攜程度假基于 RPC 和 TypeScript 的 BFF 設計與實踐
作者簡介
工業聚,攜程高級前端開發專家,react-lite, react-imvc, farrow, remesh 等開源項目作者,專注 GUI 開發、框架設計、工程化建設等領域。
一、前言
隨著多終端的發展,前后端的數據交互的復雜性和多樣性都在急劇增加。不同的終端,其屏幕尺寸和頁面 UI 設計不一,對接口的數據需求也不盡相同。構建一套接口滿足所有場景的傳統方式,面對新的復雜性日益捉襟見肘。
在這個背景下,BFF 作為一種模式被提出。其全稱是 Backend for frontend,即為前端服務的后端。它的特點是考慮了不同端的數據訪問需求,并給予各端針對性的優化。
在這篇文章中,我們將介紹一種基于 RPC 和 TypeScript 的 BFF 設計與實踐。我們稱之為 RPC-BFF,它利用前后端都采用同一語言(TypeScript)的優勢,實現了其它 BFF 技術方案所不具備的多項功能,可以顯著提升前后端數據交互的性能、效率以及類型安全。
二、為什么會需要 BFF?
用發展的視角來看,業界存在的兩大趨勢催生了 BFF 模式:
- 硬件行業的多終端發展趨勢
- 軟件行業的微服務發展趨勢
其中,微服務化以及中臺化的趨勢,改變了后端團隊構建服務的方式。整個系統將按照領域模型分隔出多個微服務,這增強了各個服務的內聚性和可復用性的同時,也給下游的接口調用者增加了數據聚合的成本。
多終端的發展,又讓數據聚合的需求進一步多樣化。使得處于微服務和多終端之間的團隊,不管是前端團隊還是后端團隊,他們面對的問題日趨復雜化。

系統復雜度的增加,將體現在代碼復雜度和團隊協作復雜度上。這意味著,沒有采用有效手段應對復雜度的團隊,自身將成為產研流程中的瓶頸。他們既要面對上游多個微服務的聯調需求,又要應對下游多個端的數據消費需求;有更多的會議要參加,更多的需求文檔要讀,更多的代碼、單元測試和技術文檔要寫,然而敏捷開發模式的交付周期卻不隨之增加。
此時一般有兩個應對策略。一種是去掉數據聚合層,讓各個下游前端應用自行對接微服務接口,將聚合數據的業務邏輯轉移到前端,增加它們的代碼體積,拖慢其加載速度,同時顯著增加客戶端向服務端發起的請求數,達到拉低頁面渲染性能,破壞用戶體驗的效果。
另一種做法則是采用 BFF 模式,降低前后端數據交互的復雜度。微服務強調按領域模型分隔服務,BFF 則強調按終端類型分隔服務。將原本單個團隊處理“多對多”的復雜關系,轉變成多個團隊處理的“一對多”關系。因此,本質上,BFF 模式的優化方式是通過調整開發團隊在人力組織關系層面的職能分工而實現的。

也就是說,BFF 不是作為新技術用以提升生產力,而是通過改變生產關系去解放生產力。從單一團隊成為產研流程中的單點瓶頸,轉變成多個 BFF 研發團隊各自應對某一端的數據聚合需求。
這種轉變所爭取到的是增加人手以提升效率的空間。一個工作任務相耦合的研發團隊不能無限加人提效,但若能拆成多個研發團隊,則可以擴大每個子團隊的提效空間。當然,代價是團隊之間可能存在重復工作,只是相比效率瓶頸而言,這些問題可能不屬于現階段主要矛盾,值得取舍。
盡管 BFF 不是新技術,也不要求新技術,但不意味著不能引入新技術,或者引入新技術無法提效。我們仍可以用新技術去實現 BFF,解決因團隊拆分而產生的問題,收獲研發效率(生產力)和產研流程(生產關系)兩方面的提升。
接下來,我們先看一下實現 BFF 的幾種不同方式,然后介紹作為新技術出現的 RPC-BFF。
三、BFF 的實現方式
如前所述,BFF 是作為模式(Pattern)被提出,而非一種新技術。在技術層面上,任何支持服務端開發的語言和運行時,不管是 Java、Python、Go 還是 Node.js,都可以開發 BFF 服務。只要它們所實現的這個服務,是面向前端需求的。
BFF 的實現方式多種多樣,不僅跟技術選型有關,跟研發團隊的分工方式、職能邊界、協作流程等因素也息息相關。
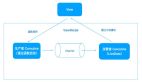
3.1 樸素模式
所謂的樸素模式,是指 BFF 的實現方式不改變前后端的分工方式、職能邊界和協作流程。前端不介入 BFF 層的實現,BFF 層的需求由后端團隊自行消化。
也就是說,BFF 在這里僅僅是后端團隊的內部分工:
- 開發微服務應用(后端團隊)
- 開發 BFF 服務(后端團隊)
- 消費 BFF 接口(前端團隊)
前端的工作方式跟之前一樣,后端負責開發 BFF 為前端團隊提供面向前端的數據聚合接口。開發 BFF 的編程語言由后端決定。

如上圖所示,紫框為研發團隊(前端或后端),藍框為 BFF 服務,黃框為前端應用,綠色箭頭表示“開發”,紫色箭頭表示“調用”。
在圖示中,BFF 按照終端尺寸分為 Mobile BFF 和 PC BFF 兩類,它背后的假設是:相近終端尺寸的前端應用擁有相近的數據訪問需求。移動端應用調用 Mobile BFF,PC 端應用調用PC BFF。
3.2 解耦模式
解耦模式,相比樸素模式而言,它改變了分工方式、職能邊界和協作流程。后端不介入 BFF 層的實現,BFF 層的需求由前端團隊自行消化。
也就是說,BFF 是前后端團隊共同完成的一種新的分工:
- 開發微服務應用(后端團隊)
- 開發 BFF 服務(前端團隊)
- 消費 BFF 服務(前端團隊)
前端的工作方式跟之前有所不同,前端團隊自己開發 BFF 服務以供自己的前端應用消費聚合好的數據。開發 BFF 的編程語言由前端決定。

