Pandas 的 Merge 函數詳解
在日常工作中,我們可能會從多個數據集中獲取數據,并且希望合并兩個或多個不同的數據集。這時就可以使用Pandas包中的Merge函數。在本文中,我們將介紹用于合并數據的三個函數merge、merge_ordered、merge_asof。
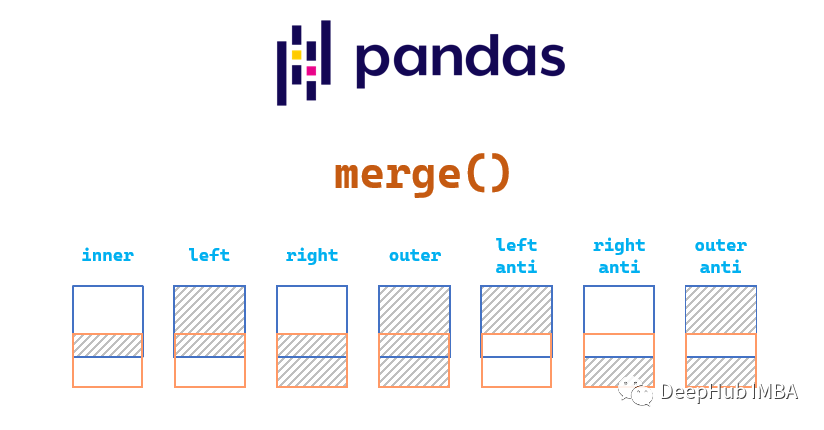
merge
merge函數是Pandas中執行基本數據集合并的首選函數。函數將根據給定的數據集索引或列組合兩個數據集。
我們使用下面試示例:
import pandas as pd customer = pd.DataFrame({'cust_id': [1,2,3,4,5],
'cust_name': ['Maria', 'Fran', 'Dominique', 'Elsa', 'Charles'], 'country':
['German', 'Spain', 'Japan', 'Poland', 'Argentina']}) order =
pd.DataFrame({'order_id': [200, 201,202,203,204], 'cust_id':[1,3,3,4,2],
'order_date': ['2014-07-05', '2014-07-06', '2014-07-07', '2014-07-07',
'2014-07-08'], 'order_value': [10.1, 20.5, 18.7, 19.1, 13.5]})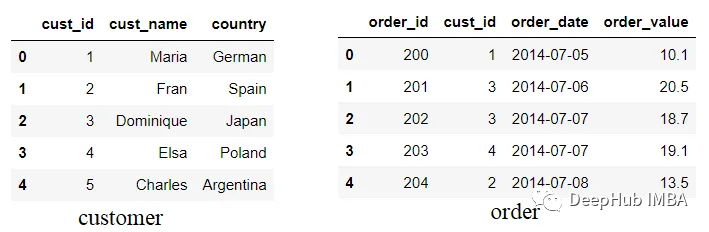
我們嘗試模擬兩個不同的數據集:客戶和訂單數據,其中cust_id列同時存在于兩個DataFrame中。
pd.merge(customer, order)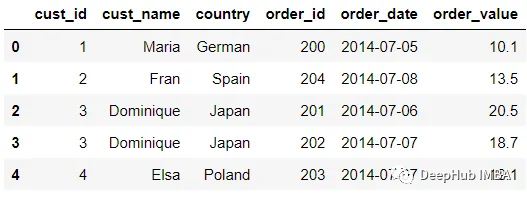
默認情況下,merge函數是這樣工作的:
將按列合并,并嘗試從兩個數據集中找到公共列,使用來自兩個DataFrame(內連接)的列值之間的交集。
列和索引合并
在上面合并的數據集中,merge函數在cust_id列上連接兩個數據集,因為它是唯一的公共列。我們也可以指定要在兩個數據集上連接的列名。
如果兩個列的名稱都存在于兩個DataFrame中,則可以使用參數on。
pd.merge(customer, order, on = 'cust_id')結果與前面的示例類似,因為cust_id是唯一的公共列。但是如果兩個DataFrame都包含兩個或多個具有相同名稱的列,則這個參數就很重要。
我們來創建一個包含兩個相似列的數據。
customer = pd.DataFrame({'cust_id': [1,2,3,4,5], 'cust_name': ['Maria',
'Fran', 'Dominique', 'Elsa', 'Charles'], 'country': ['German', 'Spain', 'Japan',
