一個(gè)簡(jiǎn)單模型就讓ChatGLM性能大幅提升
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
引言
自大語(yǔ)言模型 (LLM) 成為熱點(diǎn)話題以來(lái),涌現(xiàn)了一大批中文大語(yǔ)言模型并在優(yōu)化平臺(tái)中得到了積極部署。ChatGLM 正是廣受好評(píng)的主流中文大語(yǔ)言模型之一。
然而,由于 ChatGLM 模型尚未成為 Transformer 生態(tài)的原生模型,因此,官方 optimum 擴(kuò)展庫(kù)對(duì)其仍缺乏支持。
本文提供了一種使用 OpenVINO? opset 重構(gòu)該模型架構(gòu)的便捷方法。
該方案包含專為 ChatGLM 定制的優(yōu)化節(jié)點(diǎn),且這些節(jié)點(diǎn)都利用英特爾? 高級(jí)矩陣擴(kuò)展(Intel? Advanced Matrix Extensions,縮寫為英特爾? AMX)內(nèi)聯(lián)和 MHA(Multi-Head Attention,多頭注意力)融合實(shí)現(xiàn)了高度優(yōu)化。
請(qǐng)注意,本文僅介紹了通過(guò)為 ChatGLM 創(chuàng)建 OpenVINO? stateful模型實(shí)現(xiàn)優(yōu)化的解決方案。本方案受平臺(tái)限制,必須使用內(nèi)置了英特爾? AMX 的第四代英特爾? 至強(qiáng)? 可擴(kuò)展處理器[1](代號(hào) Sapphire Rapids)。筆者不承諾對(duì)該解決方案進(jìn)行任何維護(hù)。
ChatGLM 模型簡(jiǎn)介
筆者在查看 ChatGLM 原始模型的源碼[2]時(shí),發(fā)現(xiàn) ChatGLM 與 Optimum ModelForCasualML并不兼容,而是定義了新的類 ChatGLMForConditionalGeneration[3]。
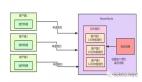
該模型的流水線回路包含 3 個(gè)主要模塊(Embedding、GLMBlock 層[4]和 lm_logits),結(jié)構(gòu)如下:

△圖1 ChatGLM 模型結(jié)構(gòu)
如上圖所示,整個(gè)流水線實(shí)際要求模型有兩個(gè)不同的執(zhí)行圖,使用輸入提示符進(jìn)行首次推理時(shí)不需要 KV 緩存作為 GLMBlock 層的輸入。從第二次迭代開始,QKV 注意力機(jī)制的上一次結(jié)果將成為當(dāng)前一輪模型推理的輸入。
隨著生成符的長(zhǎng)度不斷增加,在流水線推理過(guò)程中,模型輸入和輸出之間將存留大量的大型內(nèi)存副本。
以 ChatGLM6b 默認(rèn)模型配置[5]為示例,輸入和輸出陣列之間的內(nèi)存副本類似于以下偽代碼,其內(nèi)存拷貝的開銷由模型的參數(shù) hidden_size 以及迭代的次數(shù)決定:
while(eos_token_id || max_seq_len){
memcpy(model_inp, model_outp, num_layer*2*sizeof(model_outp)* hidden_size)
model_outp.push_back(gen_token)
}△代碼若顯示不全,可左右滑動(dòng)因此,本文要解決的兩大關(guān)鍵問(wèn)題是:
- 如何優(yōu)化模型推理流水線來(lái)消除模型輸入和輸出之間的內(nèi)存副本
- 如何通過(guò)重新設(shè)計(jì)執(zhí)行圖來(lái)優(yōu)化 GLMBlock 模塊
構(gòu)建 OpenVINO? stateful 模型實(shí)現(xiàn)顯著優(yōu)化