如上圖所示,前端團隊同時開發了 App 及配套的 BFF 服務。前端開發的 BFF 服務背后調用了后端團隊提供的各個微服務接口,將它們聚合起來,轉換為前端應用可直接消費的數據形態。
3.3 樸素模式 VS 解耦模式
兩種模式都有其適用場景,具體要看不同研發團隊的人力資源、應用類型和技術文化風格等多個因素。
從技術發展的角度,解耦模式更能代表“徹底的前后端分離”的趨勢和目標。
前后端分離可以大體分為兩個階段:
- 渲染服務回歸前端團隊(SSR)
- 數據服務回歸前端團隊(BFF)
部分開發者可能認為完成了第一階段,就達到了前后端分離的目標。此時前端團隊可以自行構建SSR 服務器,更早介入渲染流程,不必等到瀏覽器加載頁面的 JavaScript 腳本后才開始發揮作用。不必再跟后端頻繁溝通,交代他們在 html 文件里添加指定的 id 或class 名;前端團隊可以全權處理,后端團隊只需要提供數據接口即可。
然而,“前后端分離”不只是把前端代碼(如 html 文件)從后端代碼倉庫轉移到前端代碼倉庫里,這只是形式和手段。前后端分離是指職能的分離,是為了讓前端研發人員不必低效率地遙控后端研發人員,讓他們去機械地調整面向前端需求的代碼。前端團隊可以自主負責、自主修改、快速迭代,專業的人做專業的事兒。
面向前端需求的代碼,不僅僅是 html 文件,也包括了面向渲染優化的數據聚合代碼。前端的職能是為用戶開發出體驗更好的 GUI 應用,有助于這個目標的所有合理的技術手段都在其職能范圍之內。
讓 SSR 服務從后端團隊轉到前端團隊,是為了得到面向前端需求的界面渲染優化空間。讓更加理解渲染優化原理的前端團隊,可以在 SSR 服務上應用新的渲染優化措施,包括但不限于 Streaming SSR、Suspense、Selective Hydration、Server Component 等技術可以得以應用。它們可以顯著提升頁面的各項性能指標,令用戶更早看到內容,更早看到有意義的內容,更早跟界面自由交互。
讓 BFF 服務從后端團隊轉到前端團隊,則是為了獲得面向前端需求的數據聚合優化空間,可以提高代碼的跨端復用率、減少前端應用的代碼體積、減少前端應用的加載時間,提升用戶體驗。
當研發團隊完成了 SSR 和 BFF 兩個階段的前后端分離后,前端團隊同時掌握了 SSR 和 BFF 兩重優化空間。他們既不需要讓后端團隊幫忙添加 id 和 class 到 html 文件中,也不需要讓他們幫忙把某個文案添加到某個接口里。面向前端的渲染優化需求和數據優化需求,都能在前端團隊職責范圍內自主解決,顯著減少前后端的溝通頻次和成本,分離彼此的關注度,提升雙方的專業聚焦水平。
更重要的是,SSR 和 BFF 在渲染優化上有著不可分割的關系。視圖的渲染不是憑空的,它依賴數據的準備,有意義的內容才得以呈現;當視圖需要流式渲染,數據請求也需要做相應配合。假設我們頁面的首屏所依賴的數據,都被聚合到一個單一接口里,其后果便是 Streaming SSR 無法發揮充分價值;所有組件都在等待單一聚合接口的響應數據,才開始進行渲染。

如上圖所示,紫色箭頭表示“時間”,粉色框為數據獲取,橙色框為組件渲染,綠色框為發送 HTML 到瀏覽器。我們可以看到,樸素的 SSR 是一個串行過程,組件渲染階段需要等待數據獲取全部結束。而充分的 Streaming SSR 則有多次數據獲取的并發任務(調用了多次后端接口),組件渲染并不需要等待所有數據獲取任務結束,只需相關數據就位即可進入組件渲染及后續發送 HTML 的流程。用戶可以更早看到內容。
在前端團隊缺乏 BFF 掌控能力的情況下,他們無法自主控制 SSR 的數據獲取過程,只能被動接受后端提供的接口。即便視圖層框架(如 React)支持 Streaming rendering,也僅僅是把一大塊 html 分多次發送給瀏覽器,它仍受制于 data-fetching 的阻塞時間,無法做到充分的 Streaming SSR。
因此,技術層面更合理的做法是,每個組件描述它自身所需的數據依賴,頁面渲染時遇到沒有數據依賴的靜態組件,立即發送給用戶,遇到有數據依賴的組件則發起請求(Render-As-You-Fetch),不同組件可以獨立發起不同請求,每個組件數據請求完畢后即刻開始自身渲染,最終得到頁面流式渲染,用戶漸進式地看到一塊塊成形的界面渲染的效果。
我們可以看到,在這個渲染優化需求下,傳統意義上的數據聚合思路(盡可能少的接口)反而是不利的;微服務式的多個接口,反而是有利的。當然,這不意味著前端直接對接微服務接口,不需要 BFF;這其實意味著我們需要 Streaming BFF 去解放 Streaming SSR 的潛力。
總的而言,徹底的前后端分離是指前端掌握了面向渲染優化的充分條件,包括 SSR 和 BFF 兩個彼此緊密關聯的優化空間,缺少任意一個,都難以獲得充分的渲染優化能力。從這個角度來看,前端團隊開發 BFF 是一個未來的技術方向。研發團隊的分工模式隨著技術發展,將從樸素模式逐漸轉向解耦模式。
四、解耦模式的 BFF 技術選型
解耦模式的 BFF 服務由前端團隊開發,所用的編程語言也由前端團隊決定。大部分情況下前端團隊會采用相同的編程語言(JavaScript/TypeScript),基于 Node.js 運行時開發相應的 BFF 服務。基于這個前提,我們討論幾種技術選型。
4.1 RESTful API
處于模仿階段的前端團隊,往往會采用 RESTful API 方式實現 BFF 服務。技術目標是把后端之前做但現在不做的功能,用同樣的方式和思路讓前端團隊用Node.js 實現一遍。
 實現 BFF 服務的前端開發人員,其心智模型跟普通后端無異,涉及 URL,HttpRequest, HttpResponse, RequestHeader, Query, Body, Cookie, Authorization, CORS,Service, Controller 等等。
實現 BFF 服務的前端開發人員,其心智模型跟普通后端無異,涉及 URL,HttpRequest, HttpResponse, RequestHeader, Query, Body, Cookie, Authorization, CORS,Service, Controller 等等。
然而,即便是現在,掌握成熟后端接口開發能力的前端開發人員,依舊是稀缺的。所以,往往這種方式開發的 BFF 服務的質量,劣于專業后端開發的,并且幾乎不考慮面向前端的極致優化,能滿足需求已經達到了目標。
此外,從語義角度看,RESTful API 是面向資源的,跟面向前端需求的 BFF 場景并不契合。很多時候,前端需要的數據并不是后端資源的直接映射,而是經過聚合、轉換、過濾、排序等處理后的結果。
因此,一開始基于 RESTful API 開發的 BFF 服務,最終將有意或無意、主動或被動地演變成只有一半功能的 RPC 服務。它的 url 參數設計是函數語義,而非資源語義,但調用這些遠程函數時仍然要考慮 server-client 之間底層通訊細節。既沒有被封裝,也缺少優化。
4.2 GraphQL
GraphQL是一個面向前端數據訪問優化的數據抽象層,它相當適合作為 BFF 技術選型,并且也是我們之前包括現在仍在使用的 BFF 方案。

