿透功能,確保在復(fù)雜網(wǎng)絡(luò)環(huán)境下也能高效傳輸數(shù)據(jù)。
- 節(jié)點限速與全局限速:為保證網(wǎng)絡(luò)資源的合理分配,引入了節(jié)點級別的限速和全局限速機制。
通過這些優(yōu)化措施,我們現(xiàn)在能夠?qū)⒁粋€大約 140GB 的模型在大約 10 分鐘左右的時間內(nèi)完成下發(fā)。這大大縮短了模型部署的時間,提高了整體工作效率。

五、Astra-Ray 使用樣例
下面是在平臺上的一些截圖,幫助大家了解我們平臺的使用界面和部署流程。以下是具體步驟:
第一步是修改代碼,只需要按照 ray serve 做簡單的改寫即可。
第二步是將修改后的代碼打包并上傳至 Git 倉庫。在此過程中,需要選擇一個 Python 版本。平臺會根據(jù)選擇自動打包,生成一個可以在我們平臺上運行的部署包。

第三步是變更 Ray 配置,這實際上是調(diào)整服務(wù)的 deployment 配置。此步驟允許用戶通過配置變更來動態(tài)調(diào)整服務(wù)參數(shù)。考慮到在線服務(wù)的穩(wěn)定性,我們設(shè)計了灰度發(fā)布機制。為了確保配置變更能夠平穩(wěn)生效,而不對現(xiàn)有服務(wù)造成即時沖擊,用戶可以通過灰度發(fā)布的方式逐步應(yīng)用新的配置。這種方式允許新配置在一部分流量中先行驗證,確保其穩(wěn)定性和兼容性后再全面推廣。通過這一機制,用戶可以在不影響整體服務(wù)的情況下,安全地測試和應(yīng)用新的配置調(diào)整,從而保障了服務(wù)的連續(xù)性和可靠性。

第四步是進(jìn)行擴(kuò)容。完成擴(kuò)容后,可以立即看到服務(wù)啟動,并在平臺頁面上查看集群的機器列表。例如,展示的一個集群機器列表中,包含大約 4,000 多個請求者(requester),每個請求者對應(yīng) 5 臺機器,總計超過 2 萬個節(jié)點。
此外,我們還提供了以下功能以支持更高效的管理和調(diào)試:
- Ray Dashboard:用戶可以通過 dashboard 查看請求的狀態(tài)和性能指標(biāo)。
- 日志調(diào)試:平臺支持日志記錄和調(diào)試功能,幫助用戶快速定位和解決問題。