'Poland', 'Argentina']}) order = pd.DataFrame({'order_id': [200,
201,202,203,204], 'cust_id':[1,3,3,4,2], 'order_date': ['2014-07-05',
'2014-07-06', '2014-07-07', '2014-07-07', '2014-07-08'], 'order_value': [10.1,
20.5, 18.7, 19.1, 13.5], 'country' : ['German', 'Indonesia', 'Armenia',
'Singapore', 'Japan'] })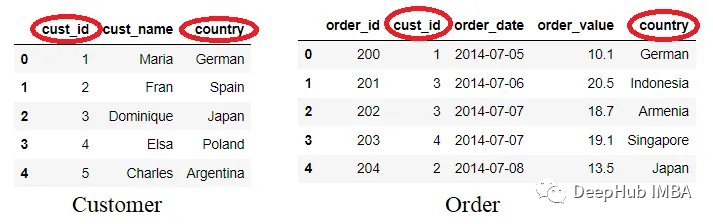
數據集現在包含兩個名稱相似的列:cust_id和country。讓我們看看如果使用默認方法合并兩個DataFrame會發生什么。
pd.merge(customer, order)
只剩下一行了,這是因為merge函數將使用與鍵名相同的所有列來合并兩個數據集。所以現在是通過cust_id和country中找到的相同值來實現合并的。
還有一個問題,我們指定一個列后,其他的重復列(這里是country),現在存在country_x和country_y列。這兩列是來自各自數據集的國家列。country_x來自Customer數據集,country_y來自Order數據集。
為了幫助區分合并過程中相同列名的結果,我們可以將一個元組對象傳遞給suffix參數。
pd.merge(customer, order, on ='cust_id', suffixes = ('_customer',
'_order'))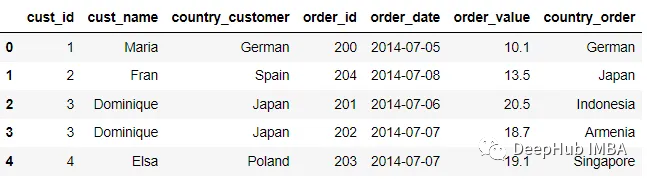
使用suffix參數,可以讓我們避免混淆,或者在合并前我們直接將列改名
customer = customer.rename(columns = {'country':'customer_country'}) order =
order.rename(columns = {'country':'delivery_country'})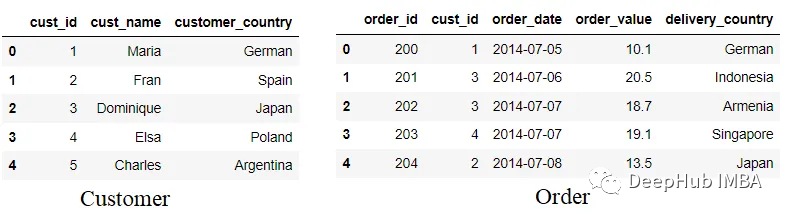
這樣就不會造成混淆了。
然是如果我們要合并的列名在兩個數據集不同時,on參數就沒有效果了,這時就需要使用left_on和right_on參數,我們這里以剛剛改名的country列為例:
pd.merge(customer, order, left_on = 'customer_country', right_on =
'delivery_country', suffixes = ('_customer', '_order'))
在上面的代碼中,我們將左側數據集(Customer)上想要合并的列傳遞給left_on參數,將右側數據集(Order)的列名傳遞給right_on參數。