它的技術特點是,在數據訪問層實現了一定的控制反轉(Inversion of control,IOC)的能力。
GraphQL 服務的開發者負責構建一個數據網絡結構(Graph),支持其消費者根據自身需求編寫 GraphQL Query 語句查詢所需 JSON 數據(Tree)。這種靈活的查詢能力,實際上是將前后端數據交互相關的代碼分成了兩部分,一部分是關于通用性的,放在數據提供方(GraphQL 服務)里,一部分是關于特殊性的,放在數據消費方(前端應用的查詢語句)里。
如此,GraphQL BFF 可以將按終端尺寸分類的多個 BFF 整合成一個 BFF。從之前Mobile BFF 和 PC BFF,變成統一的GraphQL BFF。減少了兩個 BFF 之間重復的部分。
- Mobile BFF = GraphQL BFF + Mobile GraphQL Query
- PC BFF = GraphQL BFF + PC GraphQL Query
通過統一的 GraphQL-BFF 配合差異的 *-GraphQL-Query 實現了之前多個 BFF服務提供的數據訪問能力。
前端團隊開發 GraphQL BFF 應用時,其心智模型不再是純粹的后端概念,而是 GraphQL 相關的概念,如 Schema, Query, Mutation, Resolver,DataLoader, Directive, SelectionSet 等等,它們更加利于前后端數據訪問的優化。更多詳情可以閱讀另一篇文章《GraphQL-BFF:微服務背景下的前后端數據交互方案》。
4.3 RPC
RPC 是指 Remote Procedure Call,即遠程過程調用。這個模式也適用于 BFF 服務的實現。

它的技術特征是,將實現端和調用端之間的通訊過程封裝,作為技術細節隱藏起來,并不暴露給調用者。對于調用者而言,仿佛像調用本地函數。
正因如此,它不要求調用一次 RPC 函數即發起一次獨立的通訊過程。它可以將多次 RPC 函數批量化(Batching)并流式響應(Streaming),進一步減少反復重建通訊過程的開銷。
前端團隊基于 RPC 模式開發 BFF時,其心智模型跟開發傳統后端服務不同。所謂的接口設計,被轉化為函數參數設計和返回值設計,沿襲了前端開發者熟悉的標準編程語言特性。相比 RESTful API 和 GraphQL 而言,RPC 引入更少概念和領域知識要求。
4.4 GraphQL VS RPC
我們團隊從四年前開始使用 GraphQL-BFF,并成功落地到多個項目,取得了不錯的效果。我們看到了它帶來的好處和價值,同時也發現了它當前的一些局限性。為了突破桎梏,爭取到更廣闊的優化空間,我們開始探索 RPC-BFF 方案,并試圖克服 GraphQL-BFF 方案未能解決的問題。
值得提醒的是,本文提到的 GraphQL-BFF 面臨的難題,是在精益求精的層面上的探討,并非否定和質疑 GraphQL 作為 BFF 方案的合理性。
GraphQL-BFF 的第一個難題是類型問題。GraphQL 是一個跨編程語言的數據抽象層,它自帶了一套 Type System。使用具體某個帶類型的編程語言(如 TypeScript)開發 GraphQL 服務時,就存在兩個類型系統,因此難免有一些語言特性無法對齊以及類型重復定義的地方。

比如,GraphQL 的類型系統支持代數數據類型(Algebraic data type),可以用 union 定義 A 或 B 的類型關系。這在 Rust和 TypeScript 中有不錯的支持,在 Java 或 Go 中還沒有直接的支持。然而即便是 TypeScript,很多類型聲明也得在 GraphQL 和 TypeScript 中分別定義一份。
此外,GraphQL 的 Client-side 類型問題也是一個挑戰。由于 GraphQL 服務的返回值取決于發送過來的查詢語句,因此其響應的數據類型不是固定的,而是隨著查詢語句代碼的修改而變化的。
盡管 GraphQL 由于提供了內省機制(Introspection),可以構建出專門根據 GraphQL Schema + GraphQL Query 生成 TypeScript 類型定義的 Code Generator 工具。但其中包含很多手動處理或復雜的工程化配置環節。
開發者有可能需要手動從 TypeScript 代碼里復制出 GraphQL Query 語句,在 GraphQL Code Generator 工具里生成 TypeScript 類型后,復制該類型定義到項目中,然后傳入 GraphQL Client 調用函數標記其返回值類型。
或者像 Facebook/Meta 公司推出的 Relay 框架那樣,實現一個 Compiler 去掃描代碼里的 GraphQL Query 語句,自動生成類型到指定目錄,讓開發者可以直接使用。這塊對研發團隊的技術能力和工程化水平有較高要求。
GraphQL-BFF 的第二個難題是,缺乏 Streaming 優化支持。當前的 GraphQL 數據響應,是由查詢語句中最慢的節點決定的,尚未支持已 resolved 的節點提前返回給調用端消費的能力。
雖然 GraphQL 有 @stream/@defer 相關的 RFC,但目前并未進入 GraphQL 規范中,也未在相關 GraphQL 庫中得到實現或推廣。
GraphQL-BFF 的第三個難題是缺少 Client-side Data-Loader 優化支持。
在 Server-side 的GraphQL 有相關 Data-Loader,支持在一次查詢請求處理過程中,相同資源的訪問可以被去重。但是在調用端,一次 GraphQL Query 就對應著一次 Http 請求與響應。多次 GraphQL Query 很難被自動 merge 和 batching,遑論 streaming 優化。
如前所述,為了渲染上的進一步優化,前端組件實踐的流行趨勢是,每個組件可以將自己的數據需求定義在自己的組件代碼中,而非托管給父級組件。如此,可以方便組件自身做 streaming 優化;當它自身的數據已經獲取完畢,它可以先行渲染,不必等待。
相關 GraphQL Client(如Relay)的處理辦法是,讓視圖組件用 GraphQL Fragment 而非 GraphQL Query 去表達數據需求。通過編譯器處理后,它們將可以提取到父級組件或者根組件里合并為 GraphQL Query。實現編寫時在組件內,運行時托管在父級組件中獲取數據。

