













云原生可觀測平臺 OpenObserve 初體驗

OpenObserve 是一個 Rust 開發的開源的高性能云原生可觀測平臺(日志、指標、追蹤),比起 Elasticsearch 它大約可以節省 140 倍的存儲成本,OpenObserve 能夠處理 PB 級的數據,如果你正在尋找一個用于日志、指標、追蹤的可觀測工具,那么 OpenObserve 是非常值得嘗試的。OpenObserve 雖然目前處于 alpha 階段,但其實也進行了廣泛的測試。
OpenObserve 與 Elasticsearch 的比較
Elasticsearch 是一個通用搜索引擎,可以使用應用程序搜索或日志搜索。OpenObserve 是專門為日志搜索而構建的,如果你正在尋找 Elasticsearch 的輕量級替代品,那么您應該看看 ZincSearch,如果只是想要一個日志搜索引擎,那么 OpenObserve 是一個非常好的選擇。
OpenObserve 不依賴于數據索引,它將未索引的數據以壓縮格式存儲在本地磁盤或以 parquet 列格式的對象存儲中。這使得數據攝取期間的計算要求大大降低,并且壓縮率非常高,從而使存儲成本降低約 140 倍。沒有數據索引意味著全掃描搜索可能比 Elasticsearch 慢,但由于分區和緩存等多種其他技術,仍然應該很快。Uber 發現其生產環境中 80% 的查詢是聚合查詢,而 OpenObserve 的列式數據存儲意味著聚合查詢通常比 Elasticsearch 快得多。
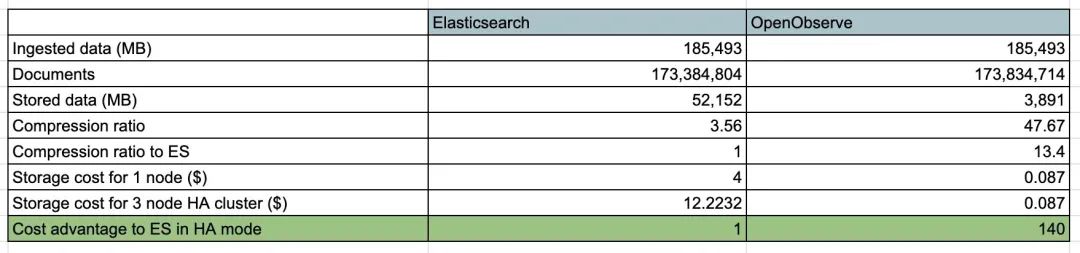
下面是我們使用 Fluentbit 將真實日志數據從 Kubernetes 集群發送到 Elasticsearch 和 OpenObserve 時的結果,這只與存儲有關。EBS 卷的成本為 8 美分/GB/月 (GP3),s3 的成本為 2.3 美分/GB/月。在 Elasticsearch 的 HA 模式下,通常有 1 個主節點和 2 個副本。無需復制 s3 來實現數據持久性/可用性,因為 AWS 會將你的對象冗余存儲在 Amazon S3 區域中至少三個可用區 (AZ) 的多個設備上。
OpenObserve VS Elasticsearch
在上述場景中,OpenObserve 具有比 Elasticsearch 低 140 倍的存儲成本的顯著優勢,這甚至沒有考慮額外未使用的 EBS 卷容量(為了不耗盡磁盤空間而需要提供這些容量)以及持續監控磁盤使用情況以使其不被填滿所需的工作。
無狀態節點架構允許 OpenObserve 水平擴展,而無需擔心數據復制或損壞。與 Elasticsearch 相比,您通常會發現管理 OpenObserve 集群的運維工作量和成本要低得多。