left_on和right_on參數是串聯工作的,因此我們不能在left_on參數中傳遞列名,而將right_on參數保留為空。
我們也可以使用left_index和right_index來替換left_on和right_on參數。right_index和left_index參數控制merge函數,以根據索引而不是列連接數據集。
pd.merge(customer, order, left_index = True, right_on = 'cust_id', suffixes =
('_customer', '_order'))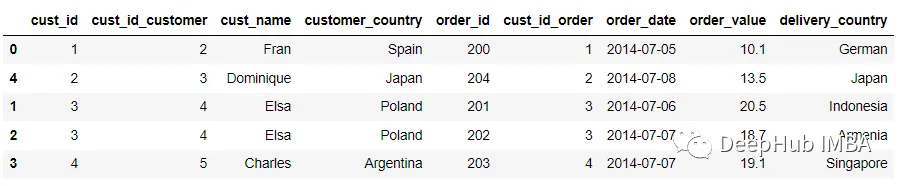
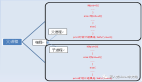
在上面的代碼將True值傳遞給left_index參數,表示希望使用左側數據集上的索引作為連接鍵。合并過程類似于下圖。
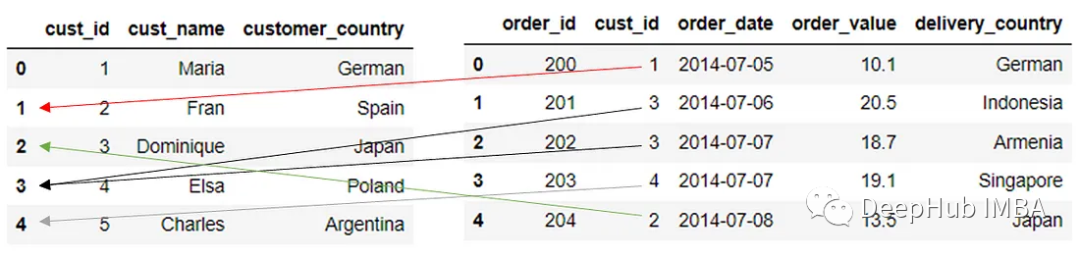
當我們按索引和列合并時,DataFrame結果將由于合并(匹配的索引)會增加一個額外的列。
合并類型介紹
默認情況下,當我們合并數據集時,merge函數將執行Inner Join。在Inner Join中,根據鍵之間的交集選擇行。匹配在兩個鍵列或索引中找到的相同值。
下圖顯示了Inner Join圖,其中只選擇了Customer和Order數據集上的列和/或索引之間匹配的值。
pd.merge(customer, order, left_on = 'customer_country', right_on =
'delivery_country', suffixes = ('_customer', '_order'), how = 'inner')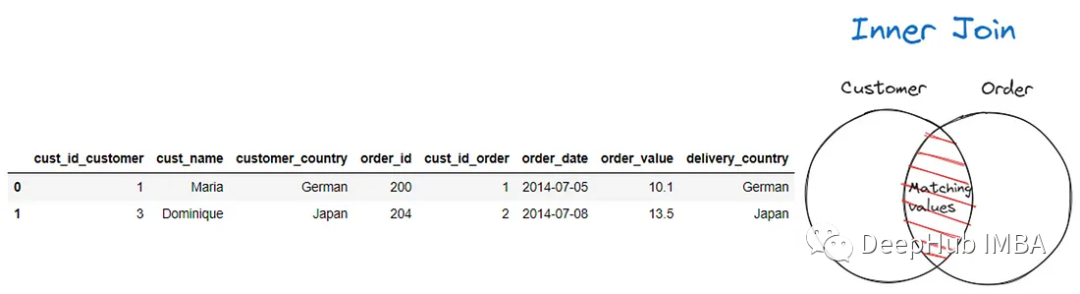
我們也可以使用左連接和右連接來保留想要的DataFrame。
pd.merge(customer, order, left_on = 'customer_country', right_on =
'delivery_country', suffixes = ('_customer', '_order'), how = 'left', indicator
= True)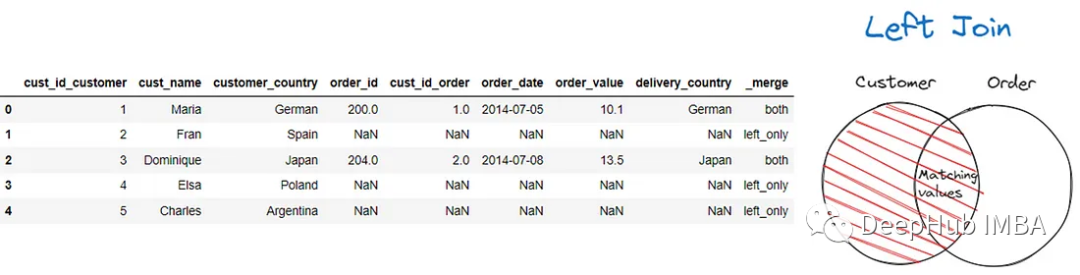
上面的代碼,所有與訂單數據值不匹配的客戶數據值都用NaN值填充。
indicator=True參數,將創建_merge列。在上面的結果中,可以看到兩個值都表明該行來自DataFrame和left_only的交集,其中該行來自第一個DataFrame(左側)。
如果要執行右連接,可以使用以下代碼。
pd.merge(customer, order, left_on = 'customer_country', right_on =
'delivery_country', suffixes = ('_customer', '_order'), how = 'right', indicator