這種策略在實踐上是可行的,然而既有較高的工程化門檻,難以普遍推廣,又不是 GraphQL 規范所定義的標準行為,甚至需要額外自定義很多指令以達到目標(如 Relay 框架的 @argument, @argumentDefinitions 等),這進一步損害了它的易用性。
我們需要的一種 BFF 技術方案是:
- 支持使用標準的語言特性解決問題
- BFF 實現端類型定義不必編寫兩份
- BFF 調用端可無縫復用 BFF 實現端的定義,不必重復定義
- 支持 Client-side Data-Loader 機制,可以將客戶端的多個數據訪問調用自動
- merging
- batching
- streaming
RPC-BFF 技術方案,可以滿足上述目標。
五、RPC-BFF 的技術選型
基于 RPC 實現 BFF 的思路和方案,也有很多種選擇。
5.1 gRPC
gRPC 是一個非常優秀的 RPC 技術方案,但它跟 GraphQL 一樣是跨編程語言的,需要額外使用一種 DSL 定義類型(Interface Definition Language,IDL),因此有類似的重復定義類型的問題,也未對前端常用語言(如TypeScript)做充分的針對性優化,并且它主要服務于分布式系統這類 server-to-server 的調用,對 client/ui-to-server 的 BFF 場景沒有特殊處理。
在很多基于 gRPC 的 BFF 實踐中,BFF 跟背后的領域服務之間是 RPC 模式,BFF 跟前端之間則回到 RESTful API 模式。而我們所謂的 RPC-BFF,其實是指前端和 BFF 之間是 RPC 模式的調用關系。
5.2 tRPC
tRPC 的設計目的則跟我們的目標更加貼合,它是基于 TypeScript 實現的端到端類型安全方案(End-to-end type-safe APIs)。
然而,tRPC 的技術實現方式,跟我們的需求場景卻不契合。
tRPC 跟前文的 Relay 框架某種意義上是兩個極端。Relay 框架完全依賴它的 Relay Compiler 去掃描代碼,充分分析和收集代碼里的 GraphQL 配置,有很多編譯、構建和代碼生成的環節。而 tRPC 則相反,它目前沒有構建、編譯和代碼生成的步驟,正如其官方文檔里所言:
tRPC has no build or compile steps, meaning no code generation, runtime bloat or build step.
tRPC 假設了開發者的項目是全棧項目(full-stack application),或者前后端代碼都在一個倉庫。

因此,前端項目可以直接 import 后端項目里的 TypeScript 類型。
如果我們構建的 BFF 項目,不只為了一個前端項目服務,而是多個前端項目共用的,涉及跨端、跨語言、跨團隊等復雜組合。使用 tRPC 時,可能就得采取 Monorepo 模式,把 BFF 項目及其所有調用方的代碼項目,放到一個 Git 倉庫中管理。這將顯著地增加多個團隊之間的 Git 工作流、CI/CD、研發和部署流程等多方面的協調問題,要求處理新的工程化復雜度(Monorepo),能滿足這個條件的團隊不多。
我們的場景所期望的技術方案是,允許 BFF 項目及各個下游前端項目在不同倉庫中管理,它們無法直接 import BFF 項目的類型,不滿足 tRPC 的項目假設。
5.3 DeepKit
DeepKit 是一個富有野心的項目,它在 TypeScript 基礎上增加了很多特性,力圖打造一個更加完備的 TypeScript 后端基礎設施。

它也有 RPC 模塊的部分,但出于以下幾個原因,最后未被我們選擇。
第一個原因是,DeepKit 的 RPC 實踐方式跟 tRPC 有類似的項目結構假設。

如上所示,rpc server 和 rpc client 之間需要有個共享的接口,一個負責實現該接口,一個負責消費該接口。這也要求前后端需要放到一個倉庫中。或者采用 npm 包這類更低效的代碼共享途徑,對庫和框架這種變動比較不頻繁的場景來說是合適的,對業務迭代這種更新頻率則難以接受。
另一個原因則是,選擇 DeepKit 并不是選擇一個庫或者框架這種小決策,它從編程語言開始侵入,然后到運行時以及庫和框架等方方面面。有較強的 Vendor lock-in 風險,一個項目要從 DeepKit 中遷移到另一個技術相當困難。
團隊需要下很大的決心才敢押注 DeepKit 選型,以 DeepKit 目前的完成度和流行度,還無法支撐我們做出這個決定。
5.4 自研 RPC-BFF
如前所述,我們深入分析了 RPC BFF 的優勢,以及考察了多個不同的技術選型。有的過于龐大、過分復雜,有的則過于簡單、過于局限。
但這些項目也啟發了我們的自研方向,幫助我們從簡單到復雜的光譜中,根據自身實際需求找到一個平衡點,可以用盡可能低的研發成本、盡可能小的侵入性、盡可能少的項目結構要求,實現 RPC-BFF 模式。
也就是說,我們既不要像 DeepKit 和 Relay 那樣,從完整的編譯器乃至編程語言層面切入到代碼生成和運行時,它們或許有更大的目標和野心,配得上如此高昂的技術成本和實現難度,但對純粹的 BFF 場景而言可能過猶不及。同時也不要像 tRPC 那樣完全沒有代碼生成,而是選擇一個最小化代碼生成的路線,滿足 RPC-BFF 這一聚焦場景的需求。
六、自研 RPC-BFF 的設計與實現
6.1 RPC-BFF 的設計思路
RPC-BFF 可以看作樸素 BFF 的拓展增強版。在樸素 BFF 中,后端在最簡陋的情況下只為前端提供了數據。
而 RPC-BFF 則需要做更多:提供數據、提供類型以及提供代碼。

如上圖所示,RPC-BFF 既是數據提供者(Data Provider),也是類型提供者(Type Provider),還是代碼提供者(Code Provider)。前端不必重復定義 BFF 響應的數據類型,也不必親自構造 Http 請求處理通訊問題。
要做到這些功能,同時又不能損害易用性,需要極致地挖掘 TypeScript 的類型表達能力。

上圖為 RPC-BFF 架構圖示意,其中存在四種顏色,分別的含義如下:
- 服務端運行時(server-runtime)為粉色,服務器代碼在此運行
- 類型編譯時(compile-time)為藍色,類型檢查在此進行
- CLI 運行時(cli-runtime)為黃色,本地開發階段使用的命令行工具
- 客戶端運行時(client-runtime)為紫色,前端代碼在此運行
該 RPC-BFF 架構設計的核心在于Schema 部分,它是一切的基礎。我們可以看到,Schema 有兩條箭頭,一條為 type infer,一條為 to JSON。也就是說,Schema 既作用于類型(type)所在的編譯時(compile-time),也作用于值(value)所在的運行時(runtime)。
當 BFF 端的代碼經過編譯,類型信息被編譯器抹除后,我們仍可以在運行時訪問到 JSON 數據結構表示的 Schema。
通過這種機制,我們的 RPC-BFF 像 GraphQL 那樣支持內省特性(introspection)。在開發階段,前端可以通過本地 CLI 工具向 RPC-BFF 發起內省請求(Introspection Request)拿到 JSON 形式的 Schema 結構,然后通過 Code Generator 生成前端所需的 Client 類型和 Client 代碼。
如此,我們既不需要用編譯器去掃描和分析服務端代碼以提取類型,也不需要用編譯器去掃描和分析前端代碼去生成類型。對于 RPC-BFF 來說,不需要掌握到圖靈完備的編程語言的所有信息才能工作,只需要掌握RPC 函數列表及其輸入和輸入類型結構即可。
6.2 RPC-BFF Schema 設計與實現
Schema 是一段特殊的代碼,它介于 Type 和 Program 之間,面向特定領域保留其所需的元數據性質的配置結構。Schema 往往比類型復雜,但比一般意義上的程序簡單。
不管是 tRPC 還是 GraphQL 都包含 Schema 性質的要素。然而,對于 RPC-BFF 的場景來說,它們分別都有能力的缺失。
tRPC 中的 Schema 是只起到了 Validator 和 Type-infer 的作用,而沒有 Introspection 機制。