首先,需要分析 GLMBlock 層的結(jié)構(gòu),嘗試封裝一個(gè)類并按以下工作流來(lái)調(diào)用 OpenVINO? opset。接著,將圖形數(shù)據(jù)序列化為 IR 模型 (.xml, .bin)。

△圖2 ChatGLM構(gòu)建OpenVINO? stateful模型
關(guān)于如何構(gòu)建 OpenVINO? stateful模型,以及如何使用OpenVINO? 提供的模型創(chuàng)建樣本,在 opset 構(gòu)建模型,可參考文末文檔。
ChatGLM 的自定義注意力機(jī)制是本文所關(guān)注和優(yōu)化的部分。
主要思路是:構(gòu)建全局上下文結(jié)構(gòu)體,用于在模型內(nèi)部追加并保存每一輪迭代后的 pastKV 的結(jié)果,這樣減少了 pastKV 作為模型輸入輸出的拷貝開銷,同時(shí)使用內(nèi)聯(lián)優(yōu)化以實(shí)現(xiàn) Rotary Embedding 和多頭注意力機(jī)制 (Multi-Head Attentions)。
英特爾? AMX 是內(nèi)置在第四代英特爾? 至強(qiáng)? 可擴(kuò)展處理器中的矩陣乘法加速器,能夠更快速地處理 bf16 或 int8 數(shù)據(jù)類型的矩陣乘加運(yùn)算,通過(guò)加速?gòu)埩刻幚恚@著提高推理和訓(xùn)練性能。借助英特爾? AMX 內(nèi)聯(lián)指令(用于加速計(jì)算的單指令多操作),實(shí)現(xiàn)了對(duì) ChatGLM 模型中 Attention,Rotary Embedding 等算子的高度優(yōu)化,并且使用 bf16 指令進(jìn)行乘加操作,在保證浮點(diǎn)指數(shù)位精度的同時(shí)提高運(yùn)算效率。
與此同時(shí),本方案還使用 int8 精度來(lái)壓縮全連接層的權(quán)重,在實(shí)時(shí)計(jì)算中將使用bf16進(jìn)行計(jì)算。因此,無(wú)需通過(guò)訓(xùn)練后量化 (PTQ) 或量化感知訓(xùn)練 (QAT) 對(duì)模型進(jìn)行低精度處理。模型壓縮方法可以降低模型存儲(chǔ)空間,減少內(nèi)存帶寬的負(fù)載,因?yàn)橛?jì)算仍然使用浮點(diǎn),不會(huì)造成溢出,不會(huì)對(duì)模型精度造成損失。
為 ChatGLM 創(chuàng)建 OpenVINO? stateful模型
請(qǐng)依照下方示例配置軟硬件環(huán)境,并按照以下步驟優(yōu)化 ChatGLM:
硬件要求
第四代英特爾? 至強(qiáng)? 可擴(kuò)展處理器(代號(hào) Sapphire Rapids)或其后續(xù)的、仍內(nèi)置英特爾? AMX 的產(chǎn)品
軟件驗(yàn)證環(huán)境
Ubuntu 22.04.1 LTS
面向 OpenVINO? Runtime Python API 的 Python 3.10.11
用于構(gòu)建 OpenVINO? Runtime 的 GCC 11.3.0
cmake 3.26.4
構(gòu)建 OpenVINO? 源碼
- 安裝系統(tǒng)依賴并設(shè)置環(huán)境
- 創(chuàng)建并啟用 Python 虛擬環(huán)境
$ conda create -n ov_py310 pythnotallow=3.10 -y
$ conda activate ov_py310
△代碼若顯示不全,可左右滑動(dòng)- 安裝 Python 依賴
$ pip install protobuf transformers==4.30.2 cpm_kernels torch>=2.0 sentencepiece pandas△代碼若顯示不全,可左右滑動(dòng)- 使用 GCC 11.3.0 編譯 OpenVINO?