六、Q&A
Q1:關(guān)于低優(yōu)資源的抖動狀態(tài)問題
問:您剛才提到的低優(yōu)資源存在 3 秒更新路由表和每秒更新機制。對于一些狀態(tài)不穩(wěn)定的資源,例如其性能可能一會兒好一會兒壞,這種情況是否會引發(fā)抖動?這種不穩(wěn)定狀態(tài)是如何處理的?
答:理解您的問題,確實存在兩種情況:
性能波動:當(dāng)節(jié)點的 CPU 被壓制時,可能會出現(xiàn)性能不穩(wěn)定的情況。我們通過動態(tài)調(diào)整權(quán)重來應(yīng)對這一問題,確保即使性能波動也不會影響服務(wù)的整體質(zhì)量。
節(jié)點掉線與重啟:如果一個節(jié)點突然掉線后重新啟動,我們會將其視為一個新節(jié)點進(jìn)行處理。若它快速重啟,可能不會特別關(guān)注;但如果觸發(fā)了 PreStop 機制,則該節(jié)點會被移除,并在重新上線時作為新節(jié)點加入資源池。
Q2:關(guān)于每秒更新頻率的問題
問:每秒更新的頻率是否過高?這是否會帶來額外的壓力?
答:每秒心跳確實會帶來較高的請求量,尤其在面對數(shù)十萬個節(jié)點時,會產(chǎn)生較高的 QPS 壓力。為此,我們采用了聚合擴(kuò)散機制來減輕集群負(fù)擔(dān)。首先,我們要保證自身服務(wù)的性能;其次,在集群容量接近極限時,可以通過擴(kuò)展更多集群來支持更大的規(guī)模。Starlink 架構(gòu)并非局限于單一 Resource 集群,而是也可以靈活擴(kuò)展至多個集群。
Q3:超級 APP 跨集群調(diào)度機制
問:超級 APP 如何實現(xiàn)跨多個 Ray Serve 的調(diào)度?是通過每個集群內(nèi)部的調(diào)度器還是有更高層次的調(diào)度機制?
答:通過 RPC 的方式,不同 Ray 集群之間是不互通的,但是我們保證每個 Ray 集群都有完整的功能。
Q4:超級 APP 副本故障恢復(fù)機制
問:在一個超級 APP 擁有大量副本的情況下,如果部分副本掛掉,是由哪個調(diào)度器負(fù)責(zé)重啟這些副本?
答:由 APP 自身的調(diào)度器負(fù)責(zé)維護(hù)其所有 Ray Serve 的狀態(tài)。即便應(yīng)用規(guī)模龐大,調(diào)度器也僅需定時掃描即可管理。假設(shè)一個超級 APP 有 100 萬個集群,掃描一次也只需一秒鐘左右的時間。因此,即使是超大規(guī)模的應(yīng)用,其調(diào)度器也不太可能成為瓶頸。
Q5:聯(lián)邦集群的逐步擴(kuò)展與負(fù)載均衡
問:聯(lián)邦集群是如何逐步擴(kuò)展并淘汰舊集群的?特別是在進(jìn)行版本升級時,如何保持負(fù)載均衡?
答:聯(lián)邦集群的擴(kuò)展和淘汰是一個漸進(jìn)的過程。頭節(jié)點并不執(zhí)行具體的業(yè)務(wù)邏輯或 worker 任務(wù),而是與 worker 等價,以減少對系統(tǒng)的影響。在做路由算法時,我們將所有節(jié)點視為等同,簡化了管理和調(diào)度過程。
Q6:在線服務(wù) Runtime 優(yōu)化
問:是否在 Ray 的 runtime 層面進(jìn)行了特定優(yōu)化?
答:目前我們尚未對 Ray 框架本身進(jìn)行修改。該項目從今年上半年開始引入 Ray,因此現(xiàn)階段的重點在于集成而非深度定制。
Q7:TFCC 引擎的透明性與模型轉(zhuǎn)換
問:實際使用者是否需要關(guān)注推理引擎的選擇?模型轉(zhuǎn)換和優(yōu)化是如何處理的?
答:用戶無需關(guān)注底層使用的具體推理引擎。我們在打包過程中將運行內(nèi)容分為三個部分:軟件包、環(huán)境包和數(shù)據(jù)集(通常是模型)。上傳時,我們會對模型進(jìn)行預(yù)處理,轉(zhuǎn)換成適用于各種 GPU 卡的版本,并對其進(jìn)行性能優(yōu)化。這一切都是自動完成的,用戶只需提供輸入?yún)?shù)。
Q8:推理引擎通用接口
問:不同推理引擎的特性(如 Dynamic Batch、Attention 機制)是否通過通用接口封裝?
答:當(dāng)前并不是所有推理任務(wù)都使用 TFCC,但我們計劃未來增加支持。最常用的接口只需要提供輸入形狀等基本信息。對于不同推理引擎的特性,我們正在考慮如何通過通用接口進(jìn)行適配,但目前尚未完全封裝。
Q9:Ray 聯(lián)邦集群間的通信
問:騰訊內(nèi)部的 Ray 聯(lián)邦集群是否實現(xiàn)了分布式共享內(nèi)存的打通?不同 Ray serve 之間是否可以直接通信?
答:不同 requester 之間的對象無法直接獲取。要訪問其他 requester 的對象,只能通過 API 接口進(jìn)行間接訪問。
Q10:TFCC 與顯存管理
問:TFCC 是否實現(xiàn)了顯存的分布式管理?
答:目前還未實現(xiàn)。