如上所示,tRPC 自身沒有實現 schema 部分,但可以從開源社區的多個 schema-based validator 庫中選擇一個它目前支持的(如 zod),從而得到在 server runtime 對客戶端傳遞進來的參數驗證,以及在開發階段提供 type-infer 功能。
而 GraphQL 的情況則復雜一些,它分為 Schema-first 和 Code-first 兩類實踐方式。

Schema-first GraphQL 實踐如上圖所示,GraphQL Schema 以字符串的形式出現在 TypeScript/JavaScript 代碼中,它是 DSL 形態,要復用 host language(如 TypeScript)的類型系統相當困難。

Code-first/Code-only GraphQL 則如上圖所示,它是 eDSL 形態,即嵌入式領域特定語言(Embedded domain specific language),它可以基于 host language 的API 以程序的方式而非字符串的方式,創建出 GraphQL Schema。因此,這種模式下 GraphQL 相當于嵌入到 TypeScript 中,它有機會利用 TypeScript 的類型推導(type infer)能力,反推出 TypeScript 類型;也能夠在運行時 stringify 為 DSL 形態的 GraphQL Schema。
可以說,這種實踐方式的 GraphQL 跟 host language 的整合度更高,某種程度上是更靈活的,盡管犧牲了 DSL 那種直觀性。
然而,目前幾乎所有 Code-first/Code-only 的 GraphQL 庫的 TypeScript 類型支持程度都有很大的不足。特別是對 GraphQL 這種類型之間遞歸結構特別頻繁的技術來說,其類型推導的技術挑戰遠大于zod 等樸素 schema-based validator 庫。
即便是 zod 這類更簡單的場景,對遞歸類型也沒有充分支持。
You can define a recursive schema in Zod, but because of a limitation of TypeScript, their type can't be statically inferred. Instead you'll need to define the type definition manually, and provide it to Zod as a "type hint".
如 zod 官方文檔所述,當我們的 schema 中存在遞歸,type-infer 就受到了限制,需要更繁瑣的方式去自行拼裝出遞歸類型。
const baseCategorySchema = z.object({
name: z.string(),
});
type Category = z.infer<typeof baseCategorySchema> & {
subcategories: Category[];
};
const categorySchema: z.ZodType<Category> = baseCategorySchema.extend({
subcategories: z.lazy(() =>categorySchema.array()),
})如上所示,它需要先用 schema 方式定義遞歸類型(Category)中非遞歸的部分,然后用 type-infer 在 type-level 定義遞歸部分的類型,最后回到 schema-level 中顯式類型標注,定義遞歸 schema。
它在 schema-level 和 type-level 中來回穿梭。每一個遞歸字段都要求拆成上述 3 個部分,其工程上的易用性缺乏保障,其代碼也缺乏可讀性。有多少讀者能輕易看出上面的復雜 schema 是為了定義下面這幾行代碼?
type Category = {
name: string
subcategories: Category[]
}回到 GraphQL,我們現在能夠看到,它在 Validator 和 Introspection 特性上有良好的支持,可以在 server runtime 驗證參數結構和返回值,也可以通過內省請求曝露出schema 結構,但在 type-infer 上仍有一些難以攻克的挑戰存在。
RPC-BFF 的 Schema 需要同時滿足 Validator,Type-infer 和 Introspection 三個能力,現有方案并不滿足,因此我們通過自研 Schema方案實現了它們。
下面是一段定義 User 類型的TypeScript 代碼:
type UserType = {
id: string;
name: string;
age: number;
}
const user: UserType = {
id: 'user_id_01',
name: 'Jade',
age: 18
}經過編譯后,在運行時執行的 JavaScript 代碼如下:
"use strict";
const user = {
id: 'user_id_01',
name: 'Jade',
age: 18
};類型信息被抹去,在運行時無法獲取。通過 RPC-BFF Schema 重新定義 User 結構如下:

我們用 ObjectType 定義了User Schema,用 TypeOf 推導出UserType,經過 TypeScript 編譯后,JavaScript 代碼如下所示:
import { ObjectType } from '@ctrip/rpc-bff';
class User extends ObjectType {
constructor() {
super(...arguments);
this.id = String;
this.name = String;
this.age = Number;
}
}
const user = {
id: 'user_id_01',
name: 'Jade',
age: 18
};我們可以看到,由 ObjectType 定義的 User Schema 在運行時也得到了保留,因此我們可以基于這些信息,實現在運行時的 Validation 和 Introspection 功能。
此外,我們的 RPC-BFF Schema 技術還克服了 zod 等庫未能解決的遞歸類型定義問題:

我們無需為了支持遞歸而人為拆分類型,可以直觀地定義出上述的 Category 結構,并支持靜態類型推導。其秘訣在于利用 TypeScript 中 class 聲明具備的獨特性質—— value & type 二象性。
當我們用 class 聲明一個結構時,它同時也定義了:
- Constructor 函數值
- Instance Type 實例類型