- 克隆 OpenVINO? 并升級(jí)子模塊
$ git clone https://github.com/luo-cheng2021/openvino.git -b luocheng/chatglm_custom
$ cd openvino && git submodule update --init --recursive
△代碼若顯示不全,可左右滑動(dòng)- 安裝 Python 環(huán)境依賴,以構(gòu)建 Python Wheel
$ python -m pip install -U pip
$ python -m pip install -r ./src/bindings/python/src/compatibility/openvino/requirements-dev.txt
$ python -m pip install -r ./src/bindings/python/wheel/requirements-dev.txt
△代碼若顯示不全,可左右滑動(dòng)- 創(chuàng)建編譯目錄
$ mkdir build && cd build
△代碼若顯示不全,可左右滑動(dòng)- 使用 CMake 編譯 OpenVINO?
$ cmake .. -DENABLE_LLMDNN=ON \
-DBUILD_PYTHON_TESTS=ON \
-DENABLE_CPU_DEBUG_CAPS=OFF \
-DENABLE_DEBUG_CAPS=OFF \
-DCMAKE_BUILD_TYPE=Release \
-DENABLE_INTEL_MYRIAD_COMMON=OFF \
-DENABLE_INTEL_GNA=OFF \
-DENABLE_OPENCV=OFF \
-DENABLE_CPPLINT=ON \
-DENABLE_CPPLINT_REPORT=OFF \
-DENABLE_NCC_STYLE=OFF \
-DENABLE_TESTS=ON \
-DENABLE_OV_CORE_UNIT_TESTS=OFF \
-DENABLE_INTEL_CPU=ON \
-DENABLE_INTEL_GPU=OFF \
-DENABLE_AUTO=OFF \
-DENABLE_AUTO_BATCH=OFF \
-DENABLE_MULTI=OFF \
-DENABLE_HETERO=OFF \
-DENABLE_INTEL_GNA=OFF \
-DENABLE_PROFILING_ITT=ON\
-DENABLE_SAMPLES=ON \
-DENABLE_PYTHON=ON \
-DENABLE_TEMPLATE=OFF \
-DENABLE_OV_ONNX_FRONTEND=OFF \
-DENABLE_OV_PADDLE_FRONTEND=OFF \
-DENABLE_OV_PYTORCH_FRONTEND=OFF \
-DENABLE_OV_TF_FRONTEND=OFF \
-DENABLE_OPENVINO_DEBUG=OFF \
-DENABLE_CPU_DEBUG_CAPS=ON \
-DCMAKE_INSTALL_PREFIX=`pwd`/install \
-DCMAKE_INSTALL_RPATH=`pwd`/install/runtime/3rdparty/tbb/lib:`pwd`/install/runtime/3rdparty/hddl/lib:`pwd`/install/runtime/lib/intel64 \
-Dgflags_Dir=`pwd`/../thirdparty/gflags/gflags/cmake
$ make --jobs=$(nproc --all)
$ make install
△代碼若顯示不全,可左右滑動(dòng)- 安裝針對(duì) OpenVINO? Runtime 和 openvino-dev 工具構(gòu)建好的 Python Wheel
$ pip install ./install/tools/openvino*.whl
△代碼若顯示不全,可左右滑動(dòng)- 檢查系統(tǒng) GCC 版本和 Conda Runtime GCC 版本。如下所示,如果系統(tǒng) GCC 版本高于 Conda GCC 版本,請(qǐng)升級(jí) Conda GCC 至相同版本,以滿足 OpenVINO? Runtime 的需求。(可選)
##check system (OpenVINO compiling env) gcc version
$ gcc --version
gcc (Ubuntu 11.3.0-1ubuntu1~22.04.1) 11.3.0##check conda python (runtime env for OpenVINO later) gcc version
$ python
Python 3.10.11 (main, May 16 2023, 00:28:57) [GCC 11.2.0] on linux##If sys gcc ver > conda gcc ver, upgrade conda gcc ver -> sys gcc ver
$ conda install -c conda-forge gcc=11.3.0
△代碼若顯示不全,可左右滑動(dòng)- 將 PyTorch 模型轉(zhuǎn)為 OpenVINO? IR
$ cd ..