= True)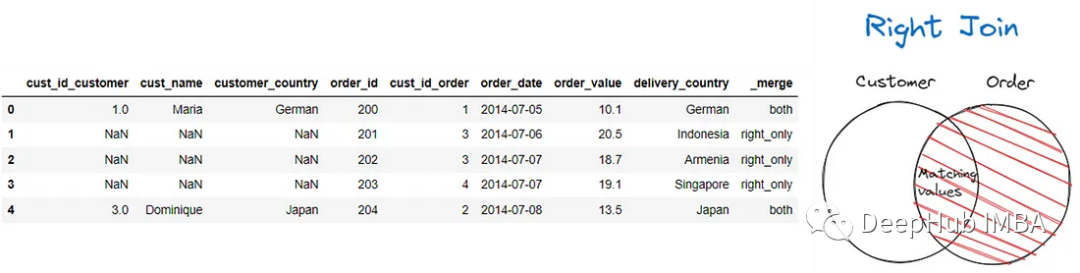
還可以在合并過程中使用外連接來保留兩個DataFrame。我們可以把外連接看作是同時進行的左連接和右連接。
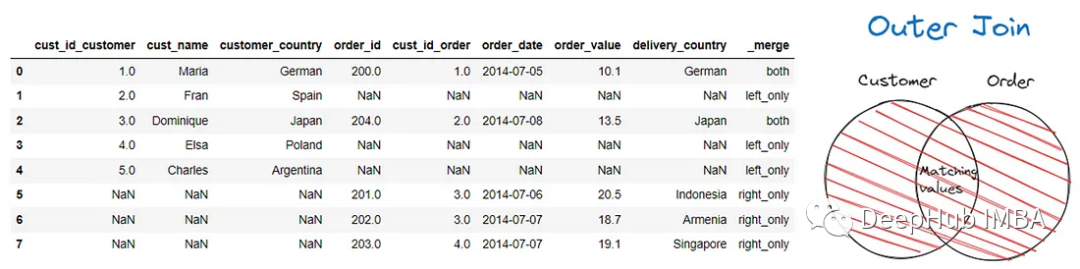
最后就是交叉連接,將合并兩個DataFrame之間的每個數據行。
讓我們用下面的代碼嘗試交叉連接。
pd.merge(customer, order, how = 'cross', suffixes = ('_customer',
'_order'))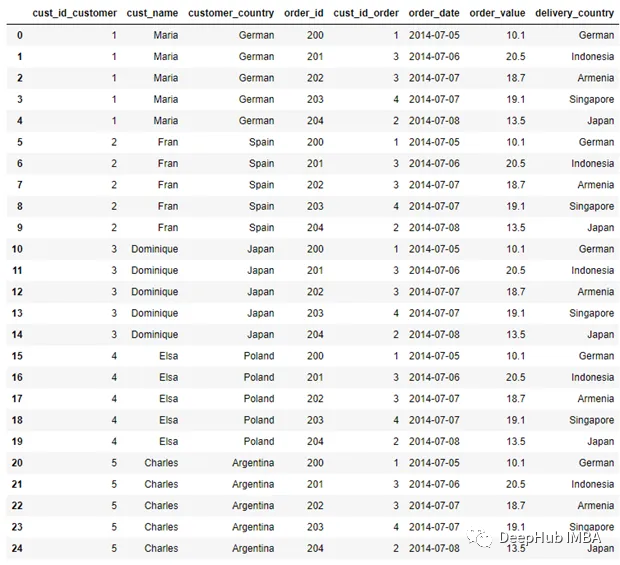
DataFrame將Customer數據中的每一行都與Order數據結合起來。
merge_ordered
在 Pandas 中,merge_ordered 是一種用于合并有序數據的函數。它類似于 merge 函數,但適用于處理時間序列數據或其他有序數據。merge_ordered 在合并時會保留原始數據的順序,并且支持對缺失值進行處理。
pd.merge_ordered(customer, order)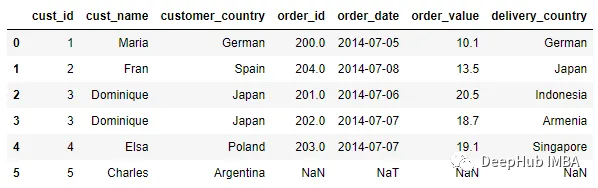
默認情況下,merge_ordered將執行Outer Join并根據連接鍵對數據進行排序。我們也可以像更改合并類型一樣調整how參數。
merge_ordered是為有序數據(如時間序列)開發的。所以我們創建另一個名為Delivery的數據集來模擬時間序列數據合并。
order = pd.DataFrame({'order_id': [200, 201,202,203,204],
'cust_id':[1,3,3,4,2], 'order_date': ['2014-07-05', '2014-07-06', '2014-07-07',
'2014-07-07', '2014-07-08'], 'order_value': [10.1, 20.5, 18.7, 19.1, 13.5],
'delivery_country' : ['German', 'Indonesia', 'Armenia', 'Singapore', 'Japan'] })
delivery = pd.DataFrame({'delivery_date': ['2014-07-06', '2014-07-08',
'2014-07-09', '2014-07-10'], 'product': ['Apple', 'Apple', 'Orange',
'Orange']})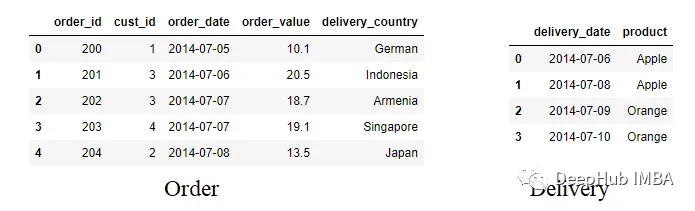
讓我們假設delivery_date是投遞時間,它包含與Order數據集中的order_date一起使用。另外就是我們還需要將日期列轉換為datetime對象。