如上圖所示,左邊箭頭的 Test 是一個實例類型(Instance Type),右邊箭頭的則是類的構造器函數(Constructor)。
目前就我們所知,只在 class 聲明場景下 TypeScript 對遞歸 Schema 有良好的類型推導支持。因此,如果 zod 或者 Code-first GraphQL 庫想要支持遞歸 Schema 結構,它們的 Schema API 可能需要大改,變成我們上面演示的 RPC-BFF Schema 的 API 風格。
盡管我們掌握了在 Validator, Type-infer 和 Introspection 能力上更完備的 Schema 技術,滿足了 Code-first GraphQL 的技術要求,但也僅限于 server 端的情況,在 client 端的類型,仍需要引入復雜的編譯技術掃描前端代碼庫里的 GraphQL Query 片段以生成類型。這不是我們期望的。
因此,我們目前先將這種技術應用于更簡單的 RPC-BFF 場景,未來也不排除支持 GraphQL。
6.3 定義 RPC-BFF 函數
有了 RPC-BFF Schema 之后,我們就可以用它來定義 RPC-BFF 函數了。
在純 TypeScript 的代碼里,定義函數的 input 和 output 是這樣的:
// 定義 input
type HelloInput = {
name: string
}
// 定義 output
type HelloOutput = {
message: string
}
type HelloFunction = (input: HelloInput) => HelloOutput然后實現滿足該函數類型的代碼:
const hello: HelloFunction = ({ name })=> {
return {
message: `Hello ${name}!`,
}
}在 RPC-BFF 里,我們只是換了一種方式去定義 input 和 output。
去掉注釋,并且引入 ObjectType,前面的 hello 函數就變成了這樣:
import { Api, ObjectType } from '@ctrip/rpc-bff'
class HelloInput extends ObjectType {
name = String
}
class HelloOutput extends ObjectType {
message = String
}
export const hello = Api(
{
input: HelloInput,
output: HelloOutput,
},
async ({ name }) => {
return {
message: `Hello ${name}!`,
}
},
)可以看到,它跟我們純 TypeScript 的結構幾乎是一樣的。
6.4 RPC 函數和普通函數的區別
RPC 函數和普通函數的區別在于,RPC函數的 input 和 output 都是 value,而普通函數的 input 和 output 都是 type。
type 會在編譯時被擦除,而value 會在運行時被保留。所以,RPC 函數的 input和 output 需要是 value,它們在運行時是可以被訪問到的。這樣可以為 RPC-BFF client 生成類型代碼和調用代碼。
盡管我們使用 value 的方式去定義RPC 函數的輸入和輸出,但通過 TypeScript 提供的type infer 能力,我們不必為 RPC 函數的實現重新寫一次類型定義,而是可以使用 TypeScript 的類型推導能力,讓 TypeScript 自動推導出 RPC 函數的輸入和輸出類型。

可以看到,我們的 hello 函數實現是有類型的。不僅如此,我們還可以通過 TypeOf 獲取到 Schema API 定義出來的結構。

通過這種方式,我們實現了 RPC 函數的輸入和輸出結構,具備以下能力:
可以在運行時保留,用以生成代碼或者生成文檔
可以在編譯時被隱式地推導出來,用以做類型檢查
可以通過 TypeOf 工具類型顯式地獲取到,用以做類型標記
現在,讓我們把 RPC-BFF 函數放到 RPC-BFF App 中:
import { createApp } from '@ctrip/rpc-bff'
import { hello } from './api/hello'
export const app = createApp({
entries: {
hello,
}
})createApp 將創建一個 RPC-BFF App,其中 options.entries 字段就是我們想要曝露給前端調用的 RPC-BFF 函數列表。
啟動后,一個 RPC-BFF Server 就運行起來了。
6.5 RPC-BFF 的 Client
在前端項目的開發階段,它將會新增 rpc.config.js 配置腳本。
rpc.config.js
const { createRpcBffConfig } = require('@ctrip/rpc-bff-cli')
module.exports = createRpcBffConfig({
client: {
rootDir: './__generated__/',
list: [
{
src: 'http://localhost:3001/rpc_bff',
dist: 'my-bff-client.ts',
}
]
}
})如上所示,當該腳本被 rpc-bff-cli 運行時,它會向 src 發起 introspection request 并生成代碼到指定目錄下的指定文件(如 my-bff-client.ts)。
就我們前面所演示的 hello 函數來說,其生成的代碼大概如下所示:
./__generated__/my-bff-client.ts
/**
* This file is auto generated by rpc-bff-client
* Please do not modify this file manually
*/
import { createRpcBffLoader } from '@ctrip/rpc-bff-client'
export type JsonType =
| number
| string
| boolean
| null
| undefined
| JsonType[]
| { toJSON(): string }
| { [key: string]: JsonType }
/**
* @label HelloInput
*/
export type HelloInput = {
name: string
}
/**
* @label HelloOutput
*/
export type HelloOutput = {
message: string
}
export type ApiClientLoaderInput = {
path: string[]
input: JsonType
}
declare global {
interface ApiClientLoaderOptions {}
}
export type ApiClientOptions = {
loader: (input: ApiClientLoaderInput,
options?: ApiClientLoaderOptions) => Promise<JsonType>
}
export const createApiClient = (options: ApiClientOptions) => {
return {
hello: (input: HelloInput,
loaderOptions?: ApiClientLoaderOptions) => {
return options.loader(
{
path: ['hello'],
input: input as JsonType,
},
loaderOptions
) as Promise<HelloOutput>
}
}
}
export const loader = createRpcBffLoader("http://localhost:3001/rpc_bff")
export default createApiClient({ loader })我們可以看到,RPC-BFF 的代碼生成結果主要包含三個部分:
- RPC-BFF Server 里的 Schema 變成了前端里的 Type,將在編譯后被擦除,不會增加前端代碼體積
- RPC-BFF Server 里的 entries 變成了 createApiClient 函數,包含了跟 BFF 端對齊的函數調用列表及其類型信息
- RPC-BFF Client 被引入和實例化,它將在前端的運行時接管 RPC 函數的前后端通訊過程,對前端調用者無感
通過 Introspection + Code-generator 途徑,一個 RPC-BFF 服務不必跟它的下游前端項目綁定,而是每個前端項目通過 rpc.config.js 各自同步它們所需的 RPC-BFF 服務。如此解耦了前后端的項目依賴,同時這個模式在 Monorepo 項目中也能很好地工作,是一種更加靈活的方式。
七、RPC-BFF 特性概覽
至此,我們了解到了 RPC-BFF 的后端和前端分別的開發方式,可以看到對于 RPC-BFF 服務的開發者來說,并沒有引入復雜的 API 或者概念,僅僅是在編寫樸素函數的心智模型的基礎上,將定義函數輸入和輸出結構的方式,從樸素的 Type 換成了 RPC-BFF Schema。
對于 RPC-BFF 服務的調用方而言,只是增加了 rpc.config.js 配置腳本,在開發階段就能得到 RPC-BFF 的類型及其 Client 封裝,用極小的成本獲得極大便利。
但這仍不是 RPC-BFF 的優勢的全部,接下來,我們來了解一下 RPC-BFF 的幾大特性。
7.1 端到端類型安全的函數調用
端到端類型安全(End to end type-safety)的函數調用是 RPC-BFF 的基本功能,前端通過生成的 RPC-BFF Client 模塊訪問 RPC-BFF Server 時,像調用本地異步函數一樣。