$ python tools/gpt/gen_chatglm.py /path/to/pytorch/model /path/to/ov/IR
△代碼若顯示不全,可左右滑動(dòng)使用 OpenVINO? Runtime API 為 ChatGLM 構(gòu)建推理流水線
本文提供了使用 Transformer 和 OpenVINO? Runtime API 構(gòu)建推理流水線的樣本。首先,在 test_chatglm.py 中,創(chuàng)建一個(gè)由 transformers.PreTrainedModel 衍生的新類。
然后,通過(guò)使用 OpenVINO? Runtime Python API 構(gòu)建模型推理流水線來(lái)更新轉(zhuǎn)發(fā)函數(shù)。其他成員函數(shù)則遷移自 modeling_chatglm.py [2]的 ChatGLMForConditionalGeneration。
如此一來(lái),即可確保輸入準(zhǔn)備工作、set_random_seed、分詞器/連接器 (tokenizer/detokenizer) 以及余下的流水線操作能夠與原始模型的源碼保持一致。
如需啟用 int8 權(quán)重壓縮,只需設(shè)置簡(jiǎn)單的環(huán)境變量 USE_INT8_WEIGHT=1。這是因?yàn)樵谀P蜕呻A段,已使用 int8 對(duì)全連接層的權(quán)重進(jìn)行了壓縮,因此模型可在之后的運(yùn)行過(guò)程中直接使用 int8 權(quán)重進(jìn)行推理,從而免除了通過(guò)框架或量化工具壓縮模型的步驟。
請(qǐng)按照以下步驟使用 OpenVINO? Runtime 流水線測(cè)試 ChatGLM:
- 運(yùn)行 bf16 模型
$ python3 tools/gpt/test_chatglm.py /path/to/pytorch/model /path/to/ov/IR --use=ov△代碼若顯示不全,可左右滑動(dòng)- 運(yùn)行 int8 模型
$ USE_INT8_WEIGHT=1 python test_chatglm.py /path/to/pytorch/model /path/to/ov/IR --use=ov
△代碼若顯示不全,可左右滑動(dòng)權(quán)重壓縮:降低內(nèi)存帶寬使用率,提升推理速度
本文采用了 Vtune 對(duì)模型權(quán)重?cái)?shù)值精度分別為 bf16 和 int8 的內(nèi)存帶寬使用率(圖 3 和圖 4)以及 CPI 率進(jìn)行了性能對(duì)比分析(表 1)。結(jié)果發(fā)現(xiàn):當(dāng)模型權(quán)重?cái)?shù)值精度壓縮至 int8 時(shí),可同時(shí)降低內(nèi)存帶寬使用率和 CPI 率。
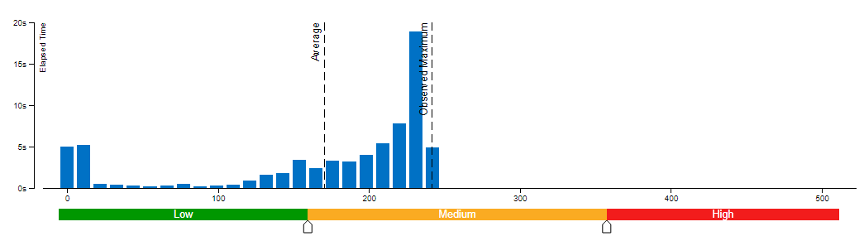
圖3 模型權(quán)重?cái)?shù)值精度為 bf16 時(shí)的內(nèi)存帶寬使用率
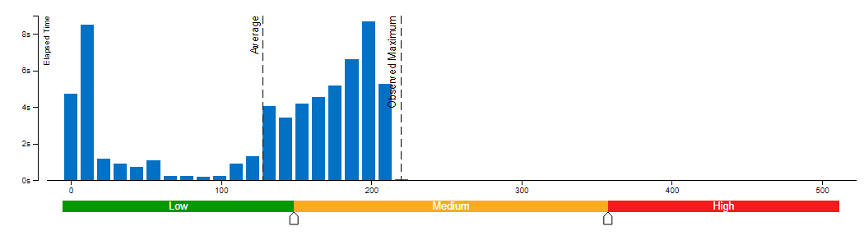
圖4 模型權(quán)重?cái)?shù)值精度為 int8 時(shí)的內(nèi)存帶寬使用率
 表1 采用不同模型權(quán)重?cái)?shù)值精度時(shí)的 CPI 率
表1 采用不同模型權(quán)重?cái)?shù)值精度時(shí)的 CPI 率