order['order_date'] = pd.to_datetime(order['order_date'])
delivery['delivery_date'] = pd.to_datetime(delivery['delivery_date'])讓我們嘗試按日期列合并兩個數據集。
pd.merge_ordered(order, delivery, left_on = 'order_date', right_on =
'delivery_date')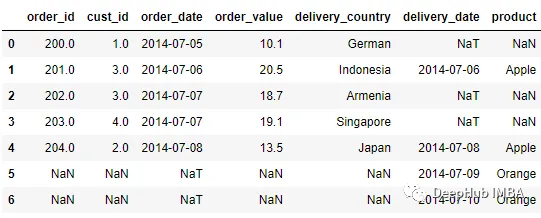
合并的DataFrame是按連接鍵排序的Order和Delivery數據集的Outer Join結果。
由于是外連接,一些數據點是空的。對于merge_ordered,有一個選項可以通過使用fill_method參數來填充缺失的值。
pd.merge_ordered(order, delivery, left_on = 'order_date', right_on =
'delivery_date', fill_method = 'ffill' )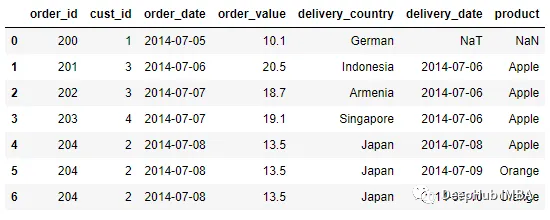
在上面的DataFrame中執行前向填充方法來計算缺失的值。
最后merge_ordered函數還可以基于數據集列執行DataFrame分組,并將它們一塊一塊地合并到另一個數據集。
pd.merge_ordered(order, delivery, left_on = 'order_date', right_on =
'delivery_date', right_by = 'product')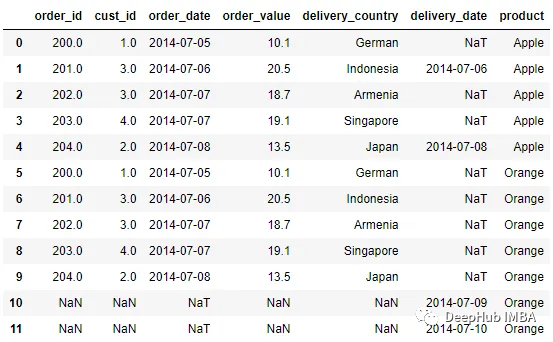
在上面的代碼中將product列傳遞給right_by參數,這樣product列中的每個值都映射到每個可用行,并且用于對數據進行分組的同一DataFrame中不存在的數據用NaN填充。
為了進一步理解,我們在合并之前添加日期來對數據進行分組。
pd.merge_ordered(order, delivery, left_on = 'order_date', right_on =
'delivery_date', right_by = ['delivery_date','product'])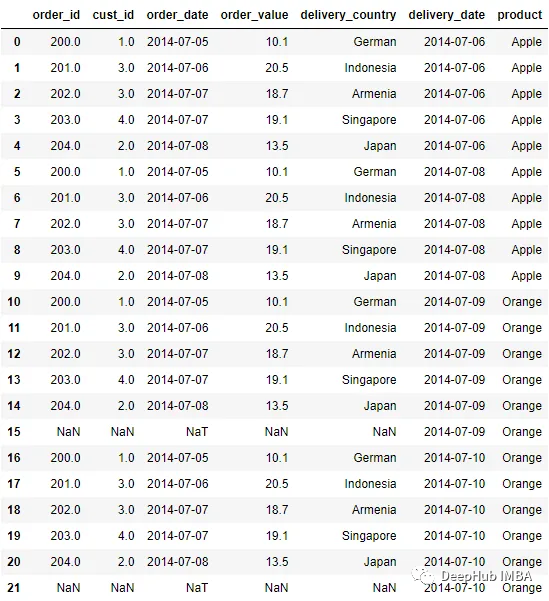
在上面的合并過程中,我們最終得到了4個不同的組:
['2014–07–06', 'Apple'], ['2014–07–08', 'Apple'], ['2014–07–09', 'Orange'],
['2014–07–10', 'Orange']該組基于所使用列中的現有行,因此它不是所有惟一值的組合。例如,沒有[' 2014-07-09 ','Apple']組,因為此數據不存在。
在上面的DataFrame中可以看到Order數據集中的每一行都映射到Delivery數據集中的組。