如上所示,BFF 后端和前端的類型對齊。前端不必關心底層 HTTP 通訊細節,可以聚焦 RPC 函數的 input 和 output 結構。

當 RPC 函數執行時,它將發起 HTTP 請求,將所調用的 RPC 函數的路徑(path)和輸入(input)等信息打包發送給 RPC-BFF Server。

RPC-BFF Server 接受到 RPC 函數調用請求后,將匹配出指定函數并以 input 參數調用它得到其 output 結果后發送給前端,前端收到響應結果后,RPC-BFF Client 將其轉換為前端 RPC 調用函數的返回值。整個 RPC 過程的前后端流程就完成了。
7.2 直觀的錯誤處理
前面介紹的 RPC 調用只涉及請求正確處理和返回的情況,如果服務端報錯了,前端如何處理呢?
對于這個問題,RPC-BFF 也有其優勢。不同于樸素的接口請求錯誤處理,需要去判斷 HTTP Status Code 檢查請求狀態碼是否正確,甚至還得判斷 result.code 檢查業務狀態碼是否正確等等。
RPC-BFF 的錯誤處理支持最直觀和自然的 throw 和 try-catch 特性。在 RPC-BFF Client 中可以 catch 到 RPC-BFF Server 里 throw 的錯誤。

如上,改造我們的 hello 函數,當它遇到空的 name 參數時 throw 指定錯誤。

前端則構造一個空的 name 參數,并 try-catch 此次 RPC 調用,它將能捕獲服務端拋出的錯誤。

再次執行后,從 Chrome Devtools 的 Network 面板中,我們看到了標記為錯誤的 RPC 響應結果。

在 Console 面板中,我們則看到了前端 catch 到的 RPC 調用錯誤日志輸出。
7.3 代碼即文檔
RPC-BFF 從 GraphQL-BFF 中學習到了很多優秀之處。在 GraphQL 中,可以基于其 Schema 的 Introspection 能力,構建 GraphQL Playground 平臺,可以在其中查看接口的參數類型、字段描述等信息,還能發起查詢,相當方便。
RPC-BFF 的 Schema 也擁有 Introspection 能力,因此我們可以為前端提供更多內容。
export class Todo extends ObjectType {
id = {
description: `Todo id`,
[Type]: Int,
}
content = {
description: 'Todo content',
[Type]: String,
}
completed = {
description: 'Todo status',
[Type]: Boolean,
}
}
export class AddTodoInput extends ObjectType {
content = {
description: 'a content of todo for creating',
[Type]: String,
}
}
export class AddTodoOutput extends ObjectType {
todos = {
description: 'Todo list',
[Type]: TodoList,
}
}
export const addTodo = Api(
{
description: 'add todo',
input: AddTodoInput,
output: AddTodoOutput,
},
(input) => {
state.todos.push({
id: state.uid++,
content: input.content,
completed: false,
})
return {
todos: state.todos,
}
},
)如上所示,我們在定義 addTodo 接口的 input schema 和 output schema 時,不僅僅提供了對應的類型,還添加了相關的 description 描述。
經過前端的代碼生成后,將得到如下代碼:
/**
* @label Todo
*/
export type Todo = {
/**
* @remarks Todo id
*/
id: number,
/**
* @remarks Todo content
*/
content: string,
/**
* @remarks Todo status
*/
completed: boolean
}
/**
* @label AddTodoInput
*/
export type AddTodoInput = {
/**
* @remarks a content of todo for creating
*/
content: string
}
/**
* @label AddTodoOutput
*/
export type AddTodoOutput = {
/**
* @remarks Todo list
*/
todos: (Todo)[]
}
export const createApiClient = (options: ApiClientOptions) => {
return {
/**
* @remarks add todo
*/
addTodo: (input: AddTodoInput, loaderOptions?: ApiClientLoaderOptions) => {
return options.loader(
{
path: ['addTodo'],
input: input as JsonType,
},
loaderOptions
) as Promise<AddTodoOutput>
},
}
}相比文本形式的接口契約文檔,RPC-BFF 通過注釋的方式將接口描述信息呈現出來。

如上所示,生成到注釋的方式,比樸素的接口契約更貼近開發者,可以在代碼編輯器里直觀地看到接口描述和類型描述,并且基于開發階段的同步機制,它總是實時反映當前 RPC-BFF 的最新狀態,避免了接口文檔過時的問題。
當我們想要廢棄一個 RPC 函數時,這項機制尤為重要。

如上,我們通過添加 RPC 函數的 deprecated 描述,宣布廢棄。

前端經過代碼生成同步到 RPC-BFF 最新狀態時,將能在代碼編輯器里直觀地看到廢棄的提示信息。如此可以實現流暢的前后端接口廢棄過程。
7.4 自由的函數組合
在 RPC-BFF 中,RPC 函數跟普通函數本質上是一樣的,只是它通過 Schema 定義額外攜帶了描述自身的元數據信息。我們可以像組合普通函數一樣,組合 RPC 函數。
假設我們有 updateTodo 和 removeTodo 兩個 RPC 函數,然后我們希望添加一個功能:當 updateTodo 收到的 todo.content 為空時,則 remove 該 todo。
那么,我們不必把 removeTodo 功能分別在 updateTodo 和 removeTodo 中各自實現一遍,而是在 updateTodo 中根據條件調用 removeTodo。

如上所示,在 updateTodo 中調用 removeTodo 并沒有特殊的要求,就像調用別的異步函數一樣簡單,并且對于前端發起的 updateTodo RPC 調用也沒有額外開銷,仍是一次對 updateTodo 的遠程函數調用。
7.5 可靠的接口兼容性識別與版本跟蹤
由于 RPC-BFF 的調用方在自己的前端項目中,通過 rpc.config.js 同步了 RPC-BFF 當前的接口的類型,因此它還解決了前后端之間常常遇到的接口兼容性爭議。
在以往樸素的實踐中,接口兼容往往只是后端對前端的口頭承諾,缺乏自動化的、系統化的方式去發現和識別接口兼容性,甚至往往將問題暴露在生產環境。然后前后端開始爭執判空職責的前后端邊界劃分問題。
而現在,RPC-BFF 提供了自動發現接口兼容性機制,并且是以系統性的、無爭議的方式實現的。
export class AddTodoOutput extends ObjectType {
todos = {
description: 'Todo list',
[Type]: Nullable(TodoList),
}
}如上,當后端的 addTodo 接口改變了返回值類型,從非空的 todos 變成可空的 todos,這是一種不兼容的變更。
前端同步 RPC-BFF 的接口契約后,在代碼編輯器里立即可以看到類型系統的 type-check 結果。