OpenObserve 內置的圖形用戶界面消除了對 Kibana 等其他組件的需求,而且由于 Rust 的優勢,性能出色,而無需面對 JVM 所帶來的問題。
與 Elasticsearch 相比,Elasticsearch 是一個通用性的搜索引擎,同時也兼具觀測工具的功能。而 OpenObserve 是從頭開始構建的觀測工具,非常注重提供優秀的可觀測性能。
架構
OpenObserve 可以在單節點下運行,也可以在集群中以 HA 模式運行。
單節點模式
單節點模式也分幾種架構,主要是數據存儲的方式不同,主要有如下幾種:
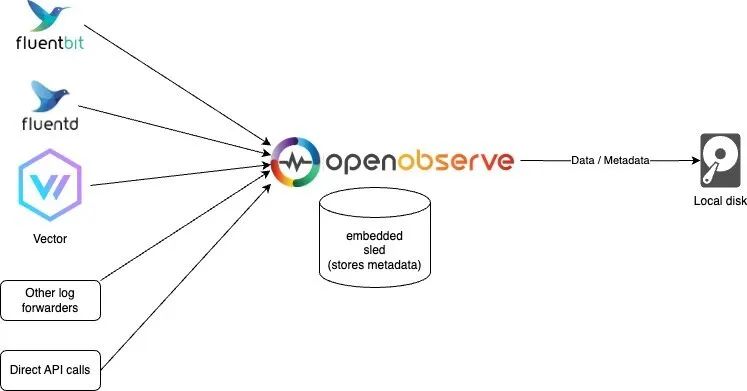
Sled 和本地磁盤模式
如果你只需要進行簡單使用和測試,或者對高可用性沒有要求,可以使用此模式。當然你仍然可以在一臺機器上每天處理超過 2 TB 的數據。在我們的測試中,使用默認配置,Mac M2 的處理速度為約 31 MB/秒,即每分鐘處理 1.8 GB,每天處理 2.6 TB。該模式也是運行 OpenObserve 的默認模式。
Sled本地模式
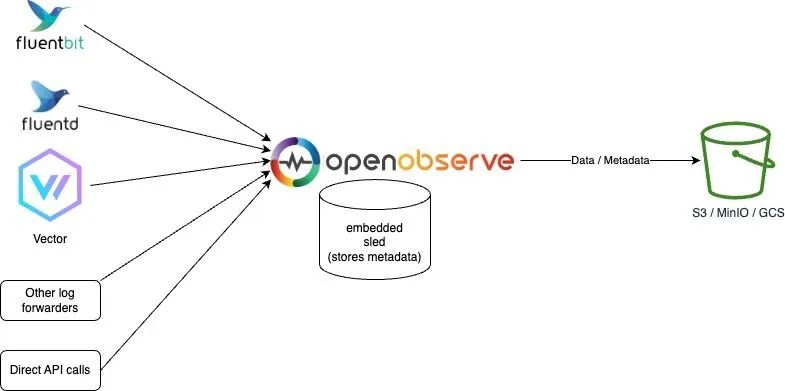
Sled 和對象存儲模式
該模式和 OpenObserve 的默認模式基本上一致,只是數據存在了對象存儲中,這樣可以更好的支持高可用性,因為數據不會丟失。
Sled對象存儲模式
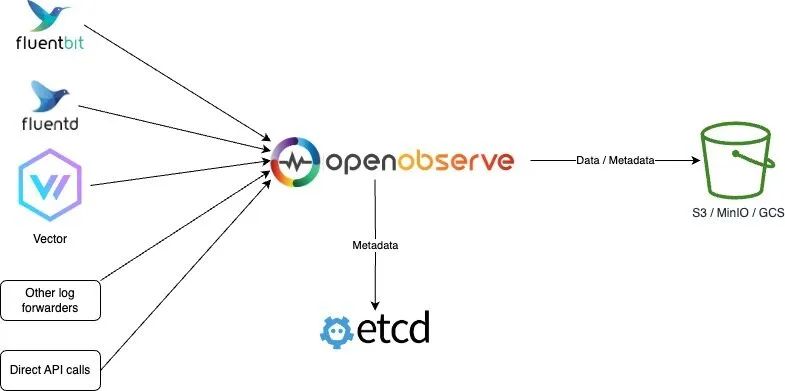
Etcd 和對象存儲模式
該模式是使用 Etcd 來存儲元數據,數據仍然存儲在對象存儲中。
Etcd對象存儲模式
HA 模式
HA 模式不支持本地磁盤存儲,集群模式下 OpenObserve 會運行多個節點,每個節點都是無狀態的,數據存儲在對象存儲中,元數據存儲在 Etcd 中,這樣可以更好的支持高可用性,因為數據不會丟失。
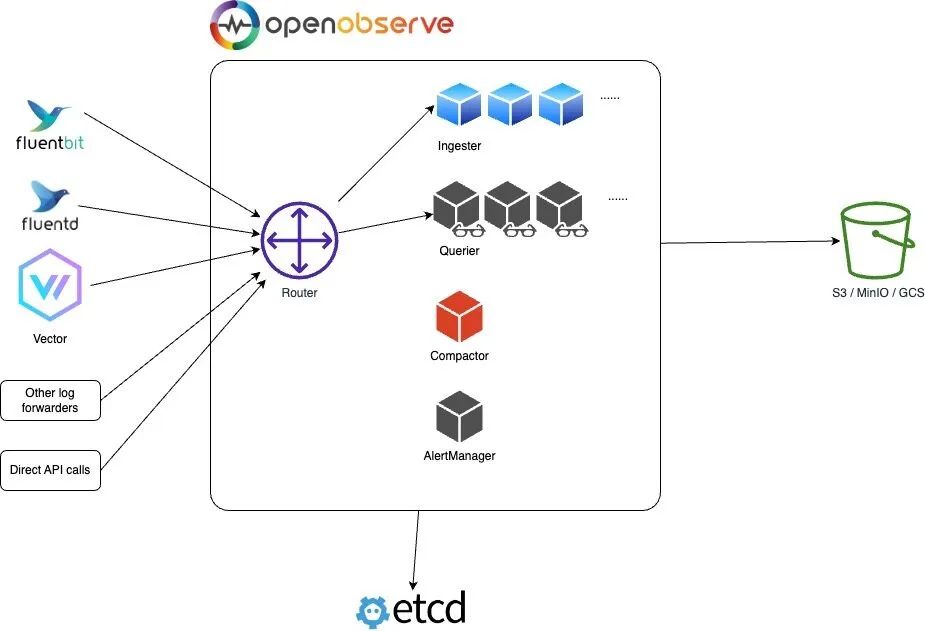
Etcd對象存儲
在該模式下 OpenObserve 主要包括 Router、Querier、Ingester 和 Compactor 四個組件,這些組件都可以水平擴展;Etcd 用于存儲用戶、函數、報警規則和集群節點信息等元數據;對象存儲(例如 s3、minio、gcs 等等)存儲 parquet 文件和文件列表索引的所有數據。
- Router:Router 路由器將請求分發給 ingester 或 querier,它還通過瀏覽器提供 UI 界面。Router 實際上就是一個非常簡單的代理,用于在數據攝入程序和查詢程序之間發送適當的請求并進行響應。