每條指令消耗的時(shí)鐘周期 (Clockticks per Instruction Retired, CPI) 事件率,也稱為“平均指令周期數(shù) (Cycles per Instruction)”,是基于硬件事件抽樣收集的基礎(chǔ)性能指標(biāo)之一,在抽樣模式下也稱為“性能監(jiān)控計(jì)數(shù)器 (PMC) 分析”。
該比率計(jì)算方式為:用處于非停機(jī)狀態(tài)的處理器時(shí)鐘周期數(shù) (Clockticks) 除以已消耗指令數(shù)。每個(gè)處理器用于計(jì)算時(shí)鐘周期數(shù)和已消耗指令數(shù)的確切事件可能并不相同,但 VTune Profiler 可辨別和使用正確的數(shù)量。
CPI < 1 時(shí),通常為采用指令密集型代碼的應(yīng)用,而 CPI > 1 則可能是停滯時(shí)鐘周期密集型應(yīng)用,也可能是內(nèi)存密集型應(yīng)用。
由此,我們可以得出結(jié)論,類似 chatGLM 等語(yǔ)言模型對(duì)內(nèi)存帶寬的要求非常高,性能往往受到內(nèi)存操作或帶寬的限制。
很多場(chǎng)景下,消除內(nèi)存操作的負(fù)載,性能會(huì)因此獲得大幅收益。在優(yōu)化此類模型時(shí),如何在不影響精度的同時(shí)對(duì)模型進(jìn)行壓縮或輕量化處理是一項(xiàng)不可或缺的技巧。除此之外,在異構(gòu)平臺(tái)和框架上進(jìn)行部署,還涉及到減少內(nèi)存/設(shè)備存儲(chǔ)之間的數(shù)據(jù)搬運(yùn)等優(yōu)化思路。
因此,在壓縮模型的同時(shí),還需要考慮對(duì)原始 pytorch 模型推理 forward/generates 等函數(shù)流水線的優(yōu)化,而 OpenVINO? 在優(yōu)化模型自身的同時(shí),還將流水線的優(yōu)化思路體現(xiàn)在修改模型結(jié)構(gòu)中(將 KV cache保存在模型內(nèi)部),通過(guò)優(yōu)化 Optimum-intel 等框架的流水線,減少內(nèi)存拷貝和數(shù)據(jù)搬運(yùn)。
結(jié)論
筆者根據(jù)上述方法重新設(shè)計(jì)執(zhí)行圖并優(yōu)化了 GLMBlock,消除了 ChatGLM 模型輸入和輸出之間的內(nèi)存副本,且模型運(yùn)行高效。
隨著 OpenVINO? 的不斷升級(jí),本方案的優(yōu)化工作也將得到推廣并集成至正式發(fā)布的版本中。這將有助于擴(kuò)展更多的大語(yǔ)言模型用例。敬請(qǐng)參考 OpenVINO? 官方版本[6]和 Optimum-intel OpenVINO? 后端[7],獲取有關(guān)大語(yǔ)言模型的官方高效支持。
了解更多內(nèi)容,請(qǐng)點(diǎn)擊文末【閱讀原文】。
作者簡(jiǎn)介:
英特爾? OpenVINO? 開發(fā)工具客戶支持工程師趙楨和鄒文藝,英特爾? OpenVINO? 開發(fā)工具 AI 框架工程師羅成和李亭騫,都在從事 AI 軟件工具開發(fā)與優(yōu)化工作。
OpenVINO? stateful模型構(gòu)建:https://docs.openvino.ai/2022.3/openvino_docs_OV_UG_network_state_intro.html
通過(guò) opset 構(gòu)建模型:https://github.com/openvinotoolkit/openvino/blob/master/samples/cpp/model_creation_sample/main.cpp