merge_asof
merge_asof 是一種用于按照最近的關鍵列值合并兩個數據集的函數。這個函數用于處理時間序列數據或其他有序數據,并且可以根據指定的列或索引按照最接近的值進行合并。
order = pd.DataFrame({'order_id': [199, 200, 201,202,203,204],
'cust_id':[1,1,3,3,4,2], 'order_date': ['2014-07-01', '2014-07-05',
'2014-07-06', '2014-07-07', '2014-07-07', '2014-07-08'], 'order_value': [11,
10.1, 20.5, 18.7, 19.1, 13.5], 'delivery_country' : ['Poland', 'German',
'Indonesia', 'Armenia', 'Singapore', 'Japan'] }) delivery =
pd.DataFrame({'delivery_date': ['2014-07-06', '2014-07-08', '2014-07-09',
'2014-07-10'], 'product': ['Apple', 'Apple', 'Orange', 'Orange']})使用merge_asof函數的一個注意事項是,必須按鍵對兩個DataFrame進行排序。這是因為它將根據鍵的距離合并鍵,而未排序的DataFrame將拋出錯誤消息。
使用merge_asof類似于其他的合并操作,需要傳遞想要合并的DataFrame及其鍵名稱。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date')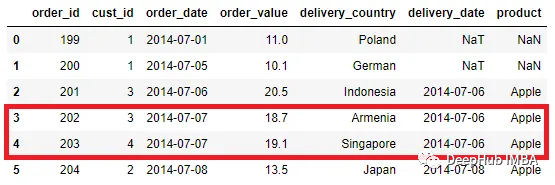
我們可以看到一些數據被合并了,但不是精確的值匹配。比如在第三行和第四行,order_date值為“2014-07-07”,但delivery_date為“2014-07-06”。
使用merge_asof會丟失數據。默認情況下它查找最接近匹配的已排序的鍵。在上面的代碼中,與delivery_date不完全匹配的order_date試圖在delivery_date列中找到與order_date值較小或相等的鍵。
delivery_date中小于等于order_date' 2014-07-07 '的值為' 2014-07-06 '。這就是為什么合并發生在這個鍵上。而order_date ' 2017-04-01 '和' 2017-04-05 '根本沒有匹配,因為在delivery_date中沒有小于或等于它們的值的值。
如果在正確的DataFrame中有多個重復的鍵,則只有最后一行用于合并過程。例如將更改delivery_date數據,使其具有多個不同產品的“2014-07-06”值。
delivery = pd.DataFrame({'delivery_date': ['2014-07-06', '2014-07-06',