- Ingester:Ingester 用于接收攝取請求并將數據轉換為 parquet 格式然后存儲在對象存儲中,它們在將數據傳輸到對象存儲之前將數據臨時存儲在 WAL 中。
- Querier:Querier 用于查詢數據,查詢器節點是完全無狀態的。
- Compactor:Compactor 會將小文件合并成大文件,使搜索更加高效。Compactor 還處理數據保留策略、full stream 刪除和文件列表索引更新。
安裝
OpenObserve 的安裝非常簡單,只需要下載二進制文件即可,它支持 Linux、Windows 和 MacOS,也支持 Docker 鏡像。我們這里當然還是將其安裝到 Kubernetes 集群中,為簡單這里我們直接使用默認的 Sled 和本地磁盤模式。
首先創建一個命名空間:
$ kubectl create ns openobserve然后創建如下所示的資源清單文件:
# openobserve.yaml
apiVersion: v1
kind: Service
metadata:
name: openobserve
namespace: openobserve
spec:
clusterIP: None
selector:
app: openobserve
ports:
- name: http
port: 5080
targetPort: 5080
---
# create statefulset
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: openobserve
namespace: openobserve
labels:
app: openobserve
spec:
serviceName: openobserve
replicas: 1
selector:
matchLabels:
app: openobserve
template:
metadata:
labels:
app: openobserve
spec:
securityContext:
fsGroup: 2000
runAsUser: 10000
runAsGroup: 3000
runAsNonRoot: true
containers:
- name: openobserve
image: public.ecr.aws/zinclabs/openobserve:latest
env:
- name: ZO_ROOT_USER_EMAIL # 指定管理員郵箱
value: root@example.com
- name: ZO_ROOT_USER_PASSWORD # 指定管理員密碼
value: root321
- name: ZO_DATA_DIR
value: /data
imagePullPolicy: Always
resources:
limits:
cpu: 4096m
memory: 2048Mi
requests:
cpu: 256m
memory: 50Mi
ports:
- containerPort: 5080
name: http
volumeMounts:
- name: data
mountPath: /data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
storageClassName: cfsauto # 指定一個可用的存儲類
resources:
requests:
storage: 10Gi上面的資源清單中,我們使用了一個 StatefulSet 來創建 OpenObserve,需要注意的是需要配置 ZO_ROOT_USER_EMAIL 和 ZO_ROOT_USER_PASSWORD 兩個環境變量用來指定管理員郵箱和密碼。然后在 PVC 模板中指定一個可用的 StorageClass,用于持久化存儲數據。
然后直接應用上面的資源清單文件即可:
$ kubectl apply -f openobserve.yaml
$ kubectl get pods -n openobserve
NAME READY STATUS RESTARTS AGE
openobserve-0 1/1 Running 0 2m31s
$ kubectl get svc -n openobserve
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
openobserve ClusterIP None <none> 5080/TCP 2m52s快速使用
創建后我們可以查看一下 OpenObserve 的日志來驗證是否啟動成功:
$ kubectl logs -f openobserve-0 -n openobserve
[2023-08-04T10:18:06Z INFO openobserve] Starting OpenObserve v0.5.1
[2023-08-04T10:18:06Z INFO openobserve::service::db::user] get; org_id=Some("default") name="root@example.com"
[2023-08-04T10:18:06Z INFO tracing::span] set;
[2023-08-04T10:18:06Z INFO openobserve::service::db::user] Users Cached
# ......
[2023-08-04T10:18:06Z INFO openobserve::common::meta::telemetry] sending event OpenObserve - Starting server