在不解決這個類型問題的情況下,前端項目難以通過編譯,從而避免將問題泄露到生產環境。

此外,RPC-BFF 生成的代碼也進入了前端項目的版本管理中,可以從 git diff 中,清晰地看到每一次迭代的接口契約變更記錄。更完整無誤地追溯和跟蹤前后端的接口契約歷史。
7.6 自動 merge & batch & stream 優化
如前文所描述的,RPC-BFF 需要支持自動的 merge & batch & stream 功能,以便達到更少的 HTTP 請求、更快的數據響應以及更優的 SSR 支持。
我們先來講解一下它們分別的含義。
首先講 batch,它是一種常見的優化技術,可以把一組數據請求合并為一次,往往用在相同資源的批量化請求上。這需要服務端接口提供支持,比如 getUser 接口是獲取單個用戶信息的,而 getUsers 則是獲取多個的,后者可以被視為 batch 接口。
而 merge 在這里則偏向前端概念,接口支持 batch 只是說我們可以調用一個 batch 接口獲取更多數據,但不意味著前端代碼里多個地方調用 getUser 接口,會自動 merge 到一起去調用 getUsers 接口。
merge & batch 結合起來,就可以讓前端里分散的各個調用自動合并到一次 batch 接口的請求中。
現在我們來看 stream,它跟 batch 一樣需要服務端的支持。一次 batch 接口請求的響應時間,往往取決于最慢的數據,因為服務端需要準備好所有數據后才能返回 JSON 結果;所謂的 stream 支持,則是服務端能夠提前將已獲得的數據一份份發送給前端。
某種意義上,stream 也需要前端的支持。假設接口支持 stream 可以一批批返回數據,前端卻一個 await 等待所有數據就位后才開始下一步,那么等于沒有發揮出接口流式響應的優勢。
因此,merge & batch & stream 三者的結合才能發揮出更充分的優化效果。
- 通過 merge,前端代碼里各個地方的接口調用被 batch 起來
- 通過 batch & stream 接口,一份份數據從服務端發送給前端
- 通過 RPC-BFF Client 內部數據分發,指定的數據被一份份地發送到各個前端調用點
每個前端調用點收到數據響應后都將第一時間進入后續的渲染流程,不會受到其它調用點的阻塞影響。
我們來看一個例子:

如上,為了演示方便,我用 Promise.all 將 3 次 RPC 函數調用的結果打包到一起返回,但我們仍需知道,它們其實是三個獨立的 RPC 調用,被寫到一起還是分散在其它地方調用,不影響結果。Promise.all 只是在前端匯總 promises 結果,不包含接口相關的 merge & batch & stream 等作用。

從 Network Request 面板中,我們看到了一個被標記為 Stream 的請求,它里面包含了上面 3 個 RPC 調用的所有信息。

在 Network Response 面板中,我們則看到了一個 Newline delimited JSON 響應,即用換行符分隔的streaming JSON 格式。每一個被 batch & stream 起來的 RPC 函數調用返回數據后,都將立即產生一條 JSON 結果發送給前端,每一行對應一次 RPC 調用。
7.7 自動緩存和去重
除了 merge & batch & stream 以外,自動的緩存和去重(cache & dedup)對于渲染優化也很重要。
在前端界面中,兩個組件依賴同一份接口數據的情況很常見。傳統方式是,手動去重,即兩個組件都不包含接口調用,而是 lift up 到公共的祖先級組件統一處理后通過 props/context 等方式將同一份數據傳送給這兩個組件。
這種方式的缺點是:
- 兩個組件都無法被獨立使用和復用,因為它們的數據請求邏輯都被挪出去了,內聚性被打破
- 組件優化不足。只有枝葉組件各自發起請求時,Streaming 渲染得到了更優條件。越是頂層的組件里懸停,子組件渲染越是受到阻塞
這就是為什么 React 目前致力于接管 data-fetching 層,讓開發者手動去管理缺少將系統性優化。
對于 RPC-BFF 而言,支持 cache & dedup 變得重要。

改造前面的 tryBatch 代碼,使其包含 4 次 RPC 調用,有 4 個返回值,但有 2 次的參數和函數名是重復的。

但我們的請求卻只包含了 3 次 RPC調用及其響應,其中 2 次的重復調用被合并為一次。

但并不影響每個 RPC 調用拿到它對應的 4 個調用結果。
通過這種 cache & dedup 機制,每個組件的數據請求都可以內聚于組件代碼內部,而不必被迫 lift up 到父級組件做請求托管了。
值得提醒的是,不是所有相同參數的 RPC 調用都能被緩存和去重。特別是對于 mutation 性質的請求來說,連續調用兩次相同參數的 createTodo,應當是創建兩條而非一條。

因此,RPC-BFF 支持在前端傳遞第二個 options 參數給 RPC 函數,可以關閉 cache 特性。

如上圖所示,關閉 cache 后,即便是相同的 RPC 調用,也不會被緩存和去重。
options 選項,不僅可以關閉 cache,還可以關閉 batch, stream 等特性。

如上所示,options.batch 是 cache 和 stream 的前提,我們將所有 RPC 調用的 batch 選項都關閉。

其結果是所有 RPC 函數調用退化為樸素形態,每一個 RPC 調用對應獨立的一次 HTTP 請求。
通過靈活的選項配置,我們可以按需決定 RPC-BFF 里的函數調用的優化策略。
八、總結
在這篇文章中,我們介紹了 BFF 的起源、模式和技術選型,并根據界面渲染優化需求,了解到 Streaming BFF 的重要性,同時也給出了我們當前探索的技術方向——RPC-BFF。
我們對比了開源社區的一些流行方案,并根據我們自身的場景做了分析,盡管最終采用了自研的方式,但在調研和實驗開源技術的過程中,也讓我們學習到了很多知識,使得 RPC-BFF 的設計和實現能夠吸收開源社區的技術成果。
我們最終達到了預期的技術目標,實現了:
- Validation: BFF 端可以在運行時驗證參數結構和返回值結構的合法性
- Type-infer: 支持從 Schema 中靜態類型推導出 TypeScript 類型,避免重復定義
- Introspection: RPC-BFF 服務可以通過內省請求曝露出其函數列表的契約結構
- Code-generation: 支持為調用方生成類型代碼和調用代碼,解耦項目依賴
- Merge: 前端多次 RPC 調用可以自動合并為一次 HTTP 請求
- Batch: 一次 HTTP 請求支持包含多個 RPC 調用
- Stream: 多個 RPC 調用可以流式響應,一份份發給前端,避免阻塞
- Dedup: 重復的 RPC 調用可以被去重合并
- Cache: 重復的 RPC 調用可復用緩存結果
- Type-safe: 前端可復用和對齊 BFF 端的類型
- Code as documentation: 代碼即文檔,RPC 接口的文檔描述通過代碼生成,以代碼注釋的形態直接作用于前端項目中
目前我們的 RPC-BFF 技術方案已經在內部試點項目中落地并上線平穩運行,接下來將會推廣和迭代,并持續挖掘 RPC-BFF 技術方向上的優化潛力。
以上,希望能給大家帶來幫助。