'2014-07-08', '2014-07-10'], 'product': ['Apple', 'Orange', 'Apple',
'Orange']})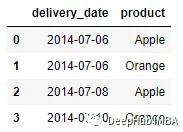
然后我們將執行與之前相同的合并過程。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date')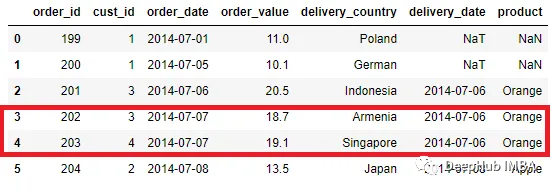
可以看到,合并過程對Orange產品而不是Apple產品使用delivery_date ,盡管兩者具有相同的鍵值。另外具有精確匹配的鍵也會受到影響,它們會選擇最后一行鍵。
可以通過設置allow_exact_matches=False來關閉精確匹配合并。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date', allow_exact_matches = False)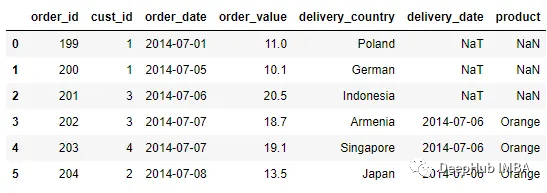
通過使用direction 參數來改變查找鍵的策略。例如使用向前策略:
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date', direction = 'forward')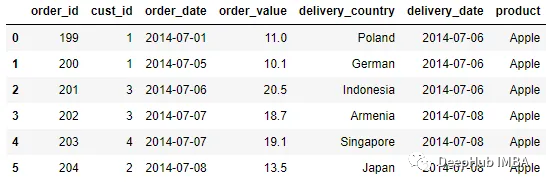
向前策略與向后策略類似,不同之處在于該函數將通過查看大于或等于正確DataFrame鍵的值來嘗試合并。
另一個可以使用的策略是就近策略。在這個策略中使用向后或向前策略;取絕對距離中最近的那個。如果有多個最接近的鍵或精確匹配,則使用向后策略。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date', direction = 'nearest')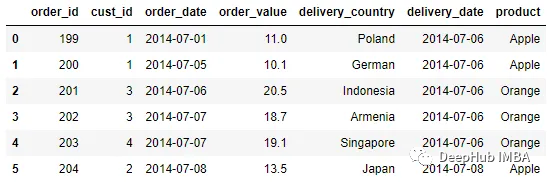
最后還可以通過使用tolerance 參數來控制鍵之間的距離。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date', direction = 'forward', tolerance = pd.Timedelta(1, 'd'))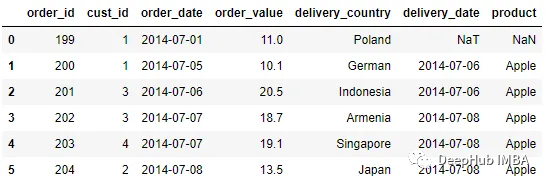
在上面的示例中,只有第一行包含缺失值。這是因為order_date第一行與最近的日期delivery_date之間的距離大于一天。第二行成功合并,因為只差一天。
總結
Pandas函數提供了Merge函數可以輕松的幫助我們合并數據,而merge_ordered函數和merge_asof可以幫助我們進行更加定制化的合并工作,雖然這兩個函數可能并不常見,但是它們的確在一些特殊的需求上非常的好用。