[2023-08-04T10:18:07Z INFO actix_server::builder] starting 4 workers
[2023-08-04T10:18:07Z INFO actix_server::server] Tokio runtime found; starting in existing Tokio runtime
[2023-08-04T10:18:07Z INFO openobserve] starting HTTP server at: 0.0.0.0:5080, thread_id: 0
[2023-08-04T10:18:07Z INFO openobserve] starting HTTP server at: 0.0.0.0:5080, thread_id: 0
[2023-08-04T10:18:07Z INFO openobserve] starting HTTP server at: 0.0.0.0:5080, thread_id: 0啟動后我們可以通過 kubectl port-forward 命令將 OpenObserve 的 5080 端口映射到本地,然后在瀏覽器中訪問 http://localhost:5080 即可看到 OpenObserve 的 UI 界面。
$ kubectl port-forward svc/openobserve 5080:5080 -n openobserve
Forwarding from 127.0.0.1:5080 -> 5080
Forwarding from [::1]:5080 -> 5080
OpenObserve Login
使用上面指定的管理員郵箱和密碼即可登錄,然后就可以看到 OpenObserve 的主界面:
OpenObserve Web
因為現在還沒有數據,所以頁面中沒有任何內容,在 ingestion 頁面提供了 Logs、Metrics、Traces 數據的各種攝取方法:
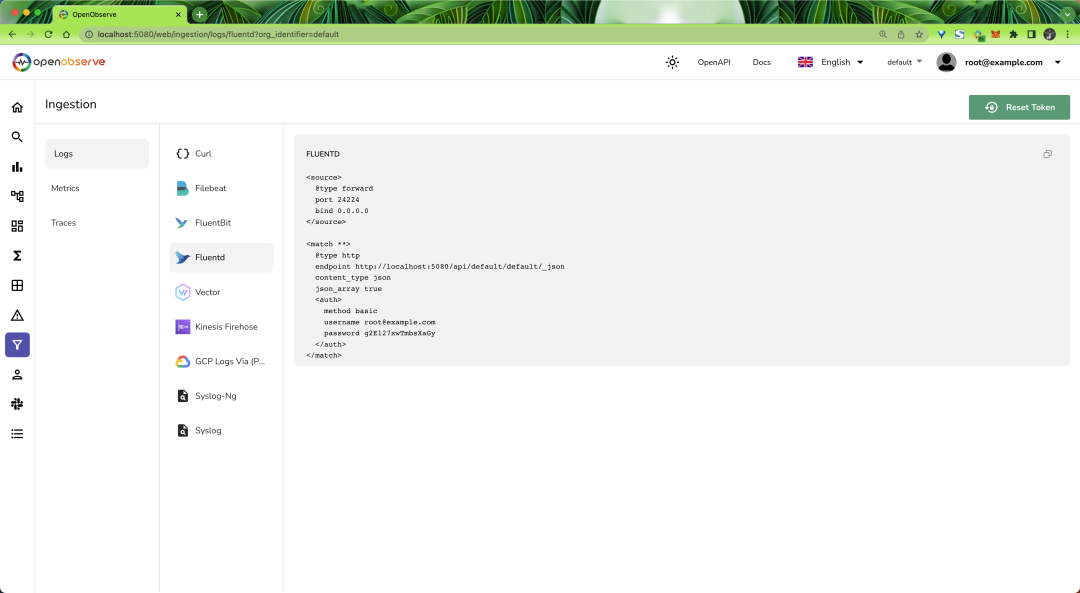
Ingestion
這里我們可以先使用 JSON API 來加載一些示例日志數據來了解一下 OpenObserve 的使用方法。先使用下面命令下載示例日志數據:
$ curl -L https://zinc-public-data.s3.us-west-2.amazonaws.com/zinc-enl/sample-k8s-logs/k8slog_json.json.zip -o k8slog_json.json.zip
$ unzip k8slog_json.json.zip然后使用下面命令將示例日志數據導入到 OpenObserve 中:
$ curl http://localhost:5080/api/default/default/_json -i -u "root@example.com:root321" -d "@k8slog_json.json"
HTTP/1.1 100 Continue
HTTP/1.1 200 OK
content-length: 71
vary: Origin, Access-Control-Request-Method, Access-Control-Request-Headers
content-type: application/json
date: Fri, 04 Aug 2023 10:46:46 GMT
{"code":200,"status":[{"name":"default","successful":3846,"failed":0}]}%收據導入成功后,刷新頁面即可看到有數據了:
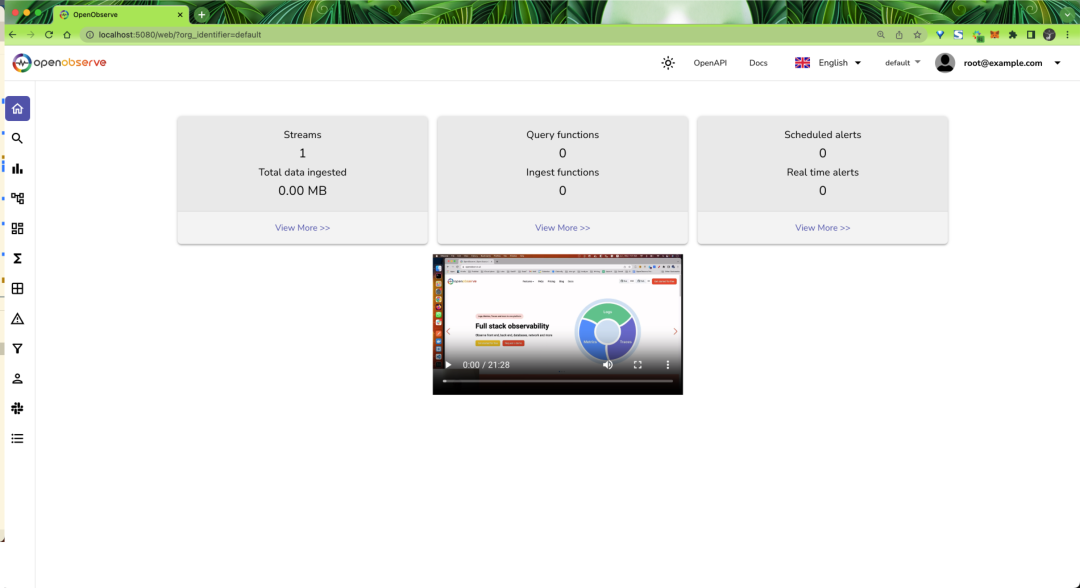
OpenObserve Web
在 Stream 頁面可以看到我們導入的數據元信息:
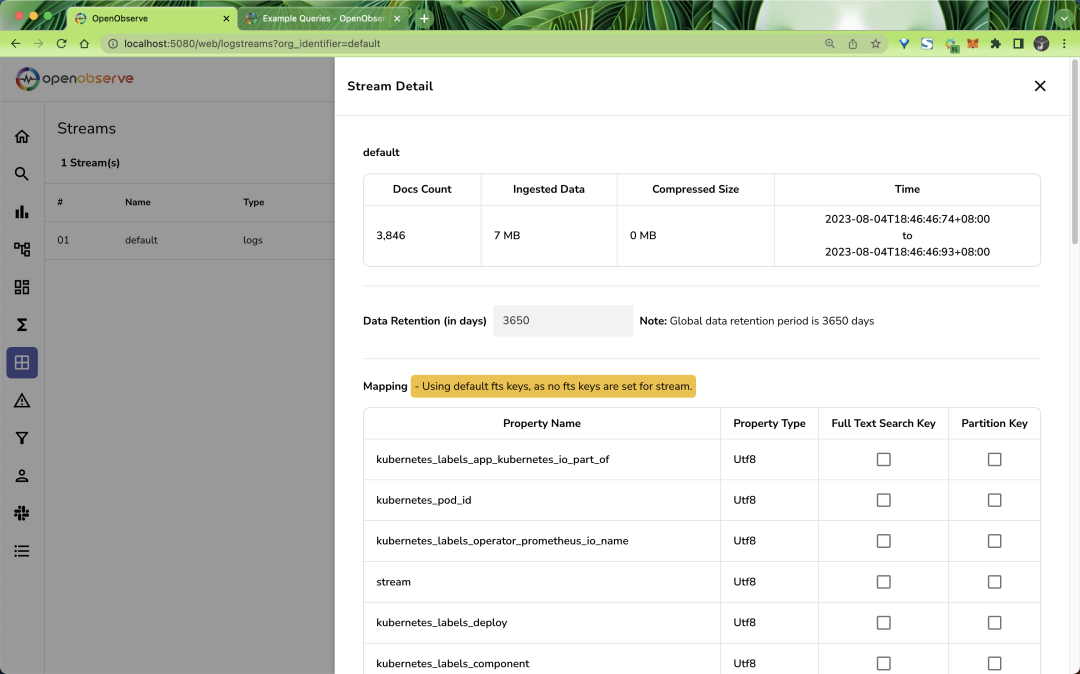
Stream流
然后可以切換到 Logs 頁面就可以看到日志數據了:

OpenObserve Logs
現在我們就可以去根據直接的需求去查詢日志了,常用的一些查詢語法如所示:
- 對于值 error 的全文搜索,在查詢編輯器中使用 match_all('error')
- 對于值 error 的不區分大小寫的全文搜索,使用 match_all_ignore_case('error')
- 對于值 error 的列搜索,使用 str_match(fieldname, 'error'),這比 match_all 更有效,因為它在單個字段中搜索。
- 要搜索 code 列的值 200,使用 code=200
- 要搜索列 stream 列的值為 stderr,使用stream='stderr'
- 要在日志 log 列上搜索和使用查詢函數extract_ip,使用 extract_ip(log) | code=200
當然除了日志之外,OpenObserve 還支持指標和追蹤數據,這里就不再演示了,有興趣的可以自己去嘗試一下。
這里我們只是簡單的演示了一下 OpenObserve 的日志方面的使用方法,后續我們可以使用 Fluentbit、Vector 之類的工具來將 Kubernetes 集群中的日志數據發送到 OpenObserve 中,敬請期待!
參考文檔:https://openobserve.ai/